Break the Chain: Large Language Models Can be Shortcut Reasoners
2406.06580
0
0

Abstract
Recent advancements in Chain-of-Thought (CoT) reasoning utilize complex modules but are hampered by high token consumption, limited applicability, and challenges in reproducibility. This paper conducts a critical evaluation of CoT prompting, extending beyond arithmetic to include complex logical and commonsense reasoning tasks, areas where standard CoT methods fall short. We propose the integration of human-like heuristics and shortcuts into language models (LMs) through break the chain strategies. These strategies disrupt traditional CoT processes using controlled variables to assess their efficacy. Additionally, we develop innovative zero-shot prompting strategies that encourage the use of shortcuts, enabling LMs to quickly exploit reasoning clues and bypass detailed procedural steps. Our comprehensive experiments across various LMs, both commercial and open-source, reveal that LMs maintain effective performance with break the chain strategies. We also introduce ShortcutQA, a dataset specifically designed to evaluate reasoning through shortcuts, compiled from competitive tests optimized for heuristic reasoning tasks such as forward/backward reasoning and simplification. Our analysis confirms that ShortcutQA not only poses a robust challenge to LMs but also serves as an essential benchmark for enhancing reasoning efficiency in AI.
Create account to get full access
Overview
- This paper examines how large language models (LLMs) can sometimes take "shortcuts" when reasoning, rather than following a logical chain of thought.
- The researchers find that LLMs can sometimes provide plausible-sounding answers without actually understanding the underlying concepts or reasoning properly.
- This has implications for the reliability and robustness of LLMs in high-stakes applications where rigorous reasoning is essential.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have made impressive strides in natural language processing, but this paper shows they can sometimes take "shortcuts" when reasoning. Instead of carefully following a logical chain of thought, the models may provide answers that sound plausible but actually miss key steps in the reasoning.
For example, if asked to solve a multi-step math problem, an LLM might skip over intermediate calculations and jump straight to the final answer, without demonstrating a full understanding of the underlying concepts. This kind of "shortcut" reasoning can lead to mistakes or unreliable outputs, especially in high-stakes applications like medical diagnosis or legal analysis.
The researchers explore various techniques to try to "break" this shortcut behavior and force the LLMs to engage in more robust, step-by-step reasoning. Approaches like chain-of-thought prompting and pattern-aware prompting show some promise, but more research is still needed to fully address the challenges of ensuring LLMs can reason reliably.
Overall, this paper highlights an important limitation of current LLM technology and the need for continued innovation to make these models more robust and trustworthy, especially in high-stakes applications.
Technical Explanation
The paper "Break the Chain: Large Language Models Can be Shortcut Reasoners" investigates how large language models (LLMs) can sometimes take "shortcuts" when engaging in reasoning tasks, rather than following a logical chain of thought.
The authors conduct a series of experiments where they prompt LLMs like GPT-3 and GPT-J to solve multi-step problems that require step-by-step reasoning. They find that the models are often able to provide plausible-sounding final answers without demonstrating a full understanding of the underlying concepts and logic.
For example, in math word problems, the LLMs may skip intermediate calculations and jump straight to the final result. In logical reasoning tasks, they may make invalid inferences by relying on superficial patterns in the data rather than sound logical principles.
The researchers explore various techniques to try to "break" this shortcut behavior, including chain-of-thought prompting, pattern-aware prompting, and multi-modal approaches. They find that these methods can help, but that LLMs still struggle to reliably engage in robust, step-by-step reasoning.
The implications of this research are significant, as it suggests that current LLM technology may not be reliable or trustworthy in high-stakes applications where rigorous reasoning is essential, such as medical diagnosis, legal analysis, or scientific discovery. The authors argue that further research is needed to address these limitations and develop LLMs that can reason more robustly.
Critical Analysis
The paper raises important concerns about the reliability and trustworthiness of large language models (LLMs) in high-stakes applications. The finding that LLMs can sometimes take "shortcuts" in their reasoning, rather than following a logical chain of thought, is a significant limitation that deserves further scrutiny.
