Bringing Masked Autoencoders Explicit Contrastive Properties for Point Cloud Self-Supervised Learning

0
Sign in to get full access
Overview
- This paper introduces a novel self-supervised learning approach for point cloud data called "Bringing Masked Autoencoders Explicit Contrastive Properties" (BMAEC).
- BMAEC combines the benefits of masked autoencoders and contrastive learning to improve the performance of self-supervised learning on point cloud data.
- The authors demonstrate that BMAEC outperforms previous state-of-the-art self-supervised methods for point cloud understanding tasks.
Plain English Explanation
The paper presents a new way to learn useful features from 3D point cloud data without needing labeled examples. This is called self-supervised learning, and it's helpful because collecting labeled 3D data can be very difficult and expensive.
The key idea behind BMAEC is to combine two powerful techniques: masked autoencoders and contrastive learning. Masked autoencoders work by hiding (or "masking") parts of the input data and then training the model to predict the missing parts. Contrastive learning involves training the model to recognize when two inputs are similar or different, even without labels.
By bringing these two approaches together, the authors show that the model can learn rich, discriminative features from 3D point cloud data. These learned features can then be used to improve performance on a variety of downstream tasks, like 3D object classification or part segmentation.
The authors demonstrate that BMAEC outperforms previous state-of-the-art self-supervised methods for point cloud understanding. This is an important advance, as it suggests that BMAEC could be a valuable tool for leveraging the wealth of unlabeled 3D data available to build more capable AI systems.
Technical Explanation
The core of the BMAEC approach is to combine the strengths of masked autoencoders and contrastive learning. Masked autoencoders work by randomly masking out a portion of the input point cloud and then training the model to predict the missing points. This encourages the model to learn rich, contextual representations of the 3D structure.
Contrastive learning, on the other hand, trains the model to recognize when two inputs are similar or different, even without labels. This helps the model learn discriminative features that can be useful for downstream tasks.
By incorporating both of these techniques, BMAEC is able to learn features that are not only expressive of the 3D structure, but also highly discriminative. The authors demonstrate this through extensive experiments on various point cloud understanding tasks, where BMAEC outperforms previous state-of-the-art self-supervised methods.
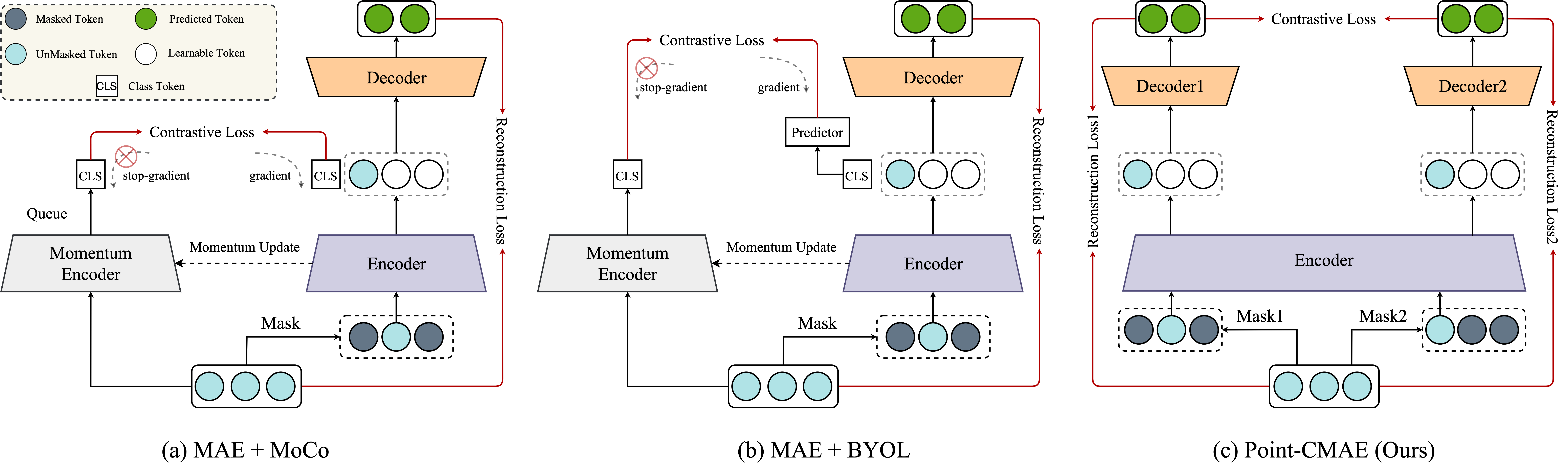
One key innovation in BMAEC is the introduction of "explicit contrastive properties." This means that the model is trained to not only reconstruct the masked points, but also to explicitly contrast the representation of the masked points with the representation of the unmasked points. This additional contrastive objective further boosts the model's ability to learn useful features.
The authors also show that the learned features from BMAEC can be effectively visualized, providing insights into what the model has learned. Additionally, they demonstrate that the BMAEC pre-training approach can be effectively combined with self-supervised vision transformers for even better performance on downstream tasks.
Critical Analysis
The BMAEC approach represents a promising advance in self-supervised learning for point cloud data. By combining masked autoencoders and contrastive learning, the authors are able to learn features that are both expressive of the 3D structure and highly discriminative.
One potential limitation of the work is that it has only been evaluated on relatively small-scale point cloud datasets. It would be interesting to see how BMAEC performs on larger and more diverse point cloud datasets, such as those encountered in real-world applications.
Additionally, the authors do not provide a deep analysis of the types of features learned by BMAEC or how they differ from features learned by other self-supervised approaches. A more detailed exploration of the learned representations could provide valuable insights into the strengths and weaknesses of the method.
Overall, BMAEC represents an important step forward in self-supervised learning for point cloud data, and the authors have made a compelling case for its effectiveness. With further research and development, this approach could become a valuable tool for building more capable 3D perception systems.
Conclusion
This paper introduces a novel self-supervised learning approach for point cloud data called "Bringing Masked Autoencoders Explicit Contrastive Properties" (BMAEC). BMAEC combines the benefits of masked autoencoders and contrastive learning to learn rich, discriminative features from 3D point cloud data without the need for labeled examples.
The authors demonstrate that BMAEC outperforms previous state-of-the-art self-supervised methods for a variety of point cloud understanding tasks, suggesting that it could be a valuable tool for leveraging the wealth of unlabeled 3D data available. While the approach has some limitations that merit further investigation, BMAEC represents an important advance in the field of self-supervised learning for 3D perception.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bringing Masked Autoencoders Explicit Contrastive Properties for Point Cloud Self-Supervised Learning
Bin Ren, Guofeng Mei, Danda Pani Paudel, Weijie Wang, Yawei Li, Mengyuan Liu, Rita Cucchiara, Luc Van Gool, Nicu Sebe
Contrastive learning (CL) for Vision Transformers (ViTs) in image domains has achieved performance comparable to CL for traditional convolutional backbones. However, in 3D point cloud pretraining with ViTs, masked autoencoder (MAE) modeling remains dominant. This raises the question: Can we take the best of both worlds? To answer this question, we first empirically validate that integrating MAE-based point cloud pre-training with the standard contrastive learning paradigm, even with meticulous design, can lead to a decrease in performance. To address this limitation, we reintroduce CL into the MAE-based point cloud pre-training paradigm by leveraging the inherent contrastive properties of MAE. Specifically, rather than relying on extensive data augmentation as commonly used in the image domain, we randomly mask the input tokens twice to generate contrastive input pairs. Subsequently, a weight-sharing encoder and two identically structured decoders are utilized to perform masked token reconstruction. Additionally, we propose that for an input token masked by both masks simultaneously, the reconstructed features should be as similar as possible. This naturally establishes an explicit contrastive constraint within the generative MAE-based pre-training paradigm, resulting in our proposed method, Point-CMAE. Consequently, Point-CMAE effectively enhances the representation quality and transfer performance compared to its MAE counterpart. Experimental evaluations across various downstream applications, including classification, part segmentation, and few-shot learning, demonstrate the efficacy of our framework in surpassing state-of-the-art techniques under standard ViTs and single-modal settings. The source code and trained models are available at: https://github.com/Amazingren/Point-CMAE.
Read more7/9/2024
✨
0
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Siming Yan, Yuqi Yang, Yuxiao Guo, Hao Pan, Peng-shuai Wang, Xin Tong, Yang Liu, Qixing Huang
Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.
Read more4/30/2024

