Bridging the Intent Gap: Knowledge-Enhanced Visual Generation
2405.12538
0
0
🛸
Abstract
For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.
Create account to get full access
Overview
- Discrepancies between user intentions and the generated content have been a longstanding problem in visual content generation.
- This discrepancy arises from two main factors: the inherent complexity of user intentions and the limitations of generative models' knowledge.
- To address these challenges, the paper proposes a knowledge-enhanced iterative refinement framework for visual content generation.
Plain English Explanation
When people try to create images using AI systems, they often find that the final result doesn't quite match what they had in mind. This mismatch happens for two main reasons:
-
User intentions can be very complex, with subtle details that are difficult to capture in a simple text prompt. Without this full context, the AI model struggles to generate an output that truly reflects the intended meaning.
-
The AI models used for image generation are trained on a limited set of visual-label pairs, so they lack the comprehensive knowledge needed to accurately represent all aspects of the input data. This leads to a disconnect between the desired and the generated output.
To solve these problems, the researchers propose a new approach that integrates various knowledge sources, including human insights, pre-trained models, logic rules, and general world knowledge. This "knowledge-enhanced" framework allows the AI system to iteratively refine the generated content, gradually improving the alignment between the output and the user's original intentions.
Technical Explanation
The paper begins by analyzing the key challenges faced by existing generative models in visual content generation. It identifies the two main issues as the inherent complexity of user intentions and the limitations of the models' knowledge.
To address these challenges, the researchers introduce a novel visual generation framework that incorporates a knowledge-based feedback module. This module uses various knowledge sources, such as pre-trained models, logic rules, and world knowledge, to iteratively refine the generated content and improve the alignment with the user's intentions.
The proposed framework first analyzes the user's input prompt and the generated output, then leverages the knowledge sources to identify any discrepancies or missing details. It then uses this feedback to guide the generative model in producing a new, more accurate output. This iterative refinement process continues until the generated content closely matches the user's original intentions.
Critical Analysis
The paper presents a promising approach to addressing the long-standing issue of discrepancies between user intentions and generated content in visual content generation. The incorporation of diverse knowledge sources and the iterative refinement process are both innovative and potentially effective strategies.
However, the paper does not provide a comprehensive evaluation of the proposed framework's performance or limitations. It would be valuable to see more detailed experiments, comparisons to existing methods, and discussions of potential drawbacks or areas for further research.
Additionally, the reliance on human-provided knowledge raises questions about the scalability and generalizability of the approach. Exploring ways to further automate the knowledge acquisition and integration processes could be an important next step.
Conclusion
This paper introduces a novel knowledge-enhanced iterative refinement framework for visual content generation, which aims to address the longstanding problem of discrepancies between user intentions and generated output. By leveraging diverse knowledge sources and iteratively refining the generation process, the proposed approach shows promise in improving the alignment between the desired and the generated content.
While the paper provides a solid conceptual foundation, further research is needed to fully assess the framework's performance, scalability, and practical applicability. Nonetheless, this work represents an important step towards developing more intention-aligned and comprehensive visual content generation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Generated Contents Enrichment
Mahdi Naseri, Jiayan Qiu, Zhou Wang
0
0
In this paper, we investigate a novel artificial intelligence generation task, termed as generated contents enrichment (GCE). Different from conventional artificial intelligence contents generation task that enriches the given textual description implicitly with limited semantics for generating visually real content, our proposed GCE strives to perform content enrichment explicitly on both the visual and textual domain, from which the enriched contents are visually real, structurally reasonable, and semantically abundant. Towards to solve GCE, we propose a deep end-to-end method that explicitly explores the semantics and inter-semantic relationships during the enrichment. Specifically, we first model the input description as a semantic graph, wherein each node represents an object and each edge corresponds to the inter-object relationship. We then adopt Graph Convolutional Networks on top of the input scene description to predict the enriching objects and their relationships with the input objects. Finally, the enriched description is fed into an image synthesis model to carry out the visual contents generation. Our experiments conducted on the Visual Genome dataset exhibit promising and visually plausible results.
