Brainformer: Mimic Human Visual Brain Functions to Machine Vision Models via fMRI
2312.00236
0
0
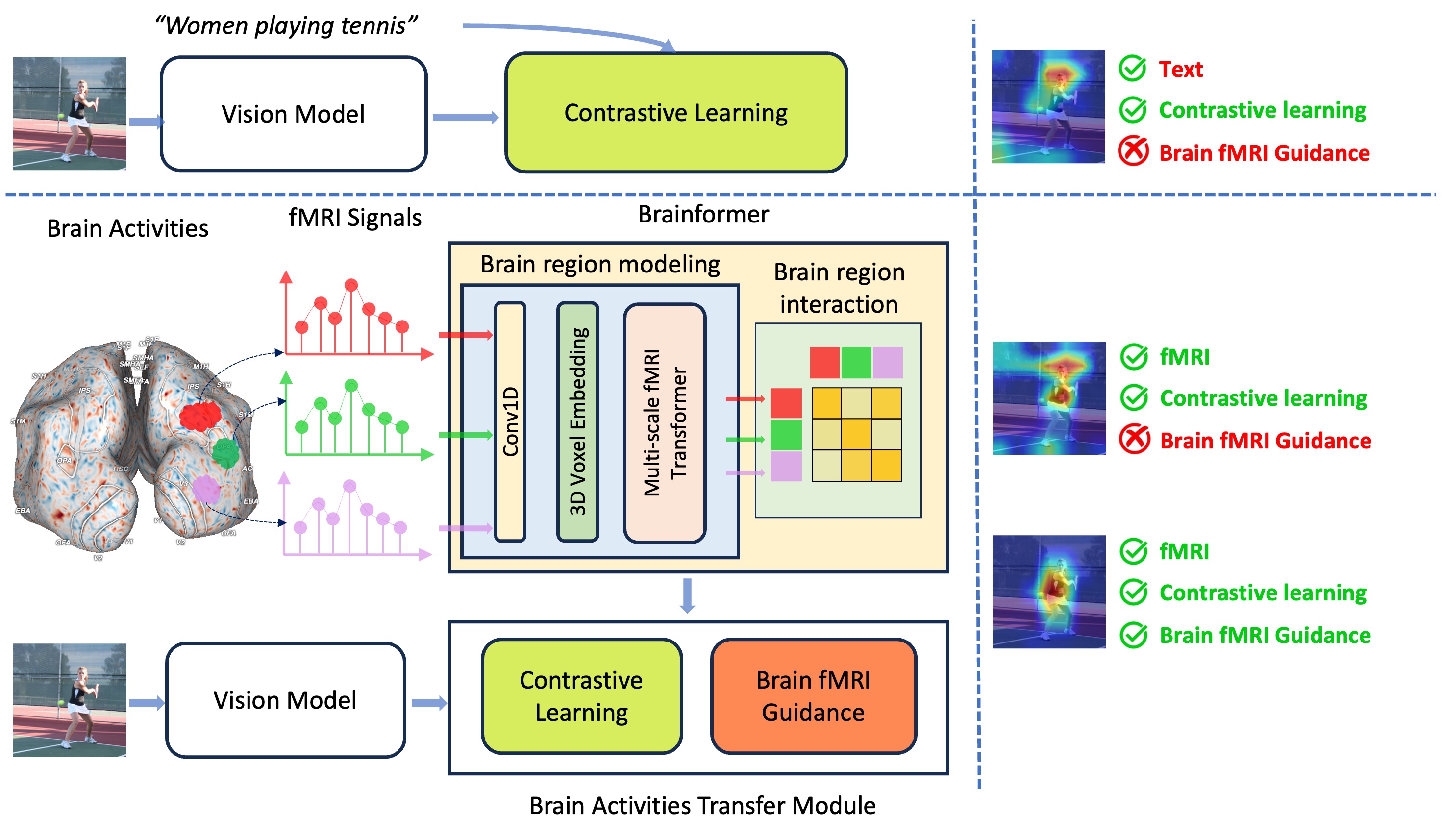
Abstract
Human perception plays a vital role in forming beliefs and understanding reality. A deeper understanding of brain functionality will lead to the development of novel deep neural networks. In this work, we introduce a novel framework named Brainformer, a straightforward yet effective Transformer-based framework, to analyze Functional Magnetic Resonance Imaging (fMRI) patterns in the human perception system from a machine-learning perspective. Specifically, we present the Multi-scale fMRI Transformer to explore brain activity patterns through fMRI signals. This architecture includes a simple yet efficient module for high-dimensional fMRI signal encoding and incorporates a novel embedding technique called 3D Voxels Embedding. Secondly, drawing inspiration from the functionality of the brain's Region of Interest, we introduce a novel loss function called Brain fMRI Guidance Loss. This loss function mimics brain activity patterns from these regions in the deep neural network using fMRI data. This work introduces a prospective approach to transfer knowledge from human perception to neural networks. Our experiments demonstrate that leveraging fMRI information allows the machine vision model to achieve results comparable to State-of-the-Art methods in various image recognition tasks.
