BrainVis: Exploring the Bridge between Brain and Visual Signals via Image Reconstruction

0

Sign in to get full access
Overview
- The paper explores the bridge between brain and visual signals through image reconstruction
- It proposes a model called BrainVis that can reconstruct visual stimuli from functional magnetic resonance imaging (fMRI) data
- The model leverages deep learning techniques to learn a joint representation of brain and visual signals, enabling it to generate plausible visual reconstructions from brain activity
Plain English Explanation
The paper investigates the connection between brain activity and the visual information we perceive. It introduces a model called BrainVis that can take brain scans (fMRI data) as input and generate reconstructed visual images as output.
The key idea is that the brain's neural activity contains information about the visual scenes we're looking at. By training a deep learning model to learn the relationship between brain signals and visual features, the researchers were able to develop a system that can reconstruct visual stimuli from just the brain data alone.
This bridge between brain and visual signals could have important applications, such as enhancing visual reconstruction for people with visual impairments or decoding our thoughts and inner experiences from brain activity.
Technical Explanation
The paper proposes the BrainVis model, which learns a joint representation of brain and visual signals to enable image reconstruction from fMRI data. The model consists of an encoder that takes fMRI data as input and learns a compact brain embedding, and a decoder that generates a reconstructed visual image from the brain embedding.
The encoder uses a 3D convolutional neural network to process the fMRI data, while the decoder employs a generative adversarial network (GAN) architecture to produce plausible image reconstructions. The two components are trained jointly, allowing the model to discover the underlying connections between brain activity and visual features.
Experiments on a dataset of natural images and corresponding fMRI data show that BrainVis can generate visually compelling reconstructions of the original stimuli. The reconstructions capture important details and semantic information, demonstrating the model's ability to bridge the gap between brain and visual signals.
Critical Analysis
The paper presents a promising approach for image reconstruction from brain activity, but it also acknowledges several limitations and avenues for future research. One key limitation is the use of a relatively small and constrained dataset of natural images, which may not fully capture the complexity of real-world visual experiences.
Additionally, the paper does not delve into the interpretability of the learned representations or the model's ability to generalize to novel visual stimuli. Further research is needed to better understand the internal workings of the BrainVis model and its potential for linguistic neural representation learning and other applications.
Conclusion
The BrainVis model represents a significant step towards bridging the gap between brain activity and visual perception. By learning a joint representation of brain and visual signals, the model demonstrates the potential to reconstruct visual stimuli from fMRI data alone. This research opens up exciting possibilities for enhancing visual reconstruction, decoding our thoughts and experiences, and gaining a deeper understanding of the neural mechanisms underlying visual processing and cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BrainVis: Exploring the Bridge between Brain and Visual Signals via Image Reconstruction
Honghao Fu, Zhiqi Shen, Jing Jih Chin, Hao Wang
Analyzing and reconstructing visual stimuli from brain signals effectively advances the understanding of human visual system. However, the EEG signals are complex and contain significant noise. This leads to substantial limitations in existing works of visual stimuli reconstruction from EEG, such as difficulties in aligning EEG embeddings with the fine-grained semantic information and a heavy reliance on additional large self-collected dataset for training. To address these challenges, we propose a novel approach called BrainVis. Firstly, we divide the EEG signals into various units and apply a self-supervised approach on them to obtain EEG time-domain features, in an attempt to ease the training difficulty. Additionally, we also propose to utilize the frequency-domain features to enhance the EEG representations. Then, we simultaneously align EEG time-frequency embeddings with the interpolation of the coarse and fine-grained semantics in the CLIP space, to highlight the primary visual components and reduce the cross-modal alignment difficulty. Finally, we adopt the cascaded diffusion models to reconstruct images. Using only 10% training data of the previous work, our proposed BrainVis outperforms state of the arts in both semantic fidelity reconstruction and generation quality. The code is available at https://github.com/RomGai/BrainVis.
Read more9/5/2024
0
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Quanying Liu
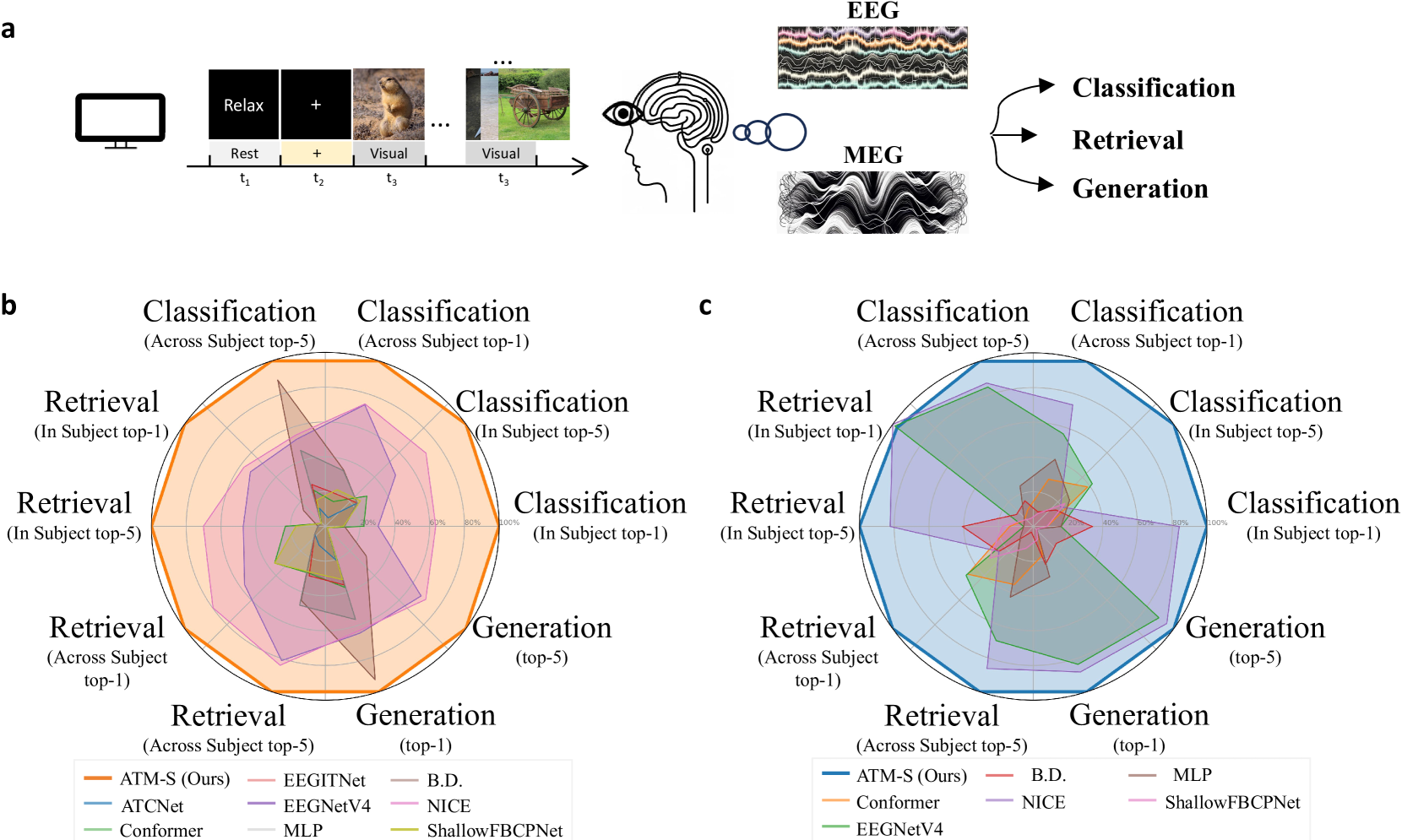
How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
Read more4/8/2024

