Modular Growth of Hierarchical Networks: Efficient, General, and Robust Curriculum Learning

0
Sign in to get full access
Overview
- This paper presents a novel approach for modular growth of hierarchical neural networks, enabling efficient, general, and robust curriculum learning.
- The proposed method allows neural networks to dynamically grow and adapt their structure during training, building on concepts like modular growth, structural flexibility, and modular training.
- The authors demonstrate how this approach can lead to faster training, better performance, and increased robustness, building on ideas from adaptive training and modular training.
Plain English Explanation
The paper introduces a new way to build and train neural networks that allows them to grow and adapt their structure as they learn. Rather than having a fixed network architecture, the proposed approach enables the network to dynamically add or modify its internal components (known as "modules") during the training process.
This modular growth allows the network to start simple and then become more complex over time, similar to how humans and animals learn. The network can focus on mastering basic skills first before gradually tackling more advanced tasks, a technique called "curriculum learning."
By allowing the network to continuously evolve its structure, this approach can lead to faster training times, better performance on a range of tasks, and increased robustness to changes in the input data. The authors draw inspiration from previous work on modular neural networks, structural flexibility, and adaptive training techniques to develop this novel framework.
Technical Explanation
The core idea behind the "modular growth of hierarchical networks" is to enable neural networks to dynamically expand and restructure their internal architecture during training, rather than maintaining a fixed topology.
The authors propose a hierarchical network design, where the overall network is composed of smaller, modular sub-components. These modules can be added, removed, or modified independently as the network learns, allowing it to grow in complexity over time.
To facilitate this modular growth, the authors introduce specialized training algorithms that can efficiently optimize the network structure and parameters in parallel. They also develop techniques to ensure the modules remain interpretable and generalizable, rather than becoming overly specialized.
Through extensive experiments, the researchers demonstrate that this modular growth approach leads to faster convergence, improved performance, and greater robustness compared to traditional neural network training methods. The dynamic architecture adaptation allows the network to focus on learning fundamental skills first before transitioning to more advanced capabilities, mirroring the curriculum learning process.
Critical Analysis
The key strength of this work is its ability to enable neural networks to autonomously grow and adapt their internal structure during training, which closely aligns with how biological learning systems develop. By allowing for modular expansion and restructuring, the approach can lead to more efficient and robust learning, as highlighted by the experimental results.
However, the paper does not delve deeply into the specific mechanisms underlying the modular growth process, such as the criteria for adding or removing modules, the architectural constraints, or the module interaction dynamics. Further exploration of these technical details could provide valuable insights into the design principles and tradeoffs of this framework.
Additionally, the authors primarily evaluate the method on synthetic tasks and benchmarks, which, while useful for proof-of-concept, may not fully capture the complexities of real-world applications. Validating the modular growth approach on more challenging, domain-specific problems would help assess its practical utility and generalizability.
Lastly, the paper does not address potential issues related to interpretability and explainability of the evolving network structure, which could be an important consideration for certain use cases, such as safety-critical systems or applications requiring human-understandable decision-making.
Conclusion
The "modular growth of hierarchical networks" presented in this paper represents a promising step towards developing more flexible and adaptable neural network architectures. By enabling dynamic structural evolution during training, the approach can lead to faster learning, improved performance, and increased robustness, key attributes for building advanced artificial intelligence systems.
