BrainDreamer: Reasoning-Coherent and Controllable Image Generation from EEG Brain Signals via Language Guidance

0

Sign in to get full access
Overview
- BrainDreamer: a system that generates images from brain signals and language guidance
- Uses EEG brain signals and language prompts to create coherent and controllable images
- Designed to enable interactive and intuitive image creation from thoughts and imagination
Plain English Explanation
BrainDreamer is a system that allows people to generate images directly from their brain signals and language prompts. It works by capturing the user's brain activity through an EEG (electroencephalogram) device and then using that information, along with natural language instructions, to create coherent and customizable images.
The key idea is to bridge the gap between a person's thoughts, imagination, and the ability to visually express those ideas. By combining brain signals and language guidance, BrainDreamer enables an interactive and intuitive image creation process. Users can simply think about an image and provide language-based directions, and the system will generate a corresponding visual representation.
This approach has the potential to revolutionize how we interact with and create digital content, moving beyond traditional input methods like keyboards and mice. By tapping directly into the user's neural patterns and cognition, BrainDreamer opens up new possibilities for creative expression, problem-solving, and communication.
Technical Explanation
BrainDreamer utilizes a unique architecture that combines EEG-based neural representations with language-guided image generation. The system first encodes the user's brain signals into a latent representation, which captures the cognitive and perceptual aspects of their thought process.
This latent representation is then fed into a language-guided image generation model, which uses natural language prompts to produce the corresponding visual output. The language guidance helps ensure the generated images are coherent, relevant, and adhere to the user's intended concept.
The researchers conducted experiments to evaluate the effectiveness of BrainDreamer, demonstrating its ability to generate high-quality, reasoning-coherent images from EEG signals and language prompts. The results showcase the potential of this approach to enable intuitive and expressive visual creation directly from a person's thoughts and imagination.
Critical Analysis
The BrainDreamer paper presents a promising step forward in the field of brain-computer interfaces and creative expression. By combining EEG-based neural representations with language-guided image generation, the system offers a unique and potentially transformative approach to visual creation.
However, the paper does acknowledge certain limitations and areas for further research. For instance, the current implementation relies on a specific EEG device and may require further development to work seamlessly with a broader range of brain-sensing technologies. Additionally, the language guidance, while crucial for coherence, may limit the creative freedom and spontaneity of the image generation process.
Researchers may also need to explore the ethical implications of such a system, particularly around issues of privacy, data security, and the potential for misuse or unintended consequences. As with any technology that interfaces directly with the human mind, careful consideration of these concerns is essential.
Overall, the BrainDreamer research represents an exciting advancement in the field of brain-computer interaction and creative AI. By empowering users to express their thoughts and imagination through visual means, the system holds promise for transforming how we engage with and create digital content.
Conclusion
BrainDreamer is a groundbreaking system that enables users to generate images directly from their brain signals and language guidance. By bridging the gap between cognition, perception, and visual expression, the system offers a new paradigm for creative interaction and communication.
The technical approach of combining EEG-based neural representations with language-guided image generation demonstrates the potential for seamlessly translating thoughts and imagination into visual form. As the research continues to evolve, the implications of BrainDreamer could extend far beyond the realm of art and design, potentially enhancing fields such as education, therapy, and even human-computer collaboration.