While the authors' experiments demonstrate this shortcut behavior across a range of tasks, it's worth noting that the specific prompts and datasets used may not fully capture the complexity and nuance of real-world reasoning challenges. There could be opportunities for LLMs to perform better in certain contexts or with different prompting techniques.
Additionally, the paper does not explore the potential causes of this shortcut behavior in depth. Are there inherent biases or architectural limitations in LLM design that make them prone to this type of reasoning? Or are there ways to address this through better training data, loss functions, or architectural modifications?
Further research into these questions could shed more light on the underlying mechanisms and potentially uncover avenues for improvement. Exploring how smaller, more specialized language models might complement or correct the shortcomings of large-scale LLMs could also be a fruitful direction.
Overall, this paper makes a valuable contribution by highlighting a critical limitation of current LLM technology. As these models become more widely deployed in high-stakes applications, ensuring their reasoning is robust and trustworthy will be paramount. Continued research and innovation in this area is essential to realize the full potential of large language models while mitigating their risks.
Conclusion
This paper sheds light on a concerning limitation of large language models (LLMs): their tendency to take "shortcuts" when reasoning, rather than following a logical chain of thought. The researchers demonstrate that LLMs can sometimes provide plausible-sounding answers without actually understanding the underlying concepts or logic.
This finding has significant implications for the reliability and trustworthiness of LLMs, especially in high-stakes applications where rigorous reasoning is essential, such as medical diagnosis, legal analysis, or scientific discovery. The paper explores various techniques to try to "break" this shortcut behavior, but more research is still needed to fully address the challenge.
Ultimately, this work highlights the importance of continuing to study the inner workings and limitations of LLMs, in order to develop more robust and trustworthy language models that can reliably engage in step-by-step reasoning. As these powerful AI systems become more widely deployed, ensuring their reliability and safety will be crucial for realizing their transformative potential while mitigating potential risks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting
Jianing Wang, Qiushi Sun, Xiang Li, Ming Gao
0
0
Recently, Chain-of-Thought (CoT) prompting has delivered success on complex reasoning tasks, which aims at designing a simple prompt like ``Let's think step by step'' or multiple in-context exemplars with well-designed rationales to elicit Large Language Models (LLMs) to generate intermediate reasoning steps. However, the generated rationales often come with mistakes, making unfactual and unfaithful reasoning chains. To mitigate this brittleness, we propose a novel Chain-of-Knowledge (CoK) prompting, where we aim at eliciting LLMs to generate explicit pieces of knowledge evidence in the form of structure triple. This is inspired by our human behaviors, i.e., we can draw a mind map or knowledge map as the reasoning evidence in the brain before answering a complex question. Benefiting from CoK, we additionally introduce a F^2-Verification method to estimate the reliability of the reasoning chains in terms of factuality and faithfulness. For the unreliable response, the wrong evidence can be indicated to prompt the LLM to rethink. Extensive experiments demonstrate that our method can further improve the performance of commonsense, factual, symbolic, and arithmetic reasoning tasks.
6/4/2024
🌿
Chain-of-Thought Reasoning Without Prompting
Xuezhi Wang, Denny Zhou
0
0
In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manually intensive prompt engineering. Our study takes a novel approach by asking: Can LLMs reason effectively without prompting? Our findings reveal that, intriguingly, CoT reasoning paths can be elicited from pre-trained LLMs by simply altering the textit{decoding} process. Rather than conventional greedy decoding, we investigate the top-$k$ alternative tokens, uncovering that CoT paths are frequently inherent in these sequences. This approach not only bypasses the confounders of prompting but also allows us to assess the LLMs' textit{intrinsic} reasoning abilities. Moreover, we observe that the presence of a CoT in the decoding path correlates with a higher confidence in the model's decoded answer. This confidence metric effectively differentiates between CoT and non-CoT paths. Extensive empirical studies on various reasoning benchmarks show that the proposed CoT-decoding effectively elicits reasoning capabilities from language models, which were previously obscured by standard greedy decoding.