The conceptual foundations of this work, such as modular growth, structural flexibility, and curriculum learning, have the potential to inspire further research and innovations in the field of neural network design and optimization. As the authors continue to refine and expand this framework, it could have significant implications for a wide range of AI applications, from robotics and autonomous systems to natural language processing and decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Modular Growth of Hierarchical Networks: Efficient, General, and Robust Curriculum Learning
Mani Hamidi, Sina Khajehabdollahi, Emmanouil Giannakakis, Tim Schafer, Anna Levina, Charley M. Wu
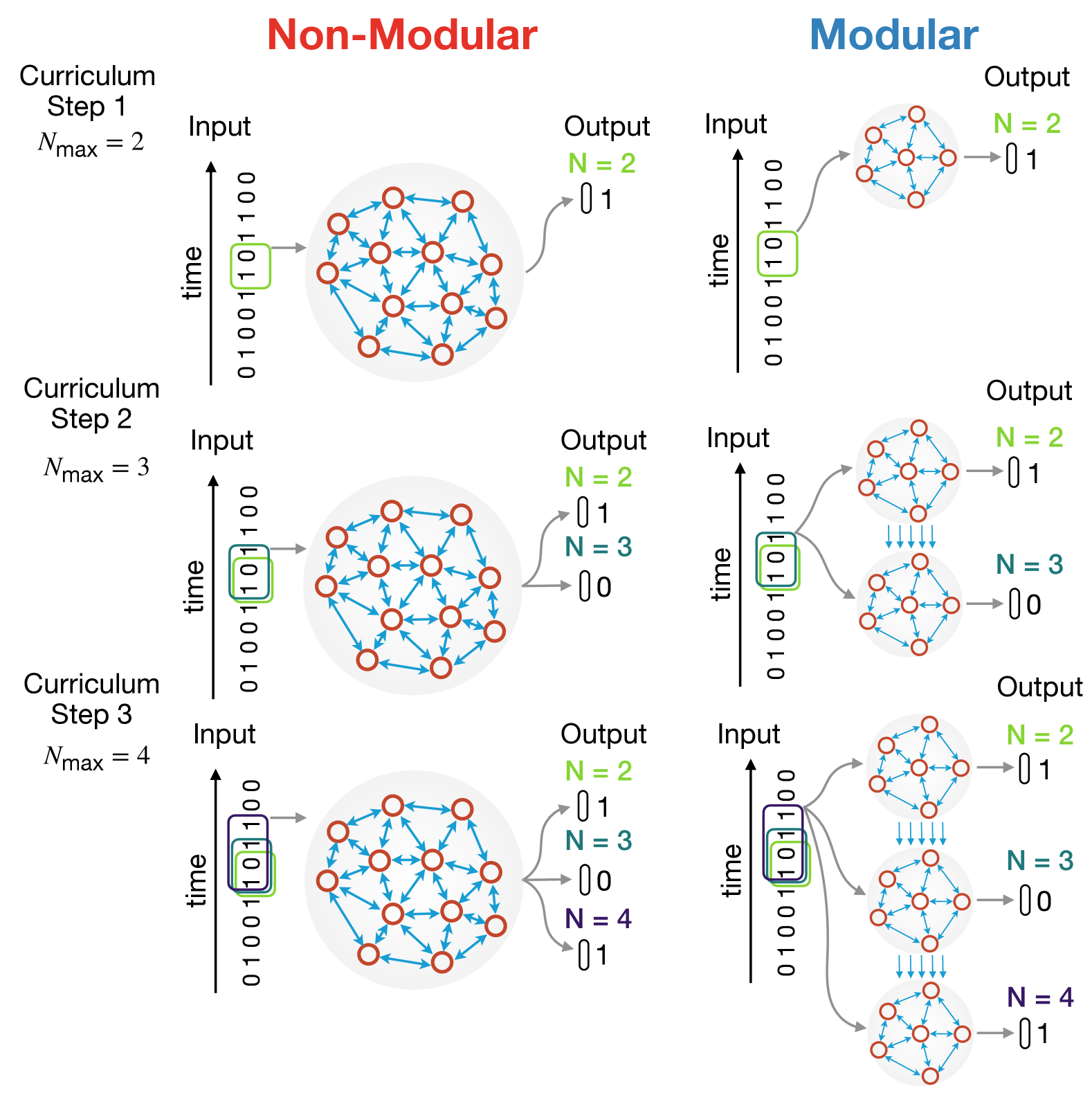
Structural modularity is a pervasive feature of biological neural networks, which have been linked to several functional and computational advantages. Yet, the use of modular architectures in artificial neural networks has been relatively limited despite early successes. Here, we explore the performance and functional dynamics of a modular network trained on a memory task via an iterative growth curriculum. We find that for a given classical, non-modular recurrent neural network (RNN), an equivalent modular network will perform better across multiple metrics, including training time, generalizability, and robustness to some perturbations. We further examine how different aspects of a modular network's connectivity contribute to its computational capability. We then demonstrate that the inductive bias introduced by the modular topology is strong enough for the network to perform well even when the connectivity within modules is fixed and only the connections between modules are trained. Our findings suggest that gradual modular growth of RNNs could provide advantages for learning increasingly complex tasks on evolutionary timescales, and help build more scalable and compressible artificial networks.