Create account to get full access
Overview
- This paper presents "Brainformer," a model that aims to bridge the gap between magnetic resonance imaging (MRI) brain functions and machine vision applications.
- The model leverages transformer-based architectures to capture the complex relationships between brain activity patterns and visual processing.
- The research explores the potential of using MRI data to enhance machine vision tasks, such as image classification and object recognition.
Plain English Explanation
The human brain is an incredibly complex organ, and understanding how it processes visual information is a longstanding challenge in neuroscience and machine learning. The "Brainformer" model presented in this paper offers a new approach to bridging the gap between brain function and machine vision.
Magnetic resonance imaging (MRI) is a powerful tool that allows researchers to observe and measure brain activity in real-time. By analyzing patterns in MRI data, the Brainformer model can learn to associate specific brain activity with different visual processing tasks, such as recognizing objects or classifying images.
The key innovation of the Brainformer model is its use of transformer-based architectures, which are a type of deep learning model that excels at capturing complex relationships and dependencies in data. This allows the model to better understand the intricate connections between brain activity and visual processing, potentially leading to more accurate and robust machine vision systems.
The researchers demonstrate the effectiveness of the Brainformer model on a variety of machine vision tasks, showing that it can significantly improve the performance of image classification and object recognition algorithms when integrated with MRI data. This suggests that leveraging brain function information could be a powerful way to enhance the capabilities of artificial intelligence systems and bring them closer to the human-level understanding of the visual world.
Technical Explanation
The Brainformer model leverages the power of transformer-based architectures to establish a direct connection between MRI brain activity patterns and machine vision tasks. The core idea is to use the transformer's ability to capture complex relationships and dependencies in data to learn the intricate mapping between brain function and visual processing.
The model takes as input both MRI brain scans and visual stimuli, such as images or video frames. The MRI data is first processed through a series of convolutional and pooling layers to extract relevant features. These features are then combined with the visual inputs and fed into a transformer-based encoder-decoder architecture, which learns to associate the brain activity patterns with the corresponding visual processing.
The transformer component of the model is responsible for modeling the complex interdependencies between the brain and visual data, allowing the Brainformer to learn nuanced relationships that traditional machine learning approaches may struggle to capture. This enables the model to more accurately map brain function to visual tasks, potentially leading to significant improvements in the performance of machine vision systems.
The researchers evaluate the Brainformer model on a range of machine vision benchmarks, including image classification and object recognition. The results demonstrate that incorporating MRI brain data can substantially enhance the accuracy and robustness of these tasks compared to using visual inputs alone. This suggests that the Brainformer model can effectively leverage the rich information contained in brain activity patterns to enhance the capabilities of artificial intelligence systems in understanding and interacting with the visual world.
Critical Analysis
The Brainformer model presents an innovative approach to integrating brain function data with machine vision tasks, but it is important to consider some potential limitations and areas for further research.
One key limitation is the reliance on MRI data, which can be expensive, time-consuming, and not always readily available. While the researchers demonstrate the benefits of using MRI, it would be valuable to explore the feasibility of using more accessible brain imaging modalities, such as electroencephalography (EEG) or functional near-infrared spectroscopy (fNIRS), and how they may be integrated into the Brainformer framework.
Additionally, the paper does not provide a detailed analysis of the specific brain regions and mechanisms that are most influential in the observed improvements in machine vision performance. Further research could delve deeper into the neuroscientific insights gained from the Brainformer model, potentially leading to a better understanding of the neural underpinnings of visual processing.
It would also be valuable to explore the robustness of the Brainformer model to variations in experimental settings, such as different visual tasks, brain imaging modalities, or subject populations. Ensuring the model's reliability and generalizability across diverse contexts would be an important step towards real-world applications.
