Breaking Neural Network Scaling Laws with Modularity

0

Sign in to get full access
Overview
- Explores how modularity can help overcome scaling limitations in neural networks
- Proposes a novel modular network architecture that outperforms traditional monolithic models
- Demonstrates the advantages of modularity through empirical experiments and theoretical analysis
Plain English Explanation
The paper investigates how breaking neural networks into smaller, specialized modules can help overcome the scaling limitations faced by traditional monolithic models. The researchers propose a novel modular network architecture where the network is divided into distinct modules, each focused on learning a specific subtask. This modular design allows the network to scale more efficiently as it grows in size, outperforming traditional approaches.
The key idea is that by compartmentalizing the network into modules, the learning process becomes more targeted and efficient. Each module can specialize in a particular aspect of the problem, rather than having a single large network try to learn everything at once. This modularity enables the network to scale up without experiencing the diminishing returns typically seen in large monolithic models.
The paper presents empirical experiments demonstrating the advantages of the modular approach across a variety of tasks and datasets. The researchers also provide a theoretical analysis to explain the mechanisms behind the modularity-driven performance gains. The findings suggest that modular neural network architectures have the potential to break through the scaling limitations that have constrained the growth of traditional deep learning models.
Technical Explanation
The paper introduces a novel modular neural network architecture that aims to overcome the scaling limitations of traditional monolithic models. The core idea is to divide the network into distinct modules, each focused on learning a specific subtask or functionality.
The proposed architecture consists of a set of specialized modules, each with its own parameters and computational graph. These modules are connected through a set of learnable routing parameters that determine how information flows between them. This modular design allows the network to scale more efficiently as it grows in size, as each module can specialize in a particular aspect of the problem.
The researchers conducted extensive empirical experiments to evaluate the performance of the modular architecture compared to traditional monolithic models. The results show that the modular approach consistently outperforms the baseline models across a range of tasks and datasets, including image classification, language modeling, and reinforcement learning.
The paper also provides a theoretical analysis to explain the mechanisms behind the modularity-driven performance gains. The key insights are that modularity enables more targeted and efficient learning, as well as increased parameter efficiency and scalability. The modular design allows the network to avoid the diminishing returns typically seen in large monolithic models, leading to better overall performance.
Critical Analysis
The paper presents a compelling approach to overcoming the scaling limitations of traditional neural networks through the use of modularity. The modular architecture described in the paper offers a promising direction for developing more scalable and efficient deep learning models.
One potential limitation of the research is the scope of the empirical evaluation. While the experiments cover a range of tasks and datasets, it would be valuable to see the modular approach tested on even larger and more complex problems to fully assess its scalability. Additionally, the paper does not explore the potential challenges or downsides of the modular design, such as the difficulty of learning the routing parameters or the impact of module failures on overall system performance.
Another area for further research could be to investigate the interactions between the modules and how their specialization and cooperation evolves during training. Understanding these dynamics could lead to additional insights and potential improvements to the modular architecture.
Overall, the paper presents a compelling and innovative approach to neural network design that holds promise for advancing the field of deep learning. The findings suggest that modularity could be a key ingredient in developing highly scalable and efficient AI systems.
Conclusion
This paper makes a significant contribution to the field of deep learning by demonstrating how a modular neural network architecture can overcome the scaling limitations of traditional monolithic models. The proposed approach of dividing the network into specialized modules allows for more targeted and efficient learning, leading to better overall performance.