6/12/2024
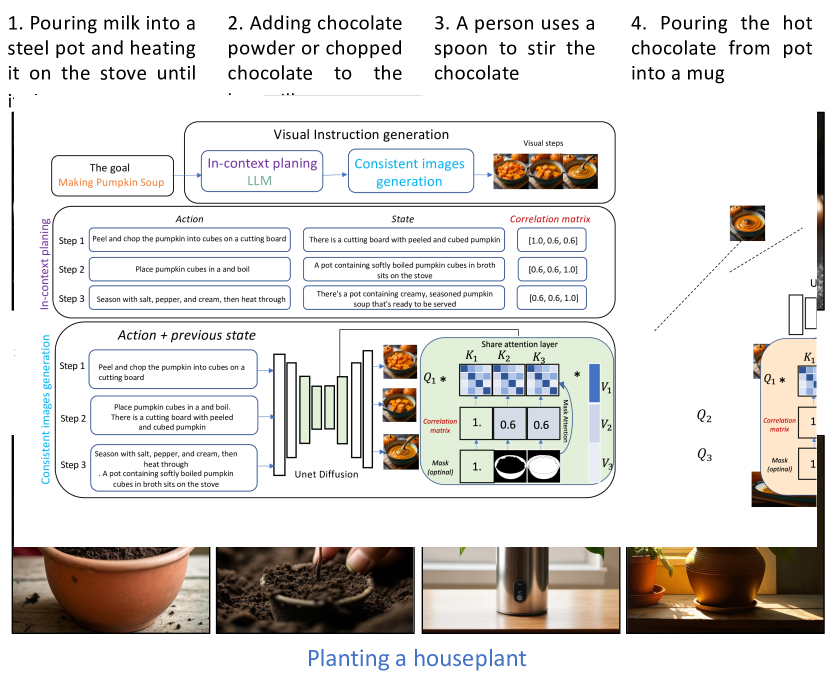
Coherent Zero-Shot Visual Instruction Generation
Quynh Phung, Songwei Ge, Jia-Bin Huang
0
0
Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
6/11/2024
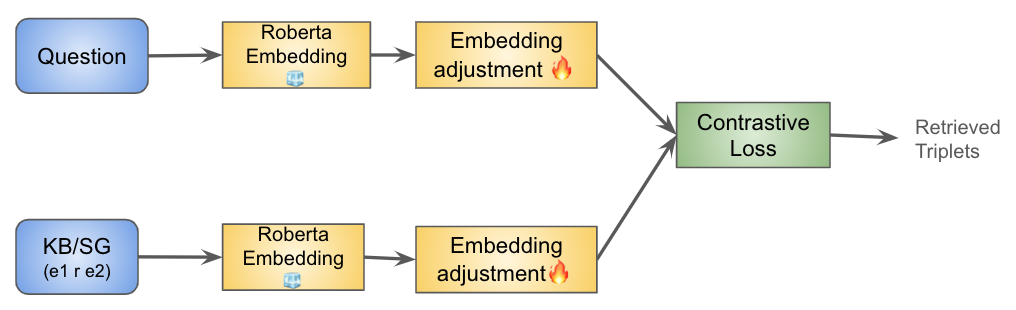
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024

Knowledge Enhanced Multi-intent Transformer Network for Recommendation
Ding Zou, Wei Wei, Feida Zhu, Chuanyu Xu, Tao Zhang, Chengfu Huo
0
0
Incorporating Knowledge Graphs into Recommendation has attracted growing attention in industry, due to the great potential of KG in providing abundant supplementary information and interpretability for the underlying models. However, simply integrating KG into recommendation usually brings in negative feedback in industry, due to the ignorance of the following two factors: i) users' multiple intents, which involve diverse nodes in KG. For example, in e-commerce scenarios, users may exhibit preferences for specific styles, brands, or colors. ii) knowledge noise, which is a prevalent issue in Knowledge Enhanced Recommendation (KGR) and even more severe in industry scenarios. The irrelevant knowledge properties of items may result in inferior model performance compared to approaches that do not incorporate knowledge. To tackle these challenges, we propose a novel approach named Knowledge Enhanced Multi-intent Transformer Network for Recommendation (KGTN), comprising two primary modules: Global Intents Modeling with Graph Transformer, and Knowledge Contrastive Denoising under Intents. Specifically, Global Intents with Graph Transformer focuses on capturing learnable user intents, by incorporating global signals from user-item-relation-entity interactions with a graph transformer, meanwhile learning intent-aware user/item representations. Knowledge Contrastive Denoising under Intents is dedicated to learning precise and robust representations. It leverages intent-aware representations to sample relevant knowledge, and proposes a local-global contrastive mechanism to enhance noise-irrelevant representation learning. Extensive experiments conducted on benchmark datasets show the superior performance of our proposed method over the state-of-the-arts. And online A/B testing results on Alibaba large-scale industrial recommendation platform also indicate the real-scenario effectiveness of KGTN.
6/3/2024