Contrastive masked auto-encoders based self-supervised hashing for 2D image and 3D point cloud cross-modal retrieval

0

Sign in to get full access
Overview
- This paper presents a novel approach for cross-modal retrieval between 2D images and 3D point clouds.
- The method uses contrastive masked auto-encoders for self-supervised hashing, allowing the model to learn joint representations for the two modalities.
- Experiments demonstrate the effectiveness of the proposed approach for 2D-3D cross-modal retrieval tasks.
Plain English Explanation
The research paper introduces a new technique for searching and retrieving data across different types of media, specifically 2D images and 3D point clouds. The key idea is to use a type of machine learning called "self-supervised hashing" to learn a shared representation, or encoding, that can capture the similarities between the two modalities.
The self-supervised hashing approach involves training an "auto-encoder" model to reconstruct the input data, but with some parts of the input deliberately masked or hidden. By learning to fill in the missing information, the model is forced to capture the essential features and relationships in the data. This process happens without any human-labeled training data, which is the "self-supervised" aspect.
The authors then add a "contrastive" component, where the model also learns to distinguish between related and unrelated pairs of 2D and 3D data. This helps the shared representation become even more effective at bridging the gap between the two modalities.
The end result is a system that can take a 2D image as input and retrieve relevant 3D point cloud data, or vice versa. This has applications in areas like link to 'cross-modal retrieval' where information needs to be seamlessly accessed across different data formats.
Technical Explanation
The paper proposes a link to 'contrastive masked auto-encoders' framework for cross-modal retrieval between 2D images and 3D point clouds. The key components are:
-
Masked Auto-Encoder: The model is trained to reconstruct input data (either 2D or 3D) from a partially masked version. This forces the encoder to learn a compact, meaningful representation of the input.
-
Contrastive Learning: In addition to reconstruction, the model also learns to distinguish between related and unrelated pairs of 2D-3D data. This helps align the representations across modalities.
-
Joint Embedding: The trained encoder produces a shared latent representation for both 2D images and 3D point clouds. This enables cross-modal retrieval by finding the closest matches in the joint embedding space.
The authors evaluate their approach on several 2D-3D cross-modal retrieval benchmarks, demonstrating state-of-the-art performance. They also provide ablation studies to understand the contributions of the different components of their framework.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed approach. The authors acknowledge some limitations, such as the need for a large amount of training data and the potential impact of dataset biases. Further research could explore ways to link to '3D feature prediction masked autoencoder' make the model more sample-efficient or robust to dataset shifts.
Additionally, the authors could have discussed potential societal implications of cross-modal retrieval technologies, such as privacy concerns or potential misuse. A more in-depth discussion of the broader context and real-world applications of this work would have been valuable.
Conclusion
This paper presents a novel contrastive masked auto-encoder approach for cross-modal retrieval between 2D images and 3D point clouds. The self-supervised learning framework enables the model to learn a joint representation that can effectively bridge the gap between the two modalities.
The demonstrated performance improvements on benchmark tasks highlight the potential of this technique for applications where seamless access to information across different data formats is required, such as link to 'cross-modal self-training' or link to 'sensor-agnostic image retrieval'. Further research in this direction could lead to more robust and versatile cross-modal retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contrastive masked auto-encoders based self-supervised hashing for 2D image and 3D point cloud cross-modal retrieval
Rukai Wei, Heng Cui, Yu Liu, Yufeng Hou, Yanzhao Xie, Ke Zhou
Implementing cross-modal hashing between 2D images and 3D point-cloud data is a growing concern in real-world retrieval systems. Simply applying existing cross-modal approaches to this new task fails to adequately capture latent multi-modal semantics and effectively bridge the modality gap between 2D and 3D. To address these issues without relying on hand-crafted labels, we propose contrastive masked autoencoders based self-supervised hashing (CMAH) for retrieval between images and point-cloud data. We start by contrasting 2D-3D pairs and explicitly constraining them into a joint Hamming space. This contrastive learning process ensures robust discriminability for the generated hash codes and effectively reduces the modality gap. Moreover, we utilize multi-modal auto-encoders to enhance the model's understanding of multi-modal semantics. By completing the masked image/point-cloud data modeling task, the model is encouraged to capture more localized clues. In addition, the proposed multi-modal fusion block facilitates fine-grained interactions among different modalities. Extensive experiments on three public datasets demonstrate that the proposed CMAH significantly outperforms all baseline methods.
Read more8/13/2024
0
Bringing Masked Autoencoders Explicit Contrastive Properties for Point Cloud Self-Supervised Learning
Bin Ren, Guofeng Mei, Danda Pani Paudel, Weijie Wang, Yawei Li, Mengyuan Liu, Rita Cucchiara, Luc Van Gool, Nicu Sebe
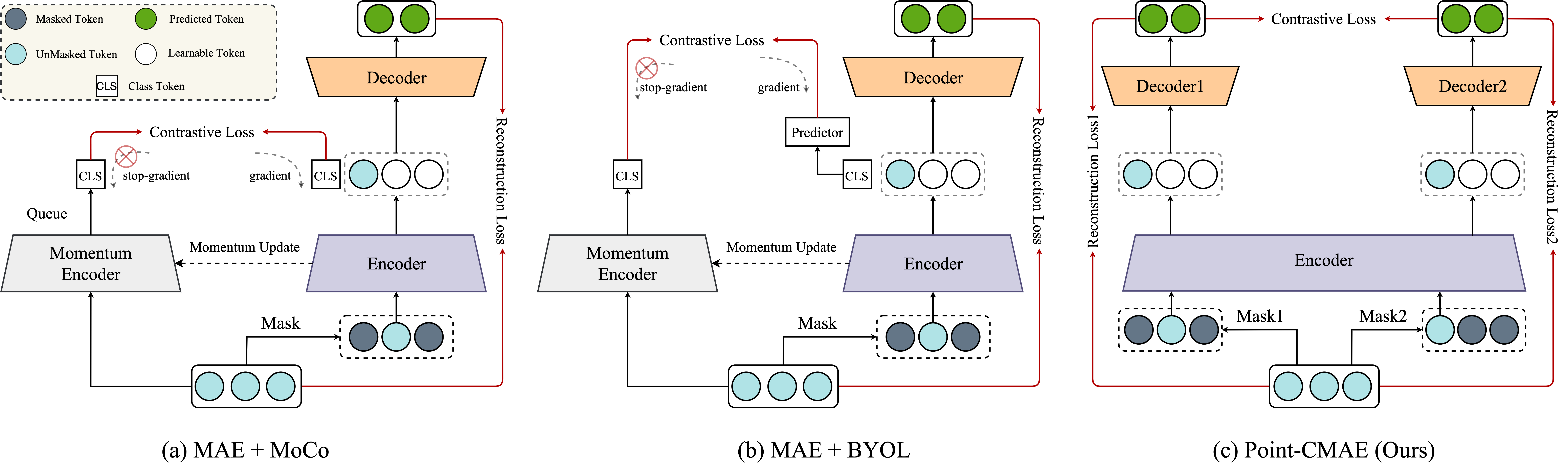
Contrastive learning (CL) for Vision Transformers (ViTs) in image domains has achieved performance comparable to CL for traditional convolutional backbones. However, in 3D point cloud pretraining with ViTs, masked autoencoder (MAE) modeling remains dominant. This raises the question: Can we take the best of both worlds? To answer this question, we first empirically validate that integrating MAE-based point cloud pre-training with the standard contrastive learning paradigm, even with meticulous design, can lead to a decrease in performance. To address this limitation, we reintroduce CL into the MAE-based point cloud pre-training paradigm by leveraging the inherent contrastive properties of MAE. Specifically, rather than relying on extensive data augmentation as commonly used in the image domain, we randomly mask the input tokens twice to generate contrastive input pairs. Subsequently, a weight-sharing encoder and two identically structured decoders are utilized to perform masked token reconstruction. Additionally, we propose that for an input token masked by both masks simultaneously, the reconstructed features should be as similar as possible. This naturally establishes an explicit contrastive constraint within the generative MAE-based pre-training paradigm, resulting in our proposed method, Point-CMAE. Consequently, Point-CMAE effectively enhances the representation quality and transfer performance compared to its MAE counterpart. Experimental evaluations across various downstream applications, including classification, part segmentation, and few-shot learning, demonstrate the efficacy of our framework in surpassing state-of-the-art techniques under standard ViTs and single-modal settings. The source code and trained models are available at: https://github.com/Amazingren/Point-CMAE.
Read more7/9/2024

