Bridging Local Details and Global Context in Text-Attributed Graphs

0

Sign in to get full access
Overview
- This paper proposes a novel approach for learning representations of text-attributed graphs, which are graphs where each node is associated with text data.
- The method, called TAGA, aims to bridge the gap between local node details and global graph context by combining self-supervised learning objectives.
- The authors demonstrate the effectiveness of TAGA on several downstream tasks, including node classification, link prediction, and graph classification.
Plain English Explanation
TAGA is a machine learning technique that helps computers understand the relationships between pieces of text and the structure of the graphs they are connected to. In a text-attributed graph, each node (or data point) has both a graph structure, showing how it is connected to other nodes, and text data associated with it.
The key idea behind TAGA is to have the computer learn representations, or mathematical summaries, of these text-attributed graphs in a way that captures both the local details of the text at each node and the broader context of the overall graph structure. This is done through a process of self-supervised learning, where the computer learns useful representations by solving carefully designed "proxy" tasks, without requiring any manually labeled data.
By learning representations that bridge the local and global aspects of text-attributed graphs, TAGA enables the computer to perform well on a variety of downstream tasks, such as predicting the category of a node, predicting new connections between nodes, or classifying the overall properties of a graph. This can be useful in applications like social network analysis, recommendation systems, or document understanding.
Technical Explanation
The core of the TAGA approach is a self-supervised learning framework that jointly optimizes two complementary objectives:
- Local Text Modeling: This objective encourages the model to learn text representations that can accurately predict the text associated with each node, based on the node's graph neighbors.
- Global Graph Contrastive Learning: This objective pushes the model to learn graph-level representations that can distinguish the target graph from negative samples, by capturing the overall structure and connectivity of the graph.
By combining these local and global learning signals, TAGA aims to bridge the gap between the fine-grained textual details at the node level and the broader contextual information encoded in the graph structure.
The authors evaluate TAGA on several benchmark datasets for text-attributed graph learning, including uniGLM, GAUGE-LLM, and TAGREL. The results demonstrate that TAGA outperforms previous state-of-the-art methods on node classification, link prediction, and graph classification tasks, highlighting the benefits of the proposed approach for learning expressive representations of text-attributed graphs.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the TAGA method, considering multiple benchmark datasets and a range of downstream tasks. The authors also discuss potential limitations and areas for future work, such as extending TAGA to handle dynamic graphs or exploring alternative self-supervised learning objectives.
One potential concern is the computational complexity of the global graph contrastive learning objective, which requires generating and comparing representations for the target graph and multiple negative samples. This could limit the scalability of the approach, especially for very large graphs. The authors acknowledge this issue and suggest potential optimizations, such as using more efficient negative sampling strategies.
Additionally, while the paper demonstrates the effectiveness of TAGA on standard benchmark tasks, it would be valuable to see how the method performs on real-world applications with complex, messy, and potentially noisy text-attributed graphs. Further research could explore the robustness and practical applicability of TAGA in diverse scenarios.
Conclusion
The TAGA method proposed in this paper represents an important advance in the field of text-attributed graph learning. By combining local text modeling and global graph contrastive learning, TAGA is able to learn rich, expressive representations that capture both the fine-grained details and broader context of text-attributed graphs.
The strong empirical results on benchmark tasks suggest that TAGA could be a valuable tool for a wide range of applications, from social network analysis to document understanding. As the amount of text-rich, graph-structured data continues to grow, techniques like TAGA will become increasingly crucial for extracting meaningful insights and facilitating real-world problem-solving.
Overall, this paper makes a significant contribution to the understanding and modeling of text-attributed graphs, and the authors have provided a solid foundation for future research in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bridging Local Details and Global Context in Text-Attributed Graphs
Yaoke Wang, Yun Zhu, Wenqiao Zhang, Yueting Zhuang, Yunfei Li, Siliang Tang
Representation learning on text-attributed graphs (TAGs) is vital for real-world applications, as they combine semantic textual and contextual structural information. Research in this field generally consist of two main perspectives: local-level encoding and global-level aggregating, respectively refer to textual node information unification (e.g., using Language Models) and structure-augmented modeling (e.g., using Graph Neural Networks). Most existing works focus on combining different information levels but overlook the interconnections, i.e., the contextual textual information among nodes, which provides semantic insights to bridge local and global levels. In this paper, we propose GraphBridge, a multi-granularity integration framework that bridges local and global perspectives by leveraging contextual textual information, enhancing fine-grained understanding of TAGs. Besides, to tackle scalability and efficiency challenges, we introduce a graphaware token reduction module. Extensive experiments across various models and datasets show that our method achieves state-of-theart performance, while our graph-aware token reduction module significantly enhances efficiency and solves scalability issues.
