Find The Gap: Knowledge Base Reasoning For Visual Question Answering
2404.10226
0
0
Abstract
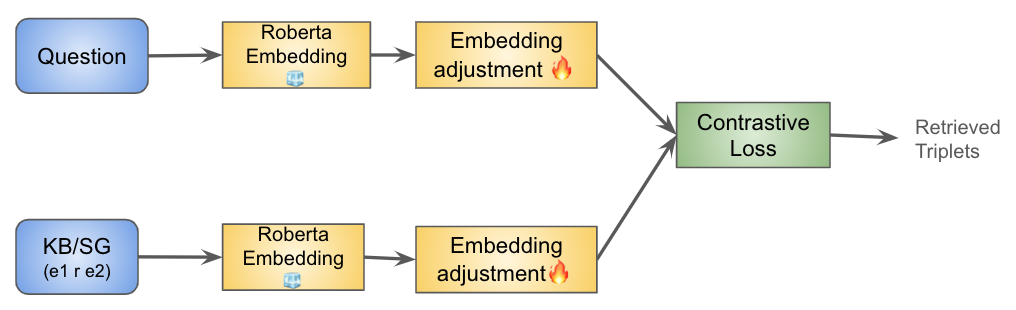
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach to visual question answering (VQA) that leverages a knowledge base to improve model performance.
- The proposed method, called "Find The Gap," aims to bridge the gap between the visual information and the knowledge required to answer questions.
- The authors demonstrate the effectiveness of their approach on various VQA datasets, showcasing significant improvements over existing methods.
Plain English Explanation
Visual question answering (VQA) is a task where a model must answer a question about an image. While recent deep learning models have made great progress in VQA, they still struggle with questions that require external knowledge beyond the image.
The "Find The Gap" method presented in this paper tries to address this issue by using a knowledge base to provide additional information to the model. The key idea is to identify the "gaps" between the visual information and the knowledge needed to answer the question, and then use the knowledge base to fill those gaps.
For example, if the question is "What type of animal is in the image?", the model might be able to recognize the visual features of the animal but still need additional information about its species to answer the question correctly. The "Find The Gap" method would use a knowledge base to provide that missing information and improve the model's ability to answer the question.
The authors show that their approach outperforms existing VQA methods on several benchmark datasets, demonstrating the value of leveraging knowledge bases to enhance visual question answering.
Technical Explanation
The paper proposes a novel architecture for visual question answering that integrates a knowledge base to address the limitations of existing VQA methods.
The key components of the "Find The Gap" model are:
- Vision-Language Encoder: This module encodes the image and question into a joint representation using a transformer-based architecture.
- Knowledge Base Retriever: This module uses the question and image features to retrieve relevant knowledge from a pre-built knowledge base.
- Knowledge Reasoning Module: This module combines the retrieved knowledge with the visual and linguistic features to reason about the correct answer.
The authors demonstrate the effectiveness of their approach on several VQA datasets, including VQAv2 and CLEVR. They show that the "Find The Gap" model outperforms state-of-the-art VQA models, especially on questions that require external knowledge beyond the image.
Critical Analysis
The paper presents a well-designed and thoughtful approach to enhancing visual question answering through the use of a knowledge base. The authors have clearly identified a key limitation of existing VQA models and have developed an effective solution to address it.
One potential area for improvement is the scalability of the knowledge base retrieval process. As the size of the knowledge base grows, the computational cost of retrieving relevant information may become a bottleneck. The authors could explore more efficient knowledge graph-based reasoning approaches to address this issue.
Additionally, the paper does not explore the potential biases that may be present in the knowledge base or how they could affect the model's performance. This is an important consideration that the authors could address in future work.
Conclusion
The "Find The Gap" approach presented in this paper is a significant contribution to the field of visual question answering. By leveraging a knowledge base to bridge the gap between visual information and the required knowledge, the model demonstrates substantial improvements over existing methods, particularly on questions that require external information.