Read more6/11/2024

0
Breaking Neural Network Scaling Laws with Modularity
Akhilan Boopathy, Sunshine Jiang, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
Modular neural networks outperform nonmodular neural networks on tasks ranging from visual question answering to robotics. These performance improvements are thought to be due to modular networks' superior ability to model the compositional and combinatorial structure of real-world problems. However, a theoretical explanation of how modularity improves generalizability, and how to leverage task modularity while training networks remains elusive. Using recent theoretical progress in explaining neural network generalization, we investigate how the amount of training data required to generalize on a task varies with the intrinsic dimensionality of a task's input. We show theoretically that when applied to modularly structured tasks, while nonmodular networks require an exponential number of samples with task dimensionality, modular networks' sample complexity is independent of task dimensionality: modular networks can generalize in high dimensions. We then develop a novel learning rule for modular networks to exploit this advantage and empirically show the improved generalization of the rule, both in- and out-of-distribution, on high-dimensional, modular tasks.
Read more9/10/2024
🧠
0
Dynamics of specialization in neural modules under resource constraints
Gabriel B'ena, Dan F. M. Goodman
It has long been believed that the brain is highly modular both in terms of structure and function, although recent evidence has led some to question the extent of both types of modularity. We used artificial neural networks to test the hypothesis that structural modularity is sufficient to guarantee functional specialization, and find that in general, this doesn't necessarily hold. We then systematically tested which features of the environment and network do lead to the emergence of specialization. We used a simple toy environment, task and network, allowing us precise control, and show that in this setup, several distinct measures of specialization give qualitatively similar results. We further find that in this setup (1) specialization can only emerge in environments where features of that environment are meaningfully separable, (2) specialization preferentially emerges when the network is strongly resource-constrained, and (3) these findings are qualitatively similar across the different variations of network architectures that we tested, but that the quantitative relationships depend on the precise architecture. Finally, we show that functional specialization varies dynamically across time, and demonstrate that these dynamics depend on both the timing and bandwidth of information flow in the network. We conclude that a static notion of specialization, based on structural modularity, is likely too simple a framework for understanding intelligence in situations of real-world complexity, from biology to brain-inspired neuromorphic systems. We propose that thoroughly stress testing candidate definitions of functional modularity in simplified scenarios before extending to more complex data, network models and electrophysiological recordings is likely to be a fruitful approach.
Read more5/21/2024
🧠
0
Structurally Flexible Neural Networks: Evolving the Building Blocks for General Agents
Joachim Winther Pedersen, Erwan Plantec, Eleni Nisioti, Milton Montero, Sebastian Risi
Artificial neural networks used for reinforcement learning are structurally rigid, meaning that each optimized parameter of the network is tied to its specific placement in the network structure. It also means that a network only works with pre-defined and fixed input- and output sizes. This is a consequence of having the number of optimized parameters being directly dependent on the structure of the network. Structural rigidity limits the ability to optimize parameters of policies across multiple environments that do not share input and output spaces. Here, we evolve a set of neurons and plastic synapses each represented by a gated recurrent unit (GRU). During optimization, the parameters of these fundamental units of a neural network are optimized in different random structural configurations. Earlier work has shown that parameter sharing between units is important for making structurally flexible neurons We show that it is possible to optimize a set of distinct neuron- and synapse types allowing for a mitigation of the symmetry dilemma. We demonstrate this by optimizing a single set of neurons and synapses to solve multiple reinforcement learning control tasks simultaneously.
Read more5/20/2024