BrainFounder: Towards Brain Foundation Models for Neuroimage Analysis
2406.10395
0
0
Abstract
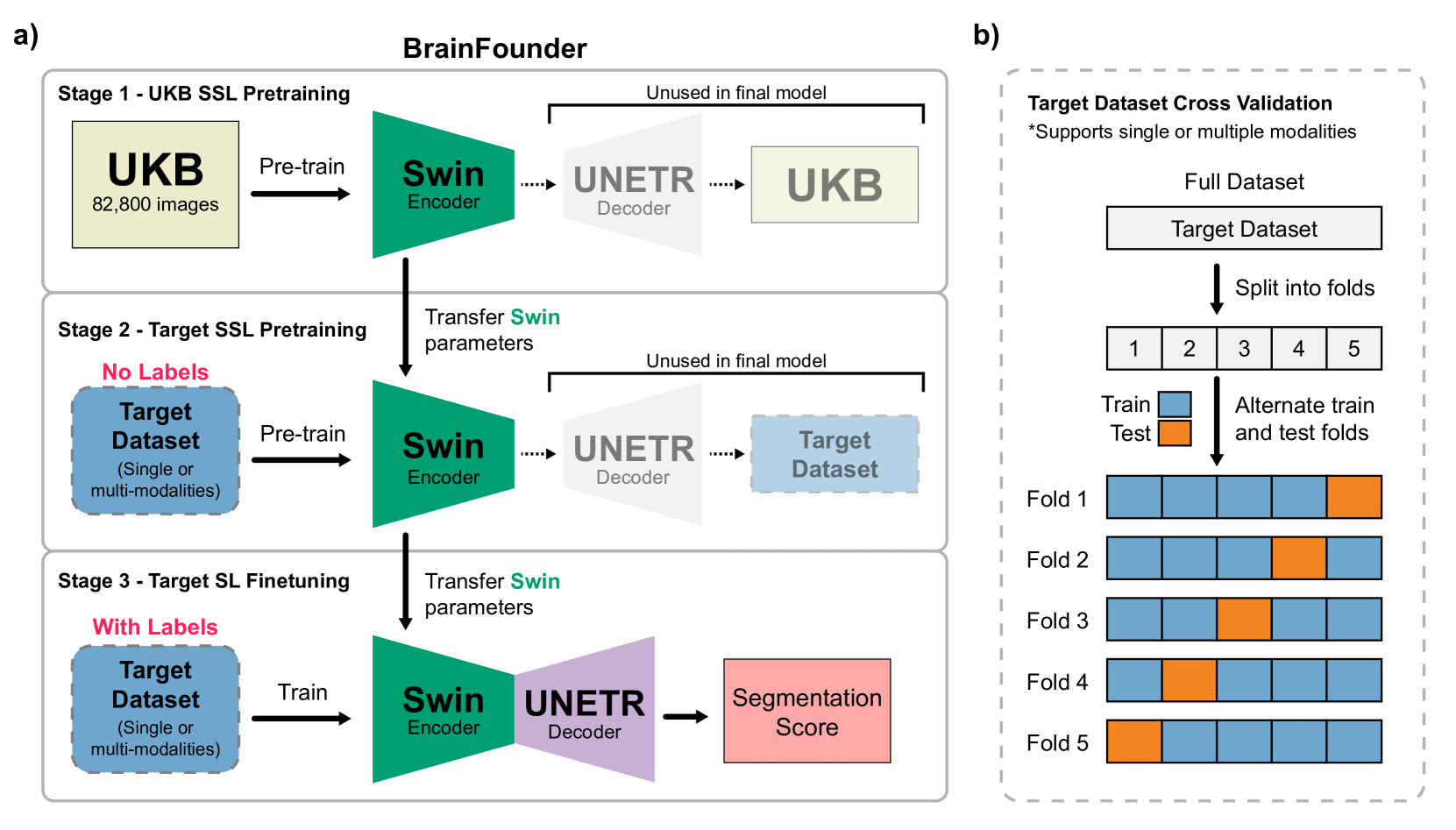
The burgeoning field of brain health research increasingly leverages artificial intelligence (AI) to interpret and analyze neurological data. This study introduces a novel approach towards the creation of medical foundation models by integrating a large-scale multi-modal magnetic resonance imaging (MRI) dataset derived from 41,400 participants in its own. Our method involves a novel two-stage pretraining approach using vision transformers. The first stage is dedicated to encoding anatomical structures in generally healthy brains, identifying key features such as shapes and sizes of different brain regions. The second stage concentrates on spatial information, encompassing aspects like location and the relative positioning of brain structures. We rigorously evaluate our model, BrainFounder, using the Brain Tumor Segmentation (BraTS) challenge and Anatomical Tracings of Lesions After Stroke v2.0 (ATLAS v2.0) datasets. BrainFounder demonstrates a significant performance gain, surpassing the achievements of the previous winning solutions using fully supervised learning. Our findings underscore the impact of scaling up both the complexity of the model and the volume of unlabeled training data derived from generally healthy brains, which enhances the accuracy and predictive capabilities of the model in complex neuroimaging tasks with MRI. The implications of this research provide transformative insights and practical applications in healthcare and make substantial steps towards the creation of foundation models for Medical AI. Our pretrained models and training code can be found at https://github.com/lab-smile/GatorBrain.