Conclusion
The Brainformer model presented in this paper offers a promising approach to integrating brain function data with machine vision tasks. By leveraging transformer-based architectures, the model can effectively capture the complex relationships between MRI brain activity patterns and visual processing, leading to significant improvements in the performance of image classification and object recognition algorithms.
This research highlights the potential of incorporating neuroscientific insights into artificial intelligence systems, bringing us one step closer to developing machine vision capabilities that more closely mimic the human visual system. As the field of brain-computer interfaces continues to advance, the Brainformer model and similar approaches could pave the way for more intuitive and effective human-machine interactions in a wide range of applications, from assistive technologies to immersive entertainment experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MindFormer: A Transformer Architecture for Multi-Subject Brain Decoding via fMRI
Inhwa Han, Jaayeon Lee, Jong Chul Ye
0
0
Research efforts to understand neural signals have been ongoing for many years, with visual decoding from fMRI signals attracting considerable attention. Particularly, the advent of image diffusion models has advanced the reconstruction of images from fMRI data significantly. However, existing approaches often introduce inter- and intra- subject variations in the reconstructed images, which can compromise accuracy. To address current limitations in multi-subject brain decoding, we introduce a new Transformer architecture called MindFormer. This model is specifically designed to generate fMRI-conditioned feature vectors that can be used for conditioning Stable Diffusion model. More specifically, MindFormer incorporates two key innovations: 1) a novel training strategy based on the IP-Adapter to extract semantically meaningful features from fMRI signals, and 2) a subject specific token and linear layer that effectively capture individual differences in fMRI signals while synergistically combines multi subject fMRI data for training. Our experimental results demonstrate that Stable Diffusion, when integrated with MindFormer, produces semantically consistent images across different subjects. This capability significantly surpasses existing models in multi-subject brain decoding. Such advancements not only improve the accuracy of our reconstructions but also deepen our understanding of neural processing variations among individuals.
5/29/2024

Automating the Diagnosis of Human Vision Disorders by Cross-modal 3D Generation
Li Zhang, Yuankun Yang, Ziyang Xie, Zhiyuan Yuan, Jianfeng Feng, Xiatian Zhu, Yu-Gang Jiang
0
0
Understanding the hidden mechanisms behind human's visual perception is a fundamental quest in neuroscience, underpins a wide variety of critical applications, e.g. clinical diagnosis. To that end, investigating into the neural responses of human mind activities, such as functional Magnetic Resonance Imaging (fMRI), has been a significant research vehicle. However, analyzing fMRI signals is challenging, costly, daunting, and demanding for professional training. Despite remarkable progress in artificial intelligence (AI) based fMRI analysis, existing solutions are limited and far away from being clinically meaningful. In this context, we leap forward to demonstrate how AI can go beyond the current state of the art by decoding fMRI into visually plausible 3D visuals, enabling automatic clinical analysis of fMRI data, even without healthcare professionals. Innovationally, we reformulate the task of analyzing fMRI data as a conditional 3D scene reconstruction problem. We design a novel cross-modal 3D scene representation learning method, Brain3D, that takes as input the fMRI data of a subject who was presented with a 2D object image, and yields as output the corresponding 3D object visuals. Importantly, we show that in simulated scenarios our AI agent captures the distinct functionalities of each region of human vision system as well as their intricate interplay relationships, aligning remarkably with the established discoveries of neuroscience. Non-expert diagnosis indicate that Brain3D can successfully identify the disordered brain regions, such as V1, V2, V3, V4, and the medial temporal lobe (MTL) within the human visual system. We also present results in cross-modal 3D visual construction setting, showcasing the perception quality of our 3D scene generation.