While the current implementation has certain limitations, the overall concept of BrainDreamer represents a significant step forward in the quest to unlock the full potential of the human mind and its connection to the digital world. As we continue to push the boundaries of brain-computer interfaces and creative AI, systems like BrainDreamer may become increasingly integral to how we perceive, express, and interact with the visual realm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BrainDreamer: Reasoning-Coherent and Controllable Image Generation from EEG Brain Signals via Language Guidance
Ling Wang, Chen Wu, Lin Wang
Can we directly visualize what we imagine in our brain together with what we describe? The inherent nature of human perception reveals that, when we think, our body can combine language description and build a vivid picture in our brain. Intuitively, generative models should also hold such versatility. In this paper, we introduce BrainDreamer, a novel end-to-end language-guided generative framework that can mimic human reasoning and generate high-quality images from electroencephalogram (EEG) brain signals. Our method is superior in its capacity to eliminate the noise introduced by non-invasive EEG data acquisition and meanwhile achieve a more precise mapping between the EEG and image modality, thus leading to significantly better-generated images. Specifically, BrainDreamer consists of two key learning stages: 1) modality alignment and 2) image generation. In the alignment stage, we propose a novel mask-based triple contrastive learning strategy to effectively align EEG, text, and image embeddings to learn a unified representation. In the generation stage, we inject the EEG embeddings into the pre-trained Stable Diffusion model by designing a learnable EEG adapter to generate high-quality reasoning-coherent images. Moreover, BrainDreamer can accept textual descriptions (e.g., color, position, etc.) to achieve controllable image generation. Extensive experiments show that our method significantly outperforms prior arts in terms of generating quality and quantitative performance.
Read more9/24/2024

0
Towards Linguistic Neural Representation Learning and Sentence Retrieval from Electroencephalogram Recordings
Jinzhao Zhou, Yiqun Duan, Ziyi Zhao, Yu-Cheng Chang, Yu-Kai Wang, Thomas Do, Chin-Teng Lin
Decoding linguistic information from non-invasive brain signals using EEG has gained increasing research attention due to its vast applicational potential. Recently, a number of works have adopted a generative-based framework to decode electroencephalogram (EEG) signals into sentences by utilizing the power generative capacity of pretrained large language models (LLMs). However, this approach has several drawbacks that hinder the further development of linguistic applications for brain-computer interfaces (BCIs). Specifically, the ability of the EEG encoder to learn semantic information from EEG data remains questionable, and the LLM decoder's tendency to generate sentences based on its training memory can be hard to avoid. These issues necessitate a novel approach for converting EEG signals into sentences. In this paper, we propose a novel two-step pipeline that addresses these limitations and enhances the validity of linguistic EEG decoding research. We first confirm that word-level semantic information can be learned from EEG data recorded during natural reading by training a Conformer encoder via a masked contrastive objective for word-level classification. To achieve sentence decoding results, we employ a training-free retrieval method to retrieve sentences based on the predictions from the EEG encoder. Extensive experiments and ablation studies were conducted in this paper for a comprehensive evaluation of the proposed approach. Visualization of the top prediction candidates reveals that our model effectively groups EEG segments into semantic categories with similar meanings, thereby validating its ability to learn patterns from unspoken EEG recordings. Despite the exploratory nature of this work, these results suggest that our method holds promise for providing more reliable solutions for converting EEG signals into text.
Read more8/12/2024

0
BrainVis: Exploring the Bridge between Brain and Visual Signals via Image Reconstruction
Honghao Fu, Zhiqi Shen, Jing Jih Chin, Hao Wang
Analyzing and reconstructing visual stimuli from brain signals effectively advances the understanding of human visual system. However, the EEG signals are complex and contain significant noise. This leads to substantial limitations in existing works of visual stimuli reconstruction from EEG, such as difficulties in aligning EEG embeddings with the fine-grained semantic information and a heavy reliance on additional large self-collected dataset for training. To address these challenges, we propose a novel approach called BrainVis. Firstly, we divide the EEG signals into various units and apply a self-supervised approach on them to obtain EEG time-domain features, in an attempt to ease the training difficulty. Additionally, we also propose to utilize the frequency-domain features to enhance the EEG representations. Then, we simultaneously align EEG time-frequency embeddings with the interpolation of the coarse and fine-grained semantics in the CLIP space, to highlight the primary visual components and reduce the cross-modal alignment difficulty. Finally, we adopt the cascaded diffusion models to reconstruct images. Using only 10% training data of the previous work, our proposed BrainVis outperforms state of the arts in both semantic fidelity reconstruction and generation quality. The code is available at https://github.com/RomGai/BrainVis.