Create account to get full access
Overview
- The paper introduces BrainFounder, a framework for developing brain foundation models to analyze neuroimages.
- BrainFounder leverages self-supervised learning to extract meaningful features from brain images without relying on costly manual annotations.
- The framework is evaluated on the task of brain tumor segmentation, demonstrating its effectiveness in learning robust representations for medical imaging analysis.
Plain English Explanation
The paper introduces a new approach called BrainFounder that aims to make it easier to analyze brain images, such as those used for diagnosing and treating brain tumors. Current methods often require a lot of manually labeled training data, which can be time-consuming and expensive to obtain.
BrainFounder uses a technique called self-supervised learning to automatically learn useful features from brain images without needing all that manual labeling. The key idea is to train a neural network model to find patterns in the data itself, rather than relying on predefined labels. This allows the model to discover relevant information on its own.
The paper shows that BrainFounder can be effective for the task of brain tumor segmentation, where the goal is to identify the location and extent of a tumor in a brain scan. By learning robust representations of the brain structure, the BrainFounder model can accurately locate and delineate tumors without extensive manual labeling.
This work is part of a broader trend towards developing foundation models for medical imaging, which aim to create reusable, general-purpose models that can be adapted to a variety of tasks and datasets. The hope is that this will make it easier and more efficient to apply advanced AI techniques to real-world medical problems.
Technical Explanation
The BrainFounder framework is built around a self-supervised learning approach to extract meaningful representations from brain images. The key components include:
-
A self-supervised pretraining stage where the model learns to predict the relative position of image patches within the full brain scan. This allows the model to discover low-level visual features and spatial relationships without any manual labeling.
-
An adaptation stage where the pretrained model is fine-tuned on a specific task, such as brain tumor segmentation, by incorporating a small amount of labeled training data.
-
A multi-modal fusion module that combines information from different imaging modalities (e.g., MRI, CT) to leverage complementary signals and improve segmentation performance.
The paper evaluates BrainFounder on several brain tumor segmentation benchmarks, demonstrating that it outperforms both supervised baselines and other self-supervised approaches. The model is able to generalize well to unseen datasets, showing the benefits of the learned representations.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the BrainFounder framework, addressing key challenges in brain image analysis. However, a few potential limitations and areas for future work are worth considering:
-
The self-supervised pretraining approach, while effective, may not capture all the relevant high-level features needed for complex medical tasks. Incorporating additional pretraining objectives or hybrid approaches could further improve performance.
-
The evaluation is focused on brain tumor segmentation, but the framework could be extended and tested on a wider range of neuroimaging tasks, such as lesion detection, brain structure analysis, or disease prediction.
-
Real-world clinical deployment would require addressing issues of interpretability, robustness, and model calibration to ensure the safety and reliability of the system, which are not fully covered in this paper.
-
Scaling the framework to larger and more diverse datasets, as well as accounting for domain shift across clinical sites, are important practical considerations for future research.
Conclusion
The BrainFounder framework offers a promising approach to developing brain foundation models that can learn robust representations from neuroimages in a self-supervised manner. By reducing the need for extensive manual labeling, this work has the potential to make advanced AI techniques more accessible and applicable to a variety of medical imaging tasks.
