MindFormer: A Transformer Architecture for Multi-Subject Brain Decoding via fMRI
2405.17720
0
0

Abstract
Research efforts to understand neural signals have been ongoing for many years, with visual decoding from fMRI signals attracting considerable attention. Particularly, the advent of image diffusion models has advanced the reconstruction of images from fMRI data significantly. However, existing approaches often introduce inter- and intra- subject variations in the reconstructed images, which can compromise accuracy. To address current limitations in multi-subject brain decoding, we introduce a new Transformer architecture called MindFormer. This model is specifically designed to generate fMRI-conditioned feature vectors that can be used for conditioning Stable Diffusion model. More specifically, MindFormer incorporates two key innovations: 1) a novel training strategy based on the IP-Adapter to extract semantically meaningful features from fMRI signals, and 2) a subject specific token and linear layer that effectively capture individual differences in fMRI signals while synergistically combines multi subject fMRI data for training. Our experimental results demonstrate that Stable Diffusion, when integrated with MindFormer, produces semantically consistent images across different subjects. This capability significantly surpasses existing models in multi-subject brain decoding. Such advancements not only improve the accuracy of our reconstructions but also deepen our understanding of neural processing variations among individuals.
Create account to get full access
Overview
• This paper introduces MindFormer, a novel transformer-based architecture for decoding brain activity from functional Magnetic Resonance Imaging (fMRI) data across multiple subjects.
• The key innovations of MindFormer include its ability to effectively leverage cross-subject information, handle subject-specific differences, and enable efficient and robust brain decoding.
• The paper demonstrates the superior performance of MindFormer on several benchmark brain decoding tasks compared to state-of-the-art methods, highlighting its potential to advance the field of brain-computer interfaces and neuroscience research.
Plain English Explanation
MindFormer is a new machine learning model that can analyze brain activity data from fMRI scans to decode what a person is thinking or experiencing. This builds on prior work like MindBridge, LiteMind, MindShot, and MindTuner. Unlike previous approaches, MindFormer is specifically designed to work across multiple people, capturing the unique characteristics of each individual's brain while also leveraging common patterns.
The key innovation of MindFormer is its use of a transformer-based architecture, similar to the language models that have revolutionized natural language processing. This allows MindFormer to efficiently process the complex, high-dimensional fMRI data and understand the relationships between different brain regions. By modeling both the general trends and individual variations in brain activity, MindFormer can make more accurate predictions about a person's thoughts and experiences.
The paper demonstrates that MindFormer outperforms other state-of-the-art brain decoding methods on a variety of benchmarks, suggesting it could be a valuable tool for neuroscience research and the development of brain-computer interfaces. These interfaces could one day allow people to control devices or communicate solely through their brain activity, which could be transformative for individuals with disabilities or neurological conditions.
Technical Explanation
The core of MindFormer is a transformer-based architecture that processes fMRI data in a unique way to enable robust and efficient cross-subject brain decoding. The model takes fMRI scans as input and learns to predict the mental state or cognitive task the subject was engaged in during the scan.
Unlike previous approaches that treated each subject independently, MindFormer explicitly models the relationships between subjects' brain activity patterns. This is achieved through a combination of subject-specific and shared transformer layers, allowing the model to capture both individual variations and common features across the population.
The transformer architecture also enables MindFormer to handle the high dimensionality and complex spatiotemporal structure of fMRI data more effectively than traditional machine learning models. The self-attention mechanism allows the model to identify relevant features and interactions within the data, leading to improved decoding performance.
The paper evaluates MindFormer on several benchmark brain decoding tasks, including mental state classification and visual stimulus reconstruction. The results show that MindFormer outperforms state-of-the-art methods like BrainFormers in terms of accuracy, efficiency, and robustness to subject-specific differences.
Critical Analysis
The paper provides a thorough evaluation of MindFormer's performance, but there are a few potential limitations worth considering. First, the experiments were conducted on relatively small datasets, and it would be valuable to see how the model scales to larger, more diverse datasets. Additionally, the paper does not address the interpretability of the model's predictions, which is an important consideration for many neuroscience and clinical applications.
Another potential concern is the computational complexity of the transformer architecture, which may limit the real-world deployment of MindFormer, especially in resource-constrained settings. The authors mention that future work will explore ways to further optimize the model's efficiency, which would be an important step towards practical applications.