The authors have shown the potential of integrating knowledge-based reasoning into VQA systems, and their work opens up new avenues for enhancing visual question answering through the strategic use of knowledge bases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Zeqing Wang, Wentao Wan, Qiqing Lao, Runmeng Chen, Minjie Lang, Keze Wang, Liang Lin
0
0
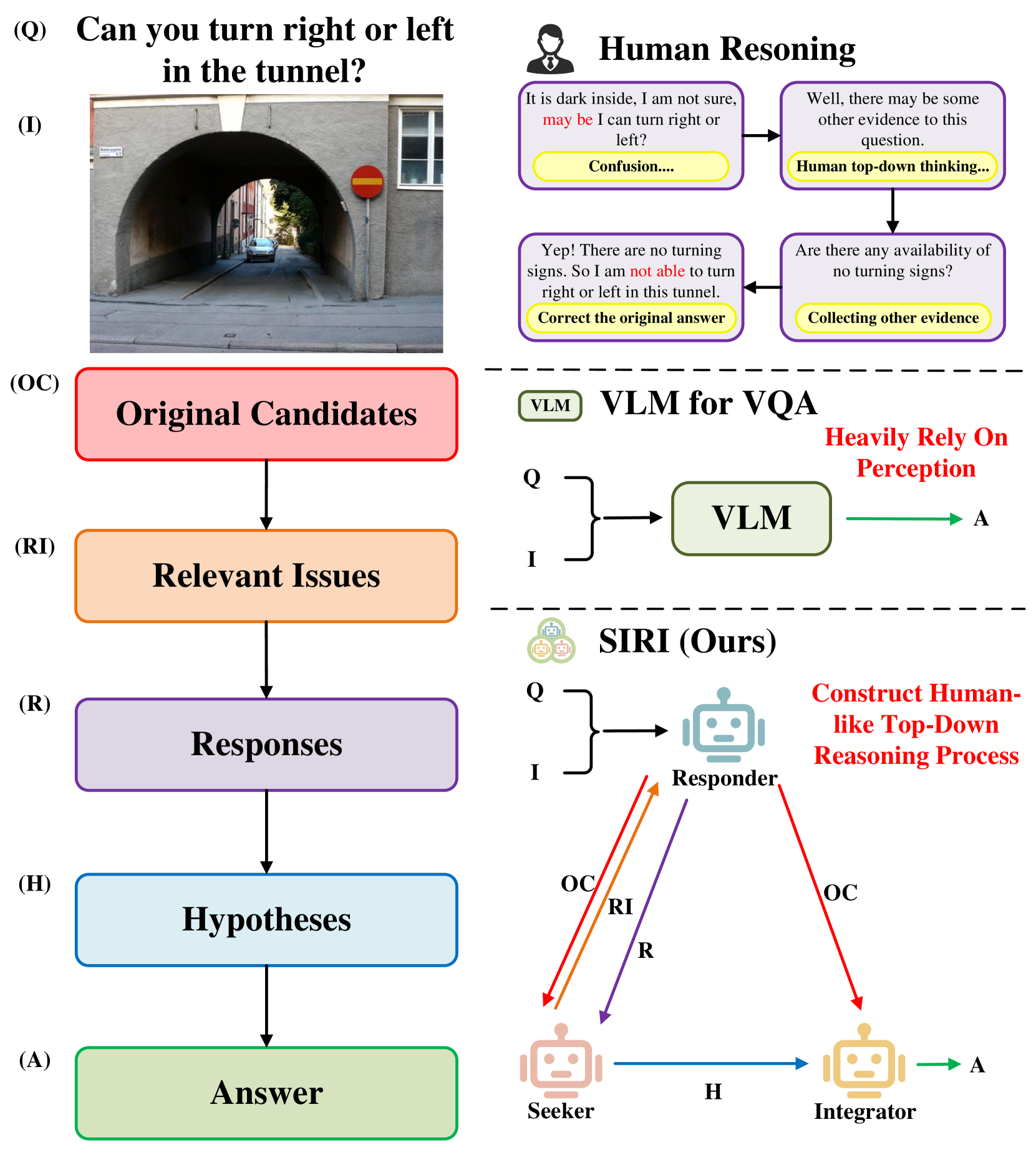
Recently, several methods have been proposed to augment large Vision Language Models (VLMs) for Visual Question Answering (VQA) simplicity by incorporating external knowledge from knowledge bases or visual clues derived from question decomposition. Although having achieved promising results, these methods still suffer from the challenge that VLMs cannot inherently understand the incorporated knowledge and might fail to generate the optimal answers. Contrarily, human cognition engages visual questions through a top-down reasoning process, systematically exploring relevant issues to derive a comprehensive answer. This not only facilitates an accurate answer but also provides a transparent rationale for the decision-making pathway. Motivated by this cognitive mechanism, we introduce a novel, explainable multi-agent collaboration framework designed to imitate human-like top-down reasoning by leveraging the expansive knowledge of Large Language Models (LLMs). Our framework comprises three agents, i.e., Responder, Seeker, and Integrator, each contributing uniquely to the top-down reasoning process. The VLM-based Responder generates the answer candidates for the question and gives responses to other issues. The Seeker, primarily based on LLM, identifies relevant issues related to the question to inform the Responder and constructs a Multi-View Knowledge Base (MVKB) for the given visual scene by leveraging the understanding capabilities of LLM. The Integrator agent combines information from the Seeker and the Responder to produce the final VQA answer. Through this collaboration mechanism, our framework explicitly constructs an MVKB for a specific visual scene and reasons answers in a top-down reasoning process. Extensive and comprehensive evaluations on diverse VQA datasets and VLMs demonstrate the superior applicability and interpretability of our framework over the existing compared methods.