5/27/2024
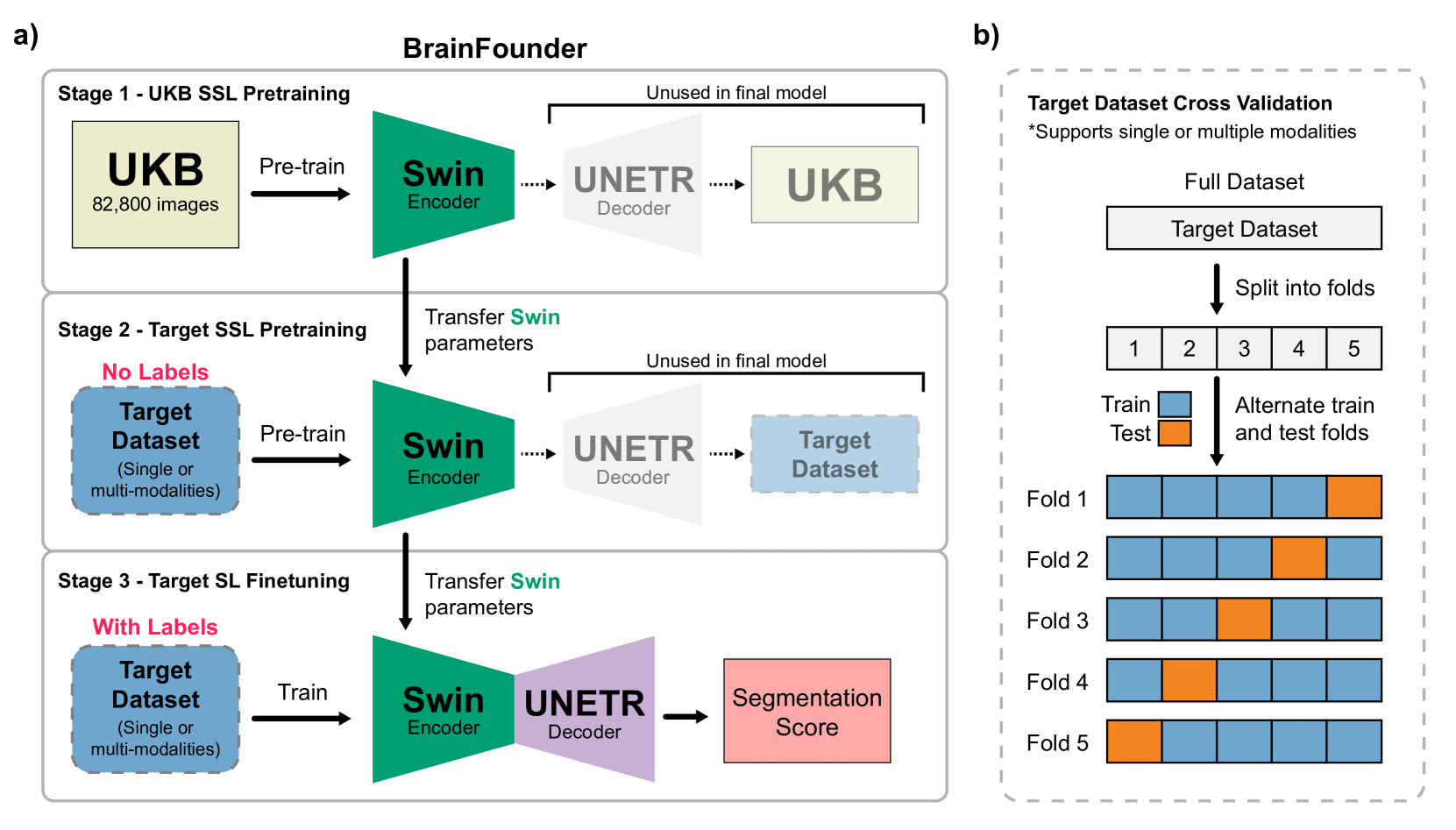
BrainFounder: Towards Brain Foundation Models for Neuroimage Analysis
Joseph Cox, Peng Liu, Skylar E. Stolte, Yunchao Yang, Kang Liu, Kyle B. See, Huiwen Ju, Ruogu Fang
0
0
The burgeoning field of brain health research increasingly leverages artificial intelligence (AI) to interpret and analyze neurological data. This study introduces a novel approach towards the creation of medical foundation models by integrating a large-scale multi-modal magnetic resonance imaging (MRI) dataset derived from 41,400 participants in its own. Our method involves a novel two-stage pretraining approach using vision transformers. The first stage is dedicated to encoding anatomical structures in generally healthy brains, identifying key features such as shapes and sizes of different brain regions. The second stage concentrates on spatial information, encompassing aspects like location and the relative positioning of brain structures. We rigorously evaluate our model, BrainFounder, using the Brain Tumor Segmentation (BraTS) challenge and Anatomical Tracings of Lesions After Stroke v2.0 (ATLAS v2.0) datasets. BrainFounder demonstrates a significant performance gain, surpassing the achievements of the previous winning solutions using fully supervised learning. Our findings underscore the impact of scaling up both the complexity of the model and the volume of unlabeled training data derived from generally healthy brains, which enhances the accuracy and predictive capabilities of the model in complex neuroimaging tasks with MRI. The implications of this research provide transformative insights and practical applications in healthcare and make substantial steps towards the creation of foundation models for Medical AI. Our pretrained models and training code can be found at https://github.com/lab-smile/GatorBrain.