Overall, the paper presents a promising and well-executed approach to cross-subject brain decoding. However, as with any novel technique, it will be crucial to validate the findings through independent replication and continued research to fully understand the strengths, limitations, and potential of the MindFormer architecture.
Conclusion
The MindFormer paper introduces a novel transformer-based architecture that significantly advances the state of the art in cross-subject brain decoding from fMRI data. By effectively leveraging both shared and subject-specific features, MindFormer demonstrates superior performance on a range of benchmark tasks compared to existing methods.
This work has important implications for the development of brain-computer interfaces and the broader field of computational neuroscience. The ability to accurately decode mental states and cognitive processes across individuals could lead to breakthroughs in assistive technologies, brain-based communication, and our understanding of how the human brain works.
While the paper highlights several promising aspects of MindFormer, further research is needed to address the potential limitations and optimize the model for real-world deployment. Nevertheless, this study represents a significant step forward in the quest to unlock the secrets of the mind through the power of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
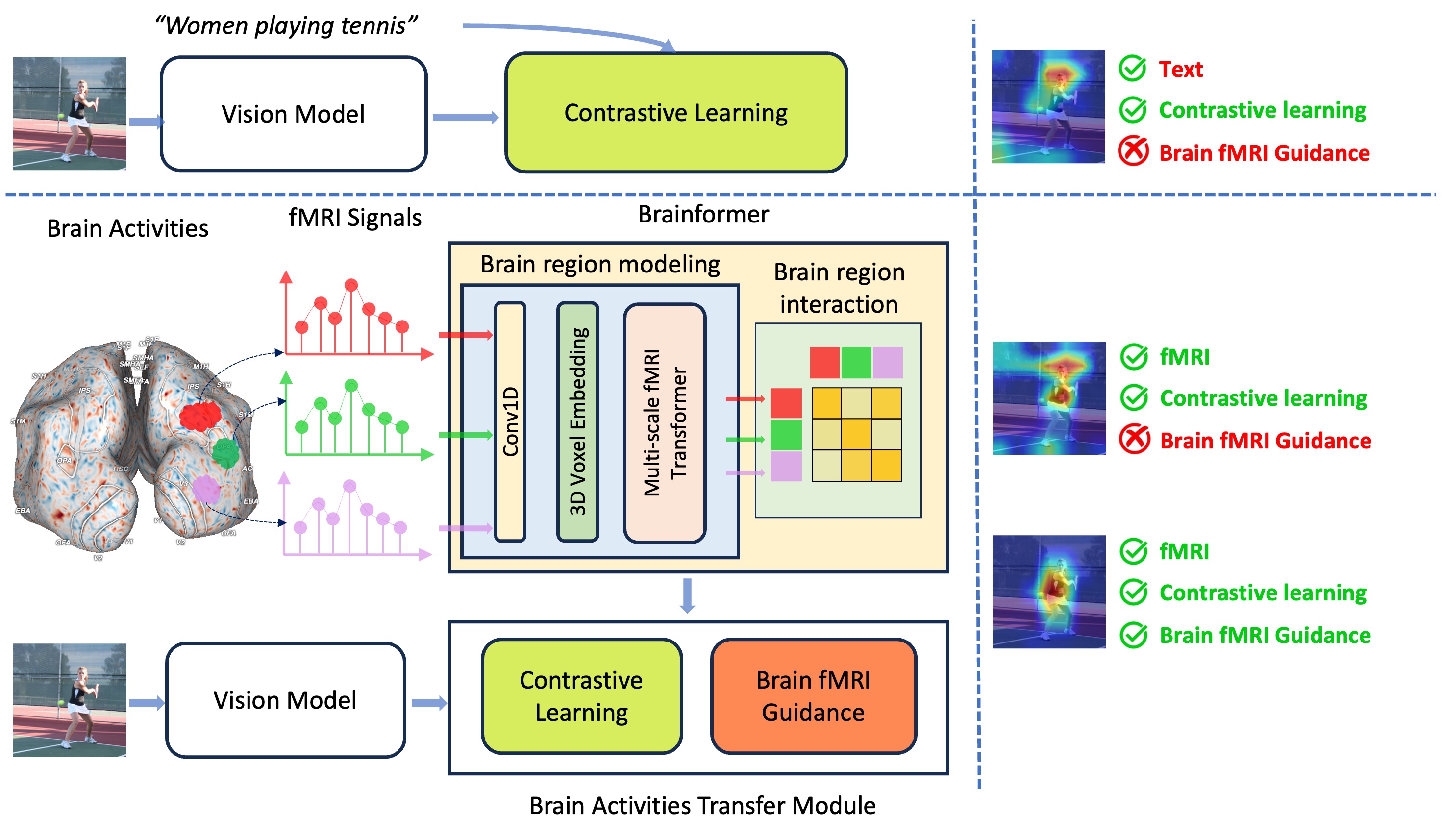
Brainformer: Mimic Human Visual Brain Functions to Machine Vision Models via fMRI
Xuan-Bac Nguyen, Xin Li, Pawan Sinha, Samee U. Khan, Khoa Luu
0
0
Human perception plays a vital role in forming beliefs and understanding reality. A deeper understanding of brain functionality will lead to the development of novel deep neural networks. In this work, we introduce a novel framework named Brainformer, a straightforward yet effective Transformer-based framework, to analyze Functional Magnetic Resonance Imaging (fMRI) patterns in the human perception system from a machine-learning perspective. Specifically, we present the Multi-scale fMRI Transformer to explore brain activity patterns through fMRI signals. This architecture includes a simple yet efficient module for high-dimensional fMRI signal encoding and incorporates a novel embedding technique called 3D Voxels Embedding. Secondly, drawing inspiration from the functionality of the brain's Region of Interest, we introduce a novel loss function called Brain fMRI Guidance Loss. This loss function mimics brain activity patterns from these regions in the deep neural network using fMRI data. This work introduces a prospective approach to transfer