0
ExpPoint-MAE: Better interpretability and performance for self-supervised point cloud transformers
Ioannis Romanelis, Vlassis Fotis, Konstantinos Moustakas, Adrian Munteanu
In this paper we delve into the properties of transformers, attained through self-supervision, in the point cloud domain. Specifically, we evaluate the effectiveness of Masked Autoencoding as a pretraining scheme, and explore Momentum Contrast as an alternative. In our study we investigate the impact of data quantity on the learned features, and uncover similarities in the transformer's behavior across domains. Through comprehensive visualiations, we observe that the transformer learns to attend to semantically meaningful regions, indicating that pretraining leads to a better understanding of the underlying geometry. Moreover, we examine the finetuning process and its effect on the learned representations. Based on that, we devise an unfreezing strategy which consistently outperforms our baseline without introducing any other modifications to the model or the training pipeline, and achieve state-of-the-art results in the classification task among transformer models.
Read more4/11/2024

0
Contrastive masked auto-encoders based self-supervised hashing for 2D image and 3D point cloud cross-modal retrieval
Rukai Wei, Heng Cui, Yu Liu, Yufeng Hou, Yanzhao Xie, Ke Zhou
Implementing cross-modal hashing between 2D images and 3D point-cloud data is a growing concern in real-world retrieval systems. Simply applying existing cross-modal approaches to this new task fails to adequately capture latent multi-modal semantics and effectively bridge the modality gap between 2D and 3D. To address these issues without relying on hand-crafted labels, we propose contrastive masked autoencoders based self-supervised hashing (CMAH) for retrieval between images and point-cloud data. We start by contrasting 2D-3D pairs and explicitly constraining them into a joint Hamming space. This contrastive learning process ensures robust discriminability for the generated hash codes and effectively reduces the modality gap. Moreover, we utilize multi-modal auto-encoders to enhance the model's understanding of multi-modal semantics. By completing the masked image/point-cloud data modeling task, the model is encouraged to capture more localized clues. In addition, the proposed multi-modal fusion block facilitates fine-grained interactions among different modalities. Extensive experiments on three public datasets demonstrate that the proposed CMAH significantly outperforms all baseline methods.
Read more8/13/2024