0
Cross-Modal Self-Supervised Learning with Effective Contrastive Units for LiDAR Point Clouds
Mu Cai, Chenxu Luo, Yong Jae Lee, Xiaodong Yang
3D perception in LiDAR point clouds is crucial for a self-driving vehicle to properly act in 3D environment. However, manually labeling point clouds is hard and costly. There has been a growing interest in self-supervised pre-training of 3D perception models. Following the success of contrastive learning in images, current methods mostly conduct contrastive pre-training on point clouds only. Yet an autonomous driving vehicle is typically supplied with multiple sensors including cameras and LiDAR. In this context, we systematically study single modality, cross-modality, and multi-modality for contrastive learning of point clouds, and show that cross-modality wins over other alternatives. In addition, considering the huge difference between the training sources in 2D images and 3D point clouds, it remains unclear how to design more effective contrastive units for LiDAR. We therefore propose the instance-aware and similarity-balanced contrastive units that are tailored for self-driving point clouds. Extensive experiments reveal that our approach achieves remarkable performance gains over various point cloud models across the downstream perception tasks of LiDAR based 3D object detection and 3D semantic segmentation on the four popular benchmarks including Waymo Open Dataset, nuScenes, SemanticKITTI and ONCE.
Read more9/12/2024

0
COM3D: Leveraging Cross-View Correspondence and Cross-Modal Mining for 3D Retrieval
Hao Wu, Ruochong LI, Hao Wang, Hui Xiong
In this paper, we investigate an open research task of cross-modal retrieval between 3D shapes and textual descriptions. Previous approaches mainly rely on point cloud encoders for feature extraction, which may ignore key inherent features of 3D shapes, including depth, spatial hierarchy, geometric continuity, etc. To address this issue, we propose COM3D, making the first attempt to exploit the cross-view correspondence and cross-modal mining to enhance the retrieval performance. Notably, we augment the 3D features through a scene representation transformer, to generate cross-view correspondence features of 3D shapes, which enrich the inherent features and enhance their compatibility with text matching. Furthermore, we propose to optimize the cross-modal matching process based on the semi-hard negative example mining method, in an attempt to improve the learning efficiency. Extensive quantitative and qualitative experiments demonstrate the superiority of our proposed COM3D, achieving state-of-the-art results on the Text2Shape dataset.
Read more5/8/2024