knowledge from human perception to neural networks. Our experiments demonstrate that leveraging fMRI information allows the machine vision model to achieve results comparable to State-of-the-Art methods in various image recognition tasks.
5/30/2024
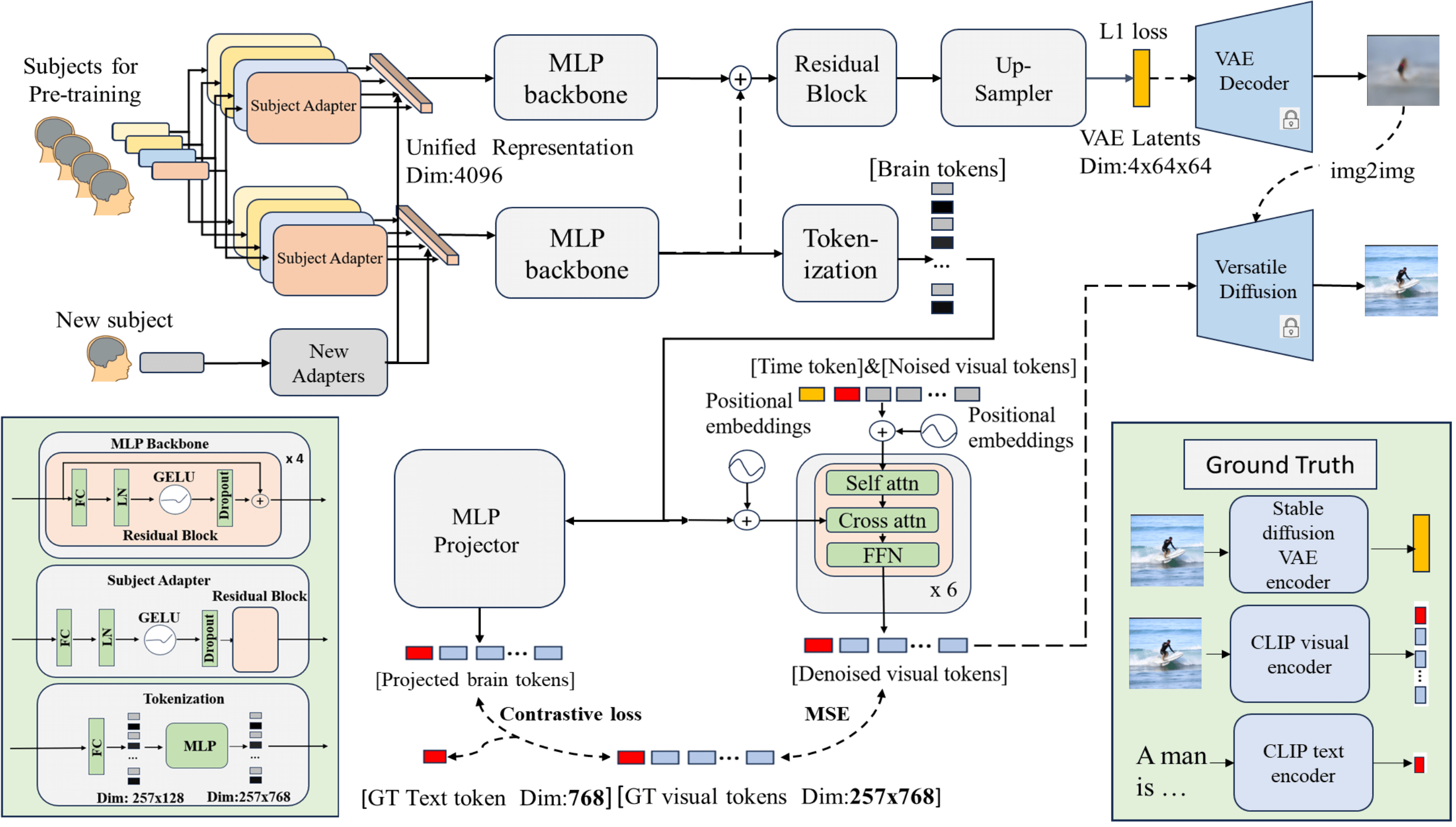
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024
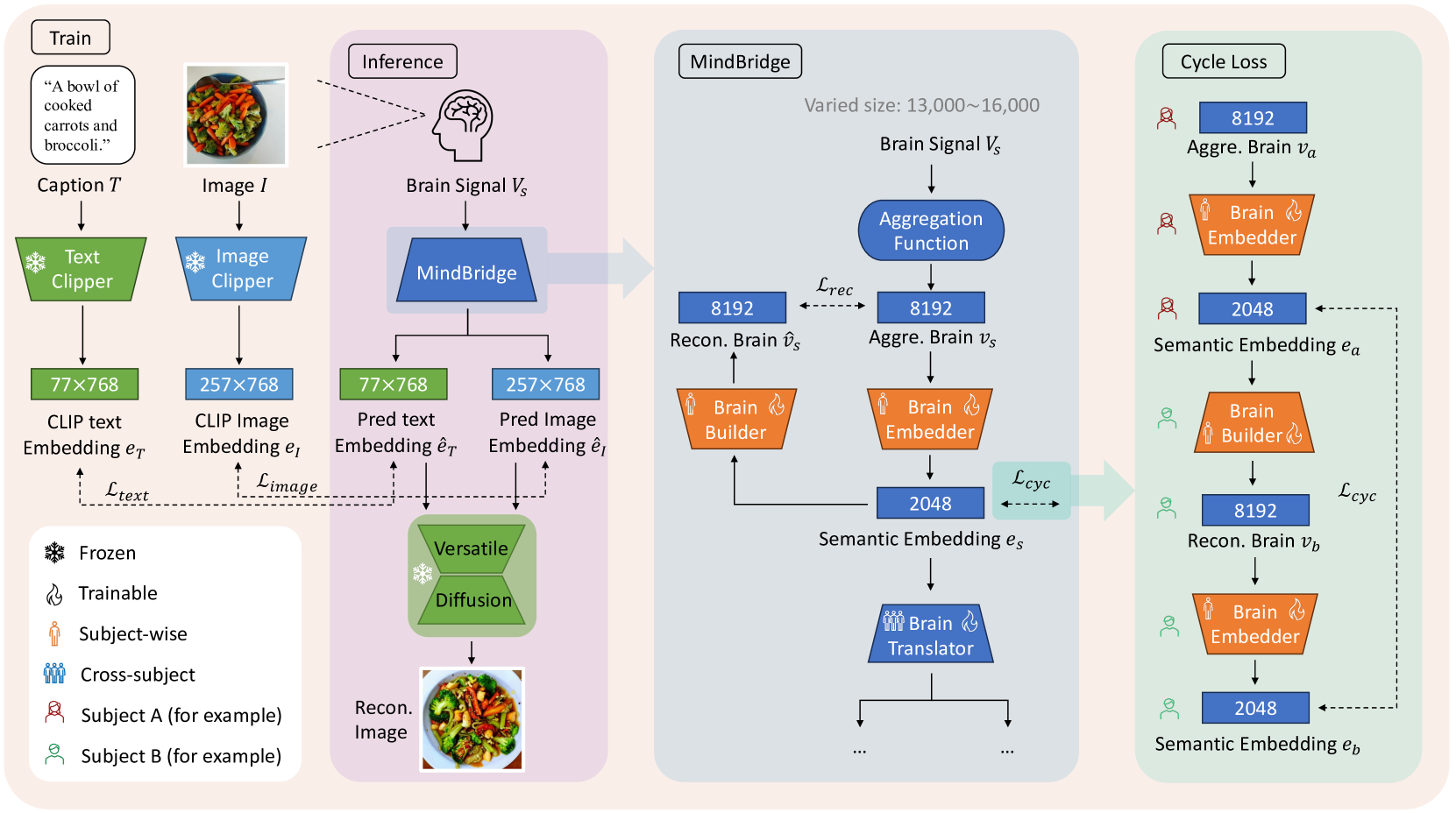
MindBridge: A Cross-Subject Brain Decoding Framework
Shizun Wang, Songhua Liu, Zhenxiong Tan, Xinchao Wang
0
0
Brain decoding, a pivotal field in neuroscience, aims to reconstruct stimuli from acquired brain signals, primarily utilizing functional magnetic resonance imaging (fMRI). Currently, brain decoding is confined to a per-subject-per-model paradigm, limiting its applicability to the same individual for whom the decoding model is trained. This constraint stems from three key challenges: 1) the inherent variability in input dimensions across subjects due to differences in brain size; 2) the unique intrinsic neural patterns, influencing how different individuals perceive and process sensory information; 3) limited data availability for new subjects in real-world scenarios hampers the performance of decoding models. In this paper, we present a novel approach, MindBridge, that achieves cross-subject brain decoding by employing only