6/18/2024
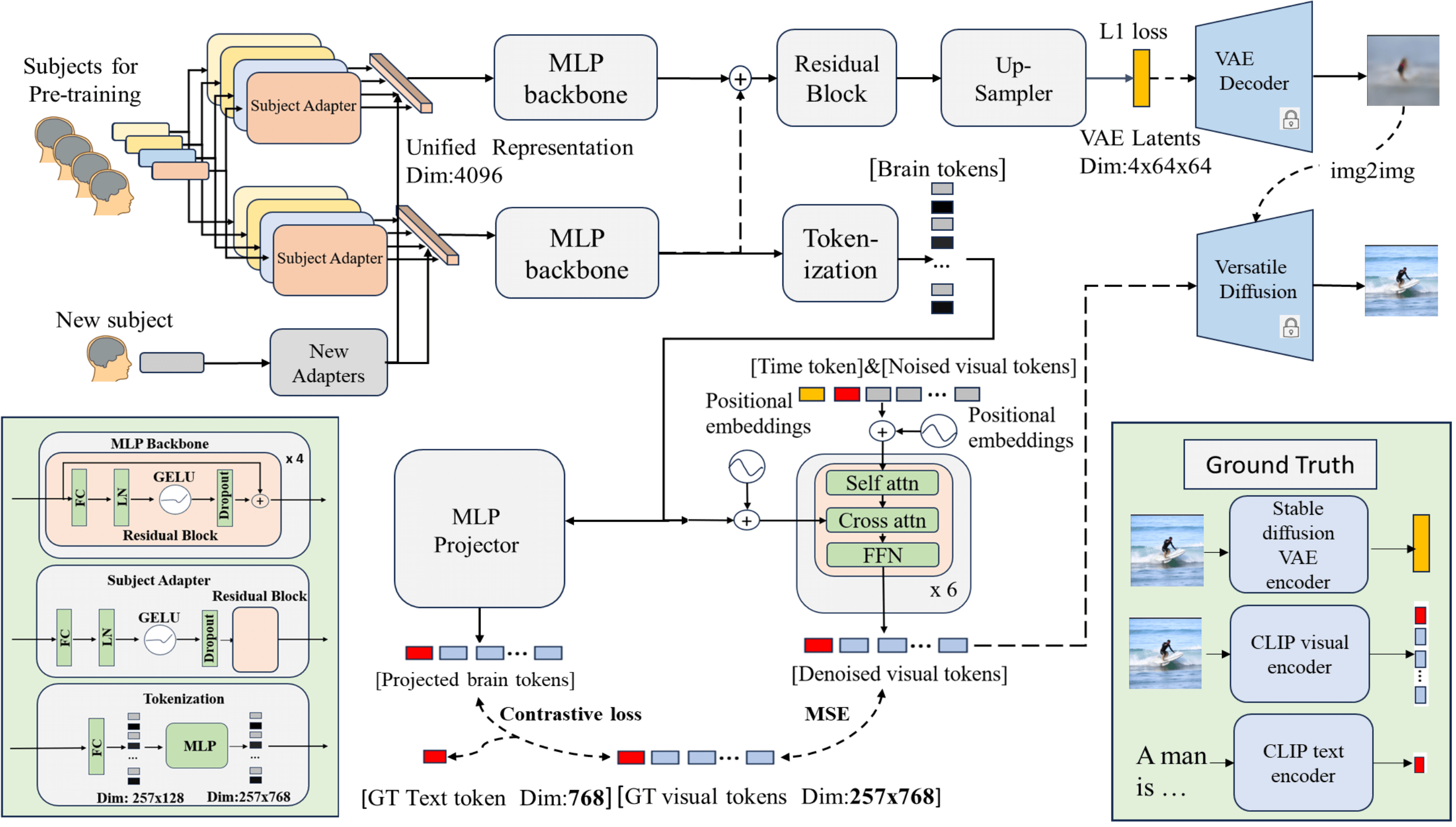
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024