The empirical and theoretical results presented in the paper provide strong evidence for the advantages of modularity in neural network design. The modular approach holds great potential for developing scalable and versatile AI systems that can tackle increasingly complex problems. As the field of deep learning continues to advance, the insights and techniques described in this paper may play a crucial role in driving further progress and breakthroughs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Breaking Neural Network Scaling Laws with Modularity
Akhilan Boopathy, Sunshine Jiang, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
Modular neural networks outperform nonmodular neural networks on tasks ranging from visual question answering to robotics. These performance improvements are thought to be due to modular networks' superior ability to model the compositional and combinatorial structure of real-world problems. However, a theoretical explanation of how modularity improves generalizability, and how to leverage task modularity while training networks remains elusive. Using recent theoretical progress in explaining neural network generalization, we investigate how the amount of training data required to generalize on a task varies with the intrinsic dimensionality of a task's input. We show theoretically that when applied to modularly structured tasks, while nonmodular networks require an exponential number of samples with task dimensionality, modular networks' sample complexity is independent of task dimensionality: modular networks can generalize in high dimensions. We then develop a novel learning rule for modular networks to exploit this advantage and empirically show the improved generalization of the rule, both in- and out-of-distribution, on high-dimensional, modular tasks.
Read more9/10/2024
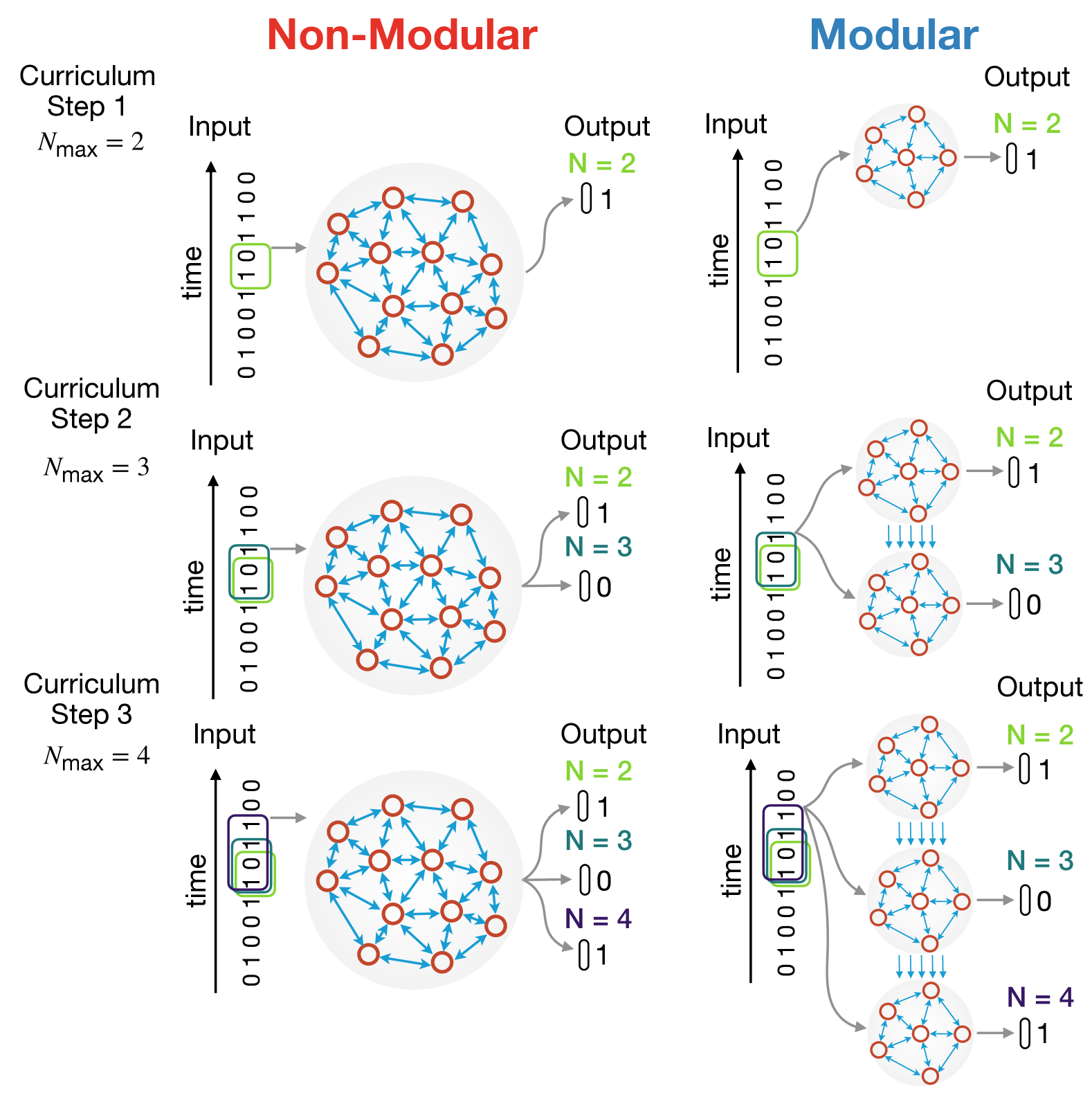
0
Modular Growth of Hierarchical Networks: Efficient, General, and Robust Curriculum Learning
Mani Hamidi, Sina Khajehabdollahi, Emmanouil Giannakakis, Tim Schafer, Anna Levina, Charley M. Wu
Structural modularity is a pervasive feature of biological neural networks, which have been linked to several functional and computational advantages. Yet, the use of modular architectures in artificial neural networks has been relatively limited despite early successes. Here, we explore the performance and functional dynamics of a modular network trained on a memory task via an iterative growth curriculum. We find that for a given classical, non-modular recurrent neural network (RNN), an equivalent modular network will perform better across multiple metrics, including training time, generalizability, and robustness to some perturbations. We further examine how different aspects of a modular network's connectivity contribute to its computational capability. We then demonstrate that the inductive bias introduced by the modular topology is strong enough for the network to perform well even when the connectivity within modules is fixed and only the connections between modules are trained. Our findings suggest that gradual modular growth of RNNs could provide advantages for learning increasingly complex tasks on evolutionary timescales, and help build more scalable and compressible artificial networks.