5/15/2024
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
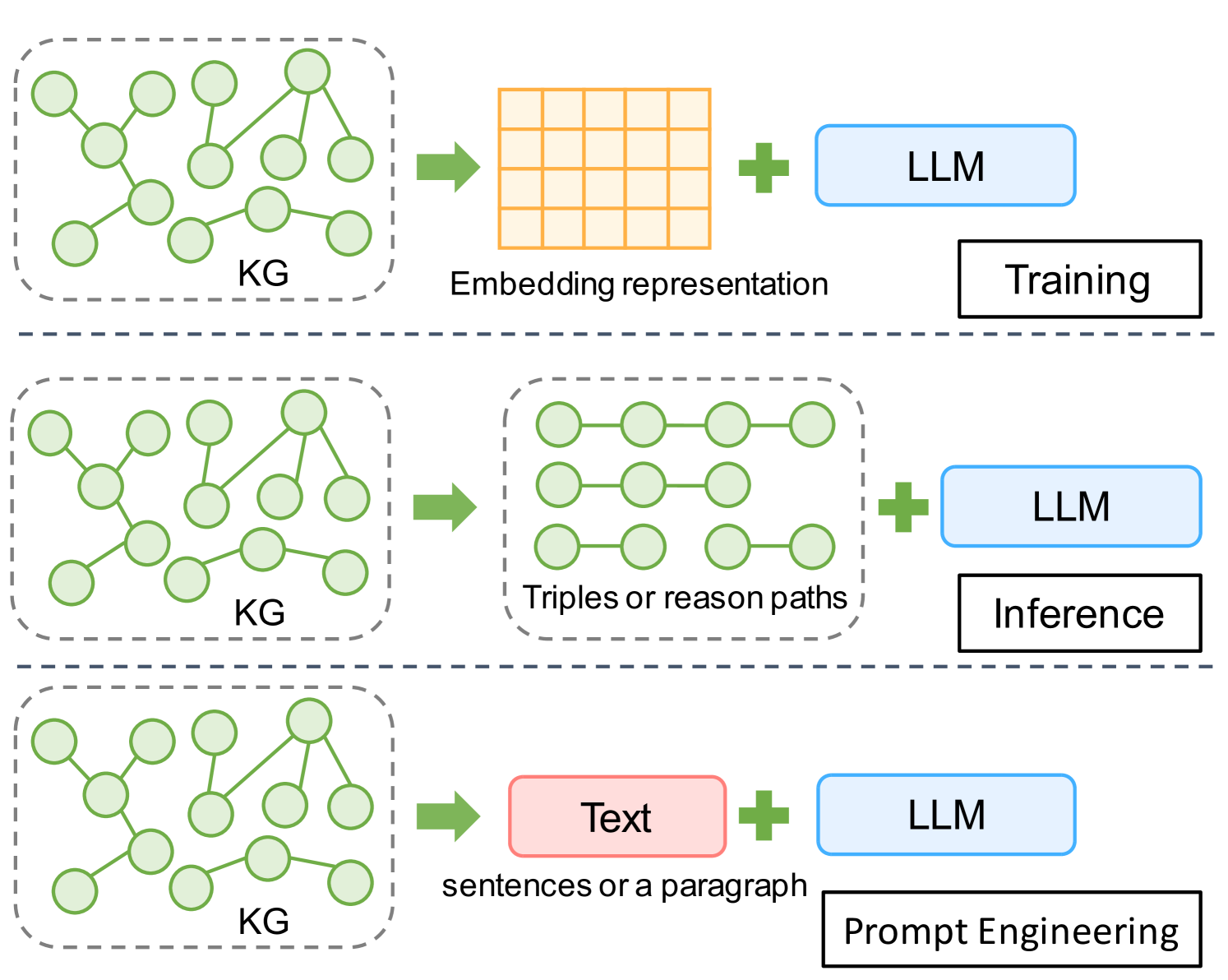
Although the method of enhancing large language models' (LLMs') reasoning ability and reducing their hallucinations through the use of knowledge graphs (KGs) has received widespread attention, the exploration of how to enable LLMs to integrate the structured knowledge in KGs on-the-fly remains inadequate. Researchers often co-train KG embeddings and LLM parameters to equip LLMs with the ability of comprehending KG knowledge. However, this resource-hungry training paradigm significantly increases the model learning cost and is also unsuitable for non-open-source, black-box LLMs. In this paper, we employ complex question answering (CQA) as a task to assess the LLM's ability of comprehending KG knowledge. We conducted a comprehensive comparison of KG knowledge injection methods (from triples to natural language text), aiming to explore the optimal prompting method for supplying KG knowledge to LLMs, thereby enhancing their comprehension of KG. Contrary to our initial expectations, our analysis revealed that LLMs effectively handle messy, noisy, and linearized KG knowledge, outperforming methods that employ well-designed natural language (NL) textual prompts. This counter-intuitive finding provides substantial insights for future research on LLMs' comprehension of structured knowledge.