0
BrainDreamer: Reasoning-Coherent and Controllable Image Generation from EEG Brain Signals via Language Guidance
Ling Wang, Chen Wu, Lin Wang
Can we directly visualize what we imagine in our brain together with what we describe? The inherent nature of human perception reveals that, when we think, our body can combine language description and build a vivid picture in our brain. Intuitively, generative models should also hold such versatility. In this paper, we introduce BrainDreamer, a novel end-to-end language-guided generative framework that can mimic human reasoning and generate high-quality images from electroencephalogram (EEG) brain signals. Our method is superior in its capacity to eliminate the noise introduced by non-invasive EEG data acquisition and meanwhile achieve a more precise mapping between the EEG and image modality, thus leading to significantly better-generated images. Specifically, BrainDreamer consists of two key learning stages: 1) modality alignment and 2) image generation. In the alignment stage, we propose a novel mask-based triple contrastive learning strategy to effectively align EEG, text, and image embeddings to learn a unified representation. In the generation stage, we inject the EEG embeddings into the pre-trained Stable Diffusion model by designing a learnable EEG adapter to generate high-quality reasoning-coherent images. Moreover, BrainDreamer can accept textual descriptions (e.g., color, position, etc.) to achieve controllable image generation. Extensive experiments show that our method significantly outperforms prior arts in terms of generating quality and quantitative performance.
Read more9/24/2024
🖼️
0
Neuro-Vision to Language: Image Reconstruction and Interaction via Non-invasive Brain Recordings
Guobin Shen, Dongcheng Zhao, Xiang He, Linghao Feng, Yiting Dong, Jihang Wang, Qian Zhang, Yi Zeng
Decoding non-invasive brain recordings is pivotal for advancing our understanding of human cognition but faces challenges due to individual differences and complex neural signal representations. Traditional methods often require customized models and extensive trials, lacking interpretability in visual reconstruction tasks. Our framework integrates 3D brain structures with visual semantics using a Vision Transformer 3D. This unified feature extractor efficiently aligns fMRI features with multiple levels of visual embeddings, eliminating the need for subject-specific models and allowing extraction from single-trial data. The extractor consolidates multi-level visual features into one network, simplifying integration with Large Language Models (LLMs). Additionally, we have enhanced the fMRI dataset with diverse fMRI-image-related textual data to support multimodal large model development. Integrating with LLMs enhances decoding capabilities, enabling tasks such as brain captioning, complex reasoning, concept localization, and visual reconstruction. Our approach demonstrates superior performance across these tasks, precisely identifying language-based concepts within brain signals, enhancing interpretability, and providing deeper insights into neural processes. These advances significantly broaden the applicability of non-invasive brain decoding in neuroscience and human-computer interaction, setting the stage for advanced brain-computer interfaces and cognitive models.
Read more5/24/2024