As the field of medical AI continues to evolve, frameworks like BrainFounder could play a crucial role in bridging the gap between research and real-world clinical deployment, ultimately improving patient outcomes and accelerating the pace of medical discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
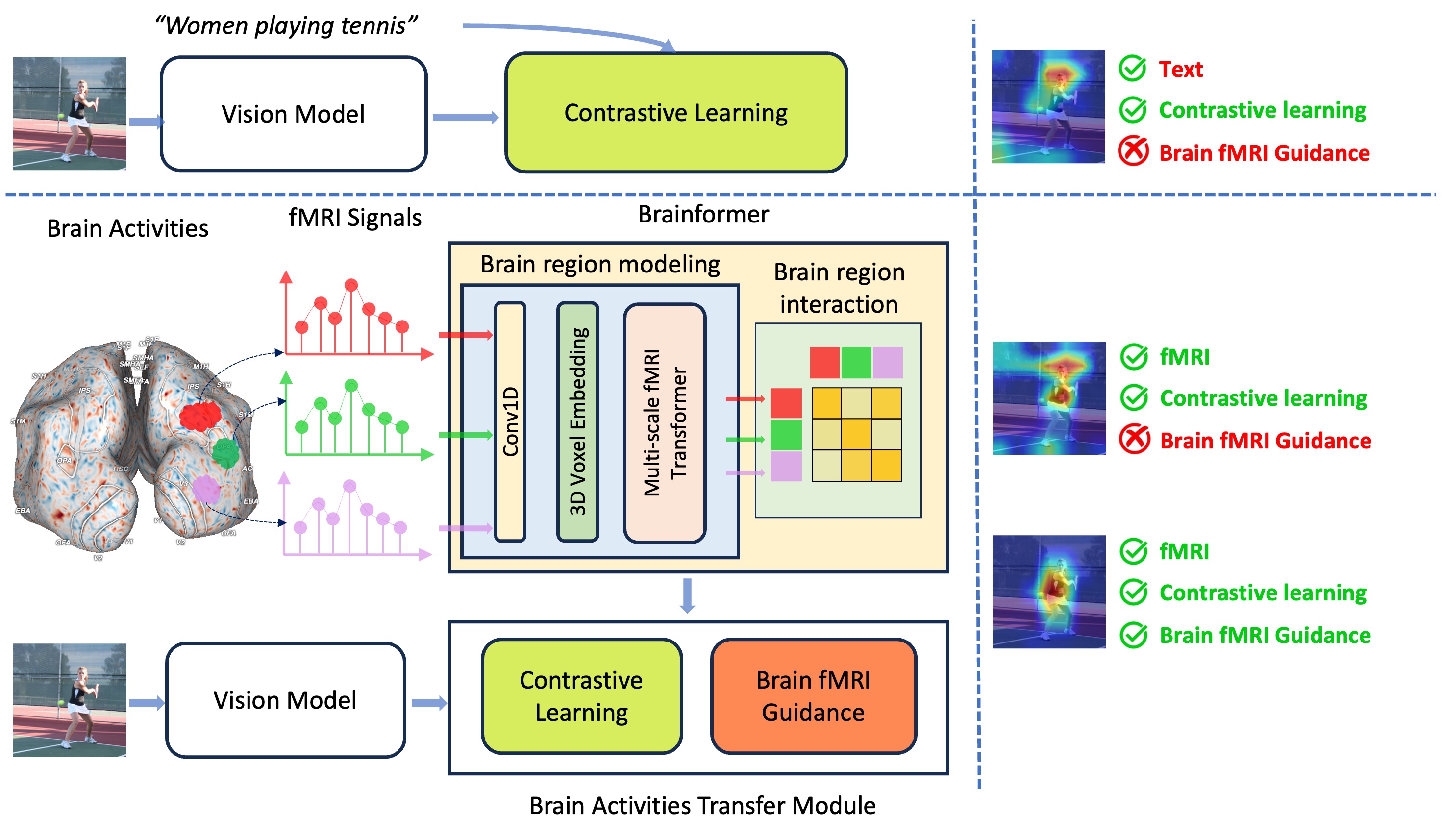
Brainformer: Mimic Human Visual Brain Functions to Machine Vision Models via fMRI
Xuan-Bac Nguyen, Xin Li, Pawan Sinha, Samee U. Khan, Khoa Luu
0
0
Human perception plays a vital role in forming beliefs and understanding reality. A deeper understanding of brain functionality will lead to the development of novel deep neural networks. In this work, we introduce a novel framework named Brainformer, a straightforward yet effective Transformer-based framework, to analyze Functional Magnetic Resonance Imaging (fMRI) patterns in the human perception system from a machine-learning perspective. Specifically, we present the Multi-scale fMRI Transformer to explore brain activity patterns through fMRI signals. This architecture includes a simple yet efficient module for high-dimensional fMRI signal encoding and incorporates a novel embedding technique called 3D Voxels Embedding. Secondly, drawing inspiration from the functionality of the brain's Region of Interest, we introduce a novel loss function called Brain fMRI Guidance Loss. This loss function mimics brain activity patterns from these regions in the deep neural network using fMRI data. This work introduces a prospective approach to transfer knowledge from human perception to neural networks. Our experiments demonstrate that leveraging fMRI information allows the machine vision model to achieve results comparable to State-of-the-Art methods in various image recognition tasks.