4/10/2024
CuriousLLM: Elevating Multi-Document QA with Reasoning-Infused Knowledge Graph Prompting
Zukang Yang, Zixuan Zhu
0
0
In the field of Question Answering (QA), unifying large language models (LLMs) with external databases has shown great success. However, these methods often fall short in providing the advanced reasoning needed for complex QA tasks. To address these issues, we improve over a novel approach called Knowledge Graph Prompting (KGP), which combines knowledge graphs with a LLM-based agent to improve reasoning and search accuracy. Nevertheless, the original KGP framework necessitates costly fine-tuning with large datasets yet still suffers from LLM hallucination. Therefore, we propose a reasoning-infused LLM agent to enhance this framework. This agent mimics human curiosity to ask follow-up questions to more efficiently navigate the search. This simple modification significantly boosts the LLM performance in QA tasks without the high costs and latency associated with the initial KGP framework. Our ultimate goal is to further develop this approach, leading to more accurate, faster, and cost-effective solutions in the QA domain.
4/16/2024
💬
Multi-hop Question Answering over Knowledge Graphs using Large Language Models
Abir Chakraborty
0
0
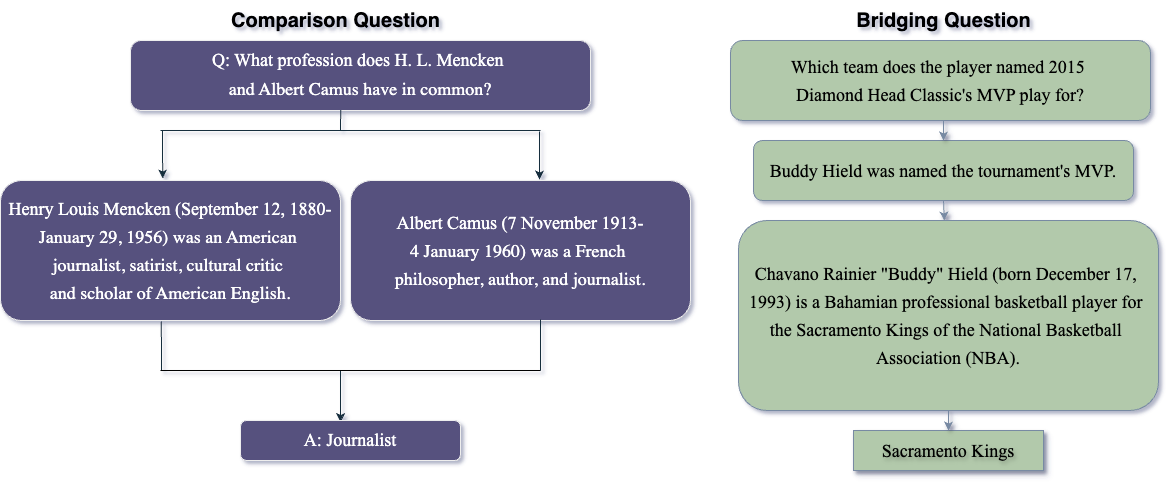
Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.
5/1/2024