Read more6/19/2024

0
TAGA: Text-Attributed Graph Self-Supervised Learning by Synergizing Graph and Text Mutual Transformations
Zheng Zhang, Yuntong Hu, Bo Pan, Chen Ling, Liang Zhao
Text-Attributed Graphs (TAGs) enhance graph structures with natural language descriptions, enabling detailed representation of data and their relationships across a broad spectrum of real-world scenarios. Despite the potential for deeper insights, existing TAG representation learning primarily relies on supervised methods, necessitating extensive labeled data and limiting applicability across diverse contexts. This paper introduces a new self-supervised learning framework, Text-And-Graph Multi-View Alignment (TAGA), which overcomes these constraints by integrating TAGs' structural and semantic dimensions. TAGA constructs two complementary views: Text-of-Graph view, which organizes node texts into structured documents based on graph topology, and the Graph-of-Text view, which converts textual nodes and connections into graph data. By aligning representations from both views, TAGA captures joint textual and structural information. In addition, a novel structure-preserving random walk algorithm is proposed for efficient training on large-sized TAGs. Our framework demonstrates strong performance in zero-shot and few-shot scenarios across eight real-world datasets.
Read more5/28/2024
🛸
0
CADGE: Context-Aware Dialogue Generation Enhanced with Graph-Structured Knowledge Aggregation
Hongbo Zhang, Chen Tang, Tyler Loakman, Chenghua Lin, Stefan Goetze
Commonsense knowledge is crucial to many natural language processing tasks. Existing works usually incorporate graph knowledge with conventional graph neural networks (GNNs), leading to the text and graph knowledge encoding processes being separated in a serial pipeline. We argue that these separate representation learning stages may be suboptimal for neural networks to learn the overall context contained in both types of input knowledge. In this paper, we propose a novel context-aware graph-attention model (Context-aware GAT), which can effectively incorporate global features of relevant knowledge graphs based on a context-enhanced knowledge aggregation process. Specifically, our framework leverages a novel representation learning approach to process heterogeneous features - combining flattened graph knowledge with text. To the best of our knowledge, this is the first attempt at hierarchically