5/30/2024

A Foundation Model for Brain Lesion Segmentation with Mixture of Modality Experts
Xinru Zhang, Ni Ou, Berke Doga Basaran, Marco Visentin, Mengyun Qiao, Renyang Gu, Cheng Ouyang, Yaou Liu, Paul M. Matthew, Chuyang Ye, Wenjia Bai
0
0
Brain lesion segmentation plays an essential role in neurological research and diagnosis. As brain lesions can be caused by various pathological alterations, different types of brain lesions tend to manifest with different characteristics on different imaging modalities. Due to this complexity, brain lesion segmentation methods are often developed in a task-specific manner. A specific segmentation model is developed for a particular lesion type and imaging modality. However, the use of task-specific models requires predetermination of the lesion type and imaging modality, which complicates their deployment in real-world scenarios. In this work, we propose a universal foundation model for 3D brain lesion segmentation, which can automatically segment different types of brain lesions for input data of various imaging modalities. We formulate a novel Mixture of Modality Experts (MoME) framework with multiple expert networks attending to different imaging modalities. A hierarchical gating network combines the expert predictions and fosters expertise collaboration. Furthermore, we introduce a curriculum learning strategy during training to avoid the degeneration of each expert network and preserve their specialization. We evaluated the proposed method on nine brain lesion datasets, encompassing five imaging modalities and eight lesion types. The results show that our model outperforms state-of-the-art universal models and provides promising generalization to unseen datasets.
5/17/2024

MindFormer: A Transformer Architecture for Multi-Subject Brain Decoding via fMRI
Inhwa Han, Jaayeon Lee, Jong Chul Ye
0
0
Research efforts to understand neural signals have been ongoing for many years, with visual decoding from fMRI signals attracting considerable attention. Particularly, the advent of image diffusion models has advanced the reconstruction of images from fMRI data significantly. However, existing approaches often introduce inter- and intra- subject variations in the reconstructed images, which can compromise accuracy. To address current limitations in multi-subject brain decoding, we introduce a new Transformer architecture called MindFormer. This model is specifically designed to generate fMRI-conditioned feature vectors that can be used for conditioning Stable Diffusion model. More specifically, MindFormer incorporates two key innovations: 1) a novel training strategy based on the IP-Adapter to extract semantically meaningful features from fMRI signals, and 2) a subject specific token and linear layer that effectively capture individual differences in fMRI signals while synergistically combines multi subject fMRI data for training. Our experimental results demonstrate that Stable Diffusion, when integrated with MindFormer, produces semantically consistent images across different subjects. This capability significantly surpasses existing models in multi-subject brain decoding. Such advancements not only improve the accuracy of our reconstructions but also deepen our understanding of neural processing variations among individuals.
5/29/2024
🛠️
Influence based explainability of brain tumors segmentation in multimodal Magnetic Resonance Imaging
Tommaso Torda, Andrea Ciardiello, Simona Gargiulo, Greta Grillo, Simone Scardapane, Cecilia Voena, Stefano Giagu
0
0
In recent years Artificial Intelligence has emerged as a fundamental tool in medical applications. Despite this rapid development, deep neural networks remain black boxes that are difficult to explain, and this represents a major limitation for their use in clinical practice. We focus on the segmentation of medical images task, where most explainability methods proposed so far provide a visual explanation in terms of an input saliency map. The aim of this work is to extend, implement and test instead an influence-based explainability algorithm, TracIn, proposed originally for classification tasks, in a challenging clinical problem, i.e., multiclass segmentation of tumor brains in multimodal Magnetic Resonance Imaging. We verify the faithfulness of the proposed algorithm linking the similarities of the latent representation of the network to the TracIn output. We further test the capacity of the algorithm to provide local and global explanations, and we suggest that it can be adopted as a tool to select the most relevant features used in the decision process. The method is generalizable for all semantic segmentation tasks where classes are mutually exclusive, which is the standard framework in these cases.
5/22/2024