5/27/2024
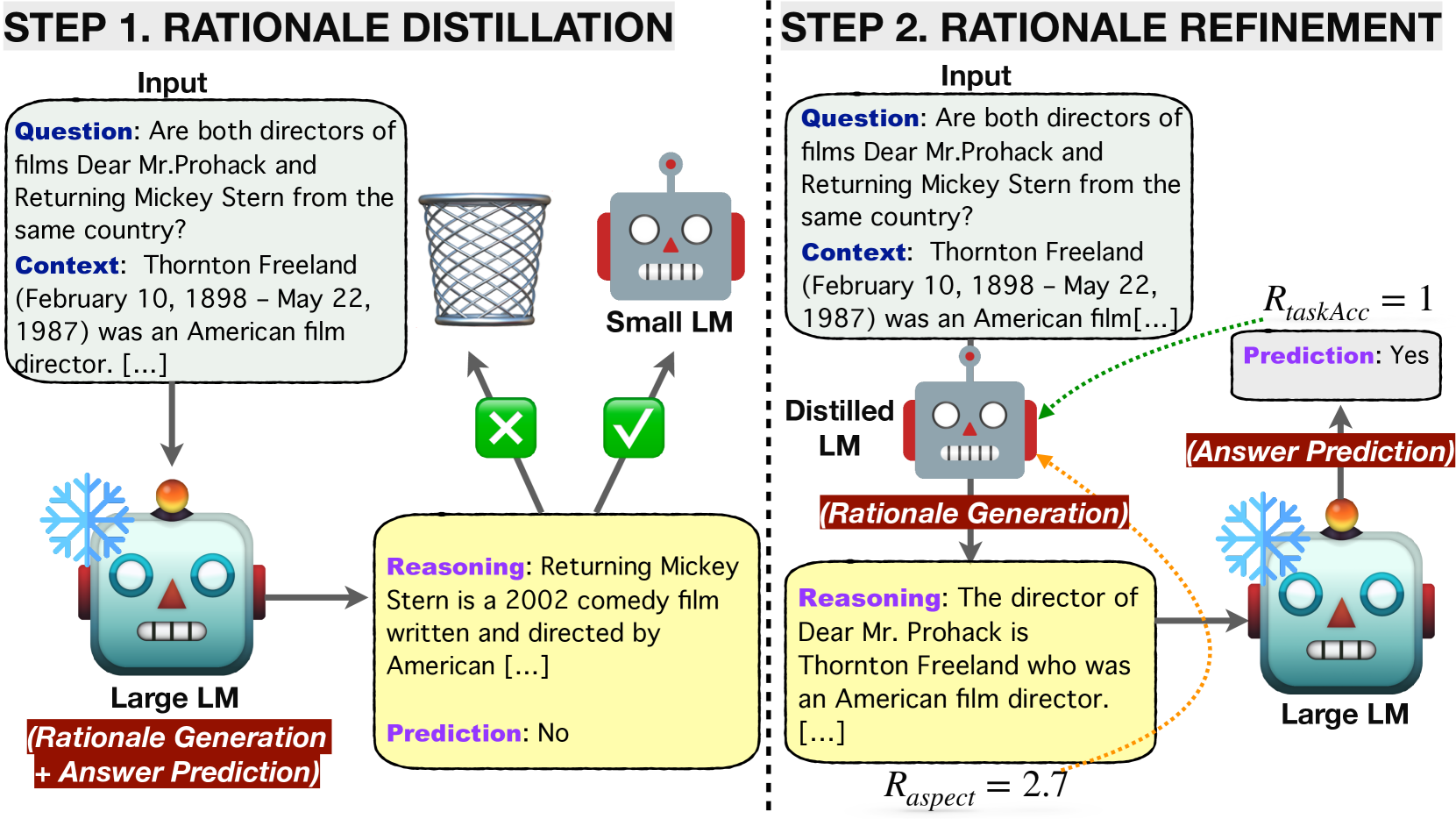
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024