Read more6/11/2024

0
Grokking Modular Polynomials
Darshil Doshi, Tianyu He, Aritra Das, Andrey Gromov
Neural networks readily learn a subset of the modular arithmetic tasks, while failing to generalize on the rest. This limitation remains unmoved by the choice of architecture and training strategies. On the other hand, an analytical solution for the weights of Multi-layer Perceptron (MLP) networks that generalize on the modular addition task is known in the literature. In this work, we (i) extend the class of analytical solutions to include modular multiplication as well as modular addition with many terms. Additionally, we show that real networks trained on these datasets learn similar solutions upon generalization (grokking). (ii) We combine these expert solutions to construct networks that generalize on arbitrary modular polynomials. (iii) We hypothesize a classification of modular polynomials into learnable and non-learnable via neural networks training; and provide experimental evidence supporting our claims.
Read more6/6/2024
🛠️
0
Scalable Optimization in the Modular Norm
Tim Large, Yang Liu, Minyoung Huh, Hyojin Bahng, Phillip Isola, Jeremy Bernstein
To improve performance in contemporary deep learning, one is interested in scaling up the neural network in terms of both the number and the size of the layers. When ramping up the width of a single layer, graceful scaling of training has been linked to the need to normalize the weights and their updates in the natural norm particular to that layer. In this paper, we significantly generalize this idea by defining the modular norm, which is the natural norm on the full weight space of any neural network architecture. The modular norm is defined recursively in tandem with the network architecture itself. We show that the modular norm has several promising applications. On the practical side, the modular norm can be used to normalize the updates of any base optimizer so that the learning rate becomes transferable across width and depth. This means that the user does not need to compute optimizer-specific scale factors in order to scale training. On the theoretical side, we show that for any neural network built from well-behaved atomic modules, the gradient of the network is Lipschitz-continuous in the modular norm, with the Lipschitz constant admitting a simple recursive formula. This characterization opens the door to porting standard ideas in optimization theory over to deep learning. We have created a Python package called Modula that automatically normalizes weight updates in the modular norm of the architecture. The package is available via pip install modula with source code at https://github.com/jxbz/modula.
Read more5/24/2024