one model. Our proposed framework establishes a generic paradigm capable of addressing these challenges by introducing biological-inspired aggregation function and novel cyclic fMRI reconstruction mechanism for subject-invariant representation learning. Notably, by cycle reconstruction of fMRI, MindBridge can enable novel fMRI synthesis, which also can serve as pseudo data augmentation. Within the framework, we also devise a novel reset-tuning method for adapting a pretrained model to a new subject. Experimental results demonstrate MindBridge's ability to reconstruct images for multiple subjects, which is competitive with dedicated subject-specific models. Furthermore, with limited data for a new subject, we achieve a high level of decoding accuracy, surpassing that of subject-specific models. This advancement in cross-subject brain decoding suggests promising directions for wider applications in neuroscience and indicates potential for more efficient utilization of limited fMRI data in real-world scenarios. Project page: https://littlepure2333.github.io/MindBridge
4/12/2024
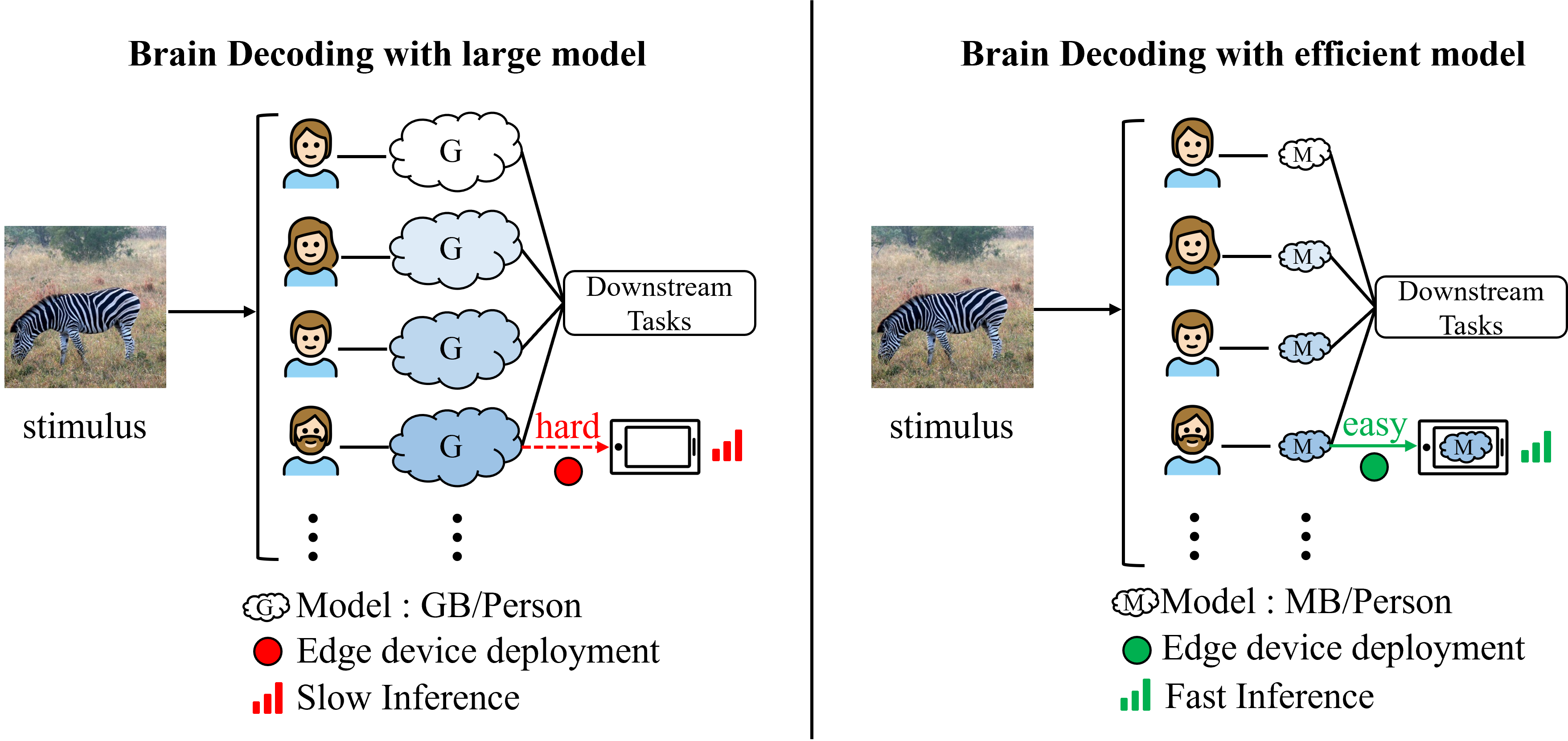
Lite-Mind: Towards Efficient and Robust Brain Representation Network
Zixuan Gong, Qi Zhang, Guangyin Bao, Lei Zhu, Yu Zhang, Ke Liu, Liang Hu, Duoqian Miao
0
0
The limited data availability and the low signal-to-noise ratio of fMRI signals lead to the challenging task of fMRI-to-image retrieval. State-of-the-art MindEye remarkably improves fMRI-to-image retrieval performance by leveraging a large model, i.e., a 996M MLP Backbone per subject, to align fMRI embeddings to the final hidden layer of CLIP's Vision Transformer (ViT). However, significant individual variations exist among subjects, even under identical experimental setups, mandating the training of large subject-specific models. The substantial parameters pose significant challenges in deploying fMRI decoding on practical devices. To this end, we propose Lite-Mind, a lightweight, efficient, and robust brain representation learning paradigm based on Discrete Fourier Transform (DFT), which efficiently aligns fMRI voxels to fine-grained information of CLIP. We elaborately design a DFT backbone with Spectrum Compression and Frequency Projector modules to learn informative and robust voxel embeddings. Our experiments demonstrate that Lite-Mind achieves an impressive 94.6% fMRI-to-image retrieval accuracy on the NSD dataset for Subject 1, with 98.7% fewer parameters than MindEye. Lite-Mind is also proven to be able to be migrated to smaller fMRI datasets and establishes a new state-of-the-art for zero-shot classification on the GOD dataset.
4/22/2024