applying graph knowledge aggregation on a connected subgraph in addition to contextual information to support commonsense dialogue generation. This framework shows superior performance compared to conventional GNN-based language frameworks. Both automatic and human evaluation demonstrates that our proposed model has significant performance uplifts over state-of-the-art baselines.
Read more9/5/2024
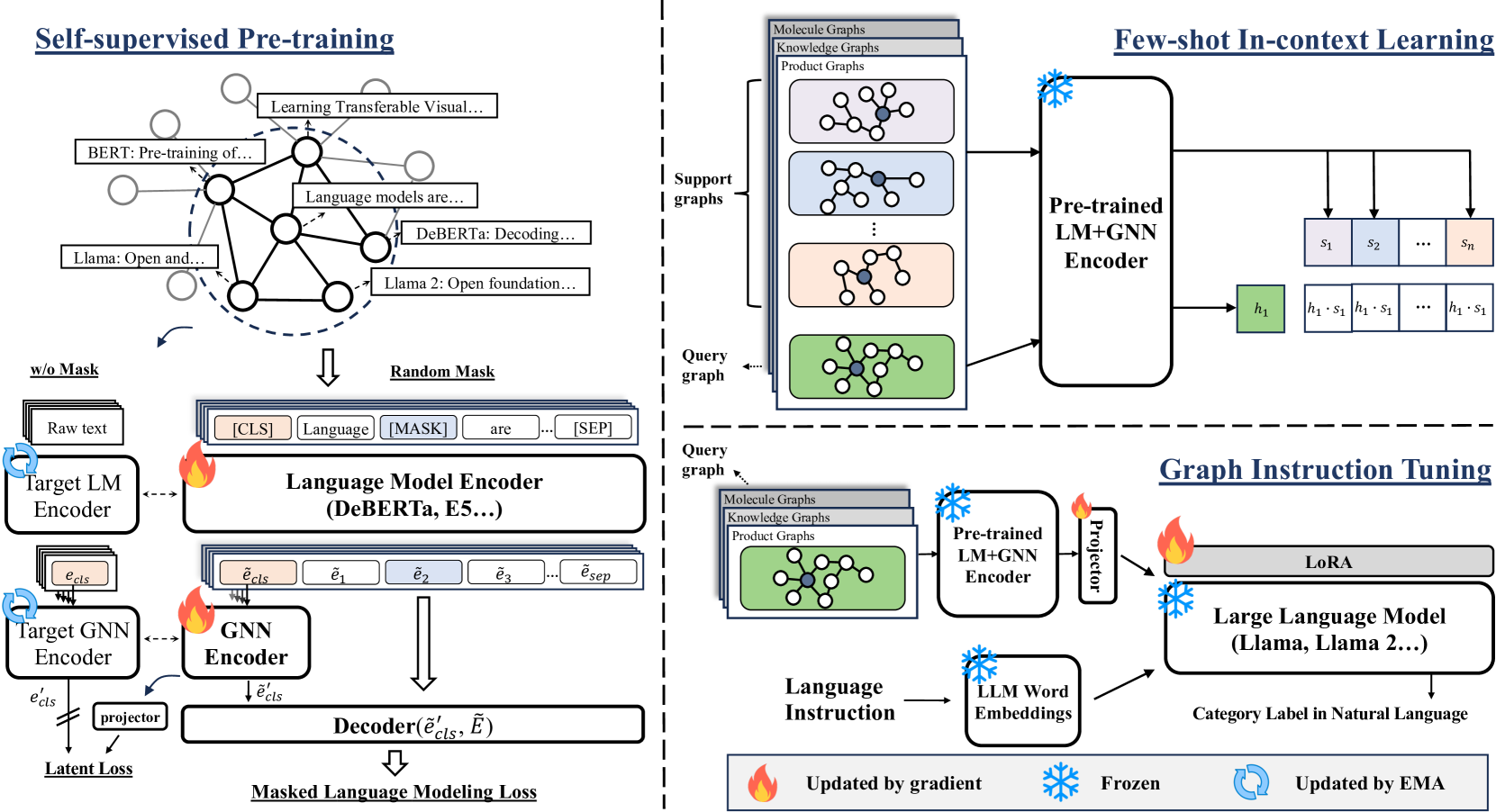
0
UniGraph: Learning a Unified Cross-Domain Foundation Model for Text-Attributed Graphs
Yufei He, Yuan Sui, Xiaoxin He, Bryan Hooi
Foundation models like ChatGPT and GPT-4 have revolutionized artificial intelligence, exhibiting remarkable abilities to generalize across a wide array of tasks and applications beyond their initial training objectives. However, graph learning has predominantly focused on single-graph models, tailored to specific tasks or datasets, lacking the ability to transfer learned knowledge to different domains. This limitation stems from the inherent complexity and diversity of graph structures, along with the different feature and label spaces specific to graph data. In this paper, we recognize text as an effective unifying medium and employ Text-Attributed Graphs (TAGs) to leverage this potential. We present our UniGraph framework, designed to learn a foundation model for TAGs, which is capable of generalizing to unseen graphs and tasks across diverse domains. Unlike single-graph models that use pre-computed node features of varying dimensions as input, our approach leverages textual features for unifying node representations, even for graphs such as molecular graphs that do not naturally have textual features. We propose a novel cascaded architecture of Language Models (LMs) and Graph Neural Networks (GNNs) as backbone networks. Additionally, we propose the first pre-training algorithm specifically designed for large-scale self-supervised learning on TAGs, based on Masked Graph Modeling. We introduce graph instruction tuning using Large Language Models (LLMs) to enable zero-shot prediction ability. Our comprehensive experiments across various graph learning tasks and domains demonstrate the model's effectiveness in self-supervised representation learning on unseen graphs, few-shot in-context transfer, and zero-shot transfer, even surpassing or matching the performance of GNNs that have undergone supervised training on target datasets.
Read more8/27/2024