Read more9/5/2024
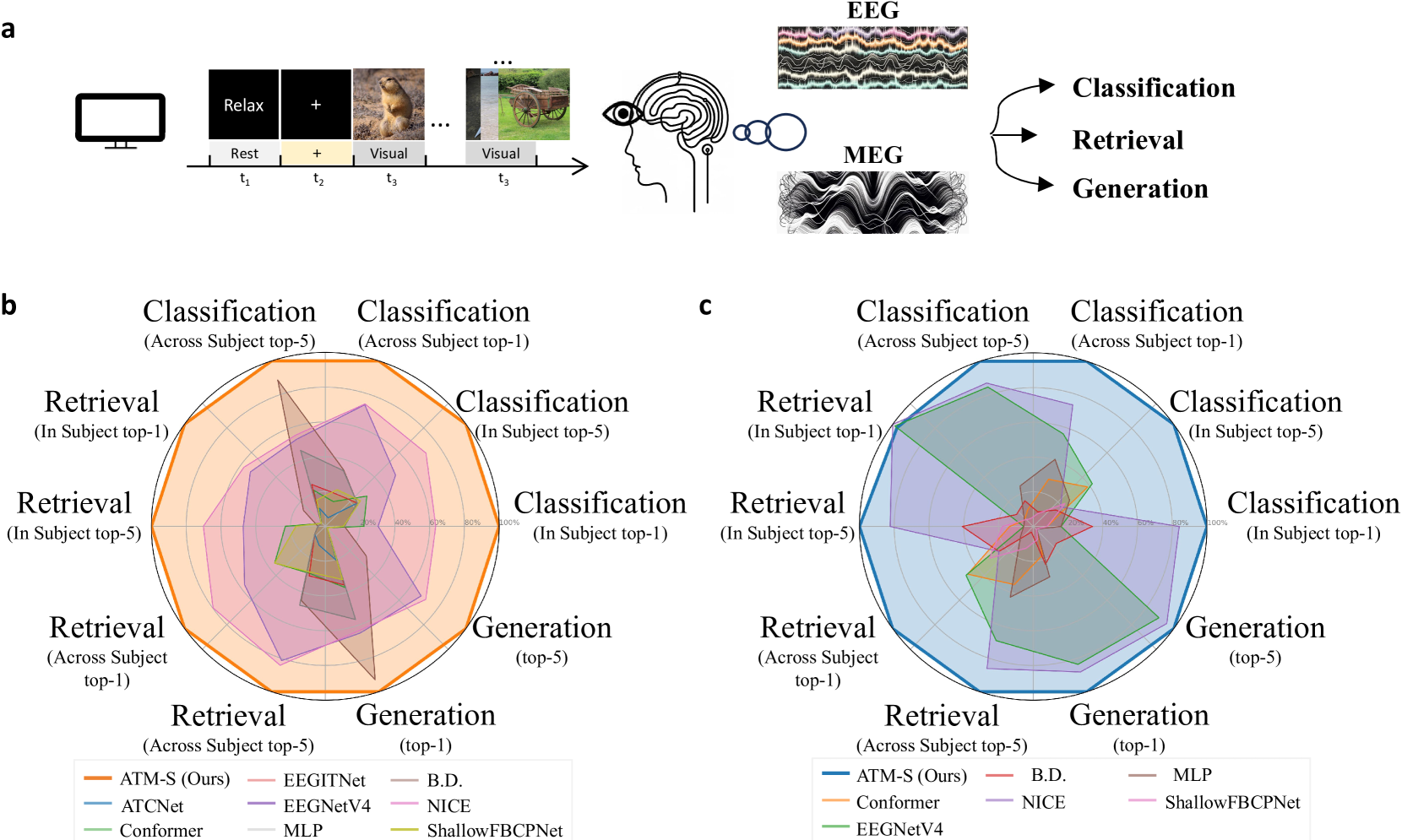
0
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Quanying Liu
How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
Read more4/8/2024