BSC-UPC at EmoSPeech-IberLEF2024: Attention Pooling for Emotion Recognition

0

Sign in to get full access
Overview
- This paper presents a model developed by the BSC-UPC team for the EmoSPeech-IberLEF2024 challenge on emotional speech recognition.
- The key idea is to use attention pooling to aggregate the information from different parts of the speech signal and improve emotion recognition performance.
- The model was evaluated on the EmoSPeech-IberLEF2024 dataset, which contains speech recordings labeled with different emotional states.
Plain English Explanation
The paper describes a machine learning model that was designed to recognize the emotional state of a person based on their speech. The researchers from BSC-UPC used a technique called "attention pooling" to help their model better understand the emotional content of the speech.
Attention pooling works by allowing the model to focus on the parts of the speech signal that are most important for determining the emotion, rather than treating all parts of the signal equally. This helps the model pick up on subtle cues and nuances that might be missed otherwise.
The researchers tested their model on a dataset of speech recordings that had been labeled with different emotional states, such as happiness, sadness, anger, and so on. By using attention pooling, the model was able to achieve better performance in recognizing the emotions compared to other approaches.
This work is significant because being able to automatically recognize the emotional state of a person from their speech has many potential applications, such as in customer service, mental health monitoring, and human-computer interaction. The attention pooling technique used in this paper could be a useful tool for improving the accuracy of these types of emotion recognition systems.
Technical Explanation
The key innovation in this paper is the use of attention pooling to aggregate the information from different parts of the speech signal for emotion recognition. Attention pooling is a technique that allows the model to dynamically focus on the most relevant parts of the input data when making a prediction.
The model architecture consists of a feature extraction backbone (e.g., a convolutional neural network) that processes the raw speech signal, followed by an attention pooling layer that computes attention weights for different time steps. These attention weights are then used to compute a weighted average of the features, which is passed to a final classification layer to predict the emotional state.
The model was evaluated on the EmoSPeech-IberLEF2024 dataset, which contains speech recordings in Spanish labeled with different emotional states. The results show that the attention pooling approach outperformed other baseline methods for emotion recognition on this dataset.
Critical Analysis
The paper provides a solid technical description of the proposed model and its performance on the EmoSPeech-IberLEF2024 dataset. However, the authors do not discuss any potential limitations or caveats of their approach.
For example, the paper does not mention how the model might perform on more diverse or noisy speech data, or how it compares to human-level emotion recognition abilities. Additionally, the attention pooling technique used in the model is not novel, and the authors do not explore any potential improvements or variations on this method.
Furthermore, the paper does not provide any analysis of the types of errors the model makes or the specific acoustic features it relies on for emotion recognition. This kind of analysis could provide valuable insights into the strengths and weaknesses of the approach and guide future research in this area.
Overall, while the results are promising, the paper would benefit from a more critical and comprehensive evaluation of the proposed method and its potential limitations.
Conclusion
This paper presents a new model developed by the BSC-UPC team for the EmoSPeech-IberLEF2024 challenge on emotional speech recognition. The key innovation is the use of attention pooling to selectively focus on the most relevant parts of the speech signal when making emotion predictions.
The results show that this attention-based approach outperforms other baseline methods on the EmoSPeech-IberLEF2024 dataset, demonstrating the potential of attention pooling for improving the accuracy of emotion recognition systems.
While the paper provides a solid technical description of the model, it would benefit from a more critical analysis of its limitations and potential areas for improvement. Nevertheless, this work represents an interesting contribution to the field of speech-based emotion recognition and could inspire further research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BSC-UPC at EmoSPeech-IberLEF2024: Attention Pooling for Emotion Recognition
Marc Casals-Salvador, Federico Costa, Miquel India, Javier Hernando
The domain of speech emotion recognition (SER) has persistently been a frontier within the landscape of machine learning. It is an active field that has been revolutionized in the last few decades and whose implementations are remarkable in multiple applications that could affect daily life. Consequently, the Iberian Languages Evaluation Forum (IberLEF) of 2024 held a competitive challenge to leverage the SER results with a Spanish corpus. This paper presents the approach followed with the goal of participating in this competition. The main architecture consists of different pre-trained speech and text models to extract features from both modalities, utilizing an attention pooling mechanism. The proposed system has achieved the first position in the challenge with an 86.69% in Macro F1-Score.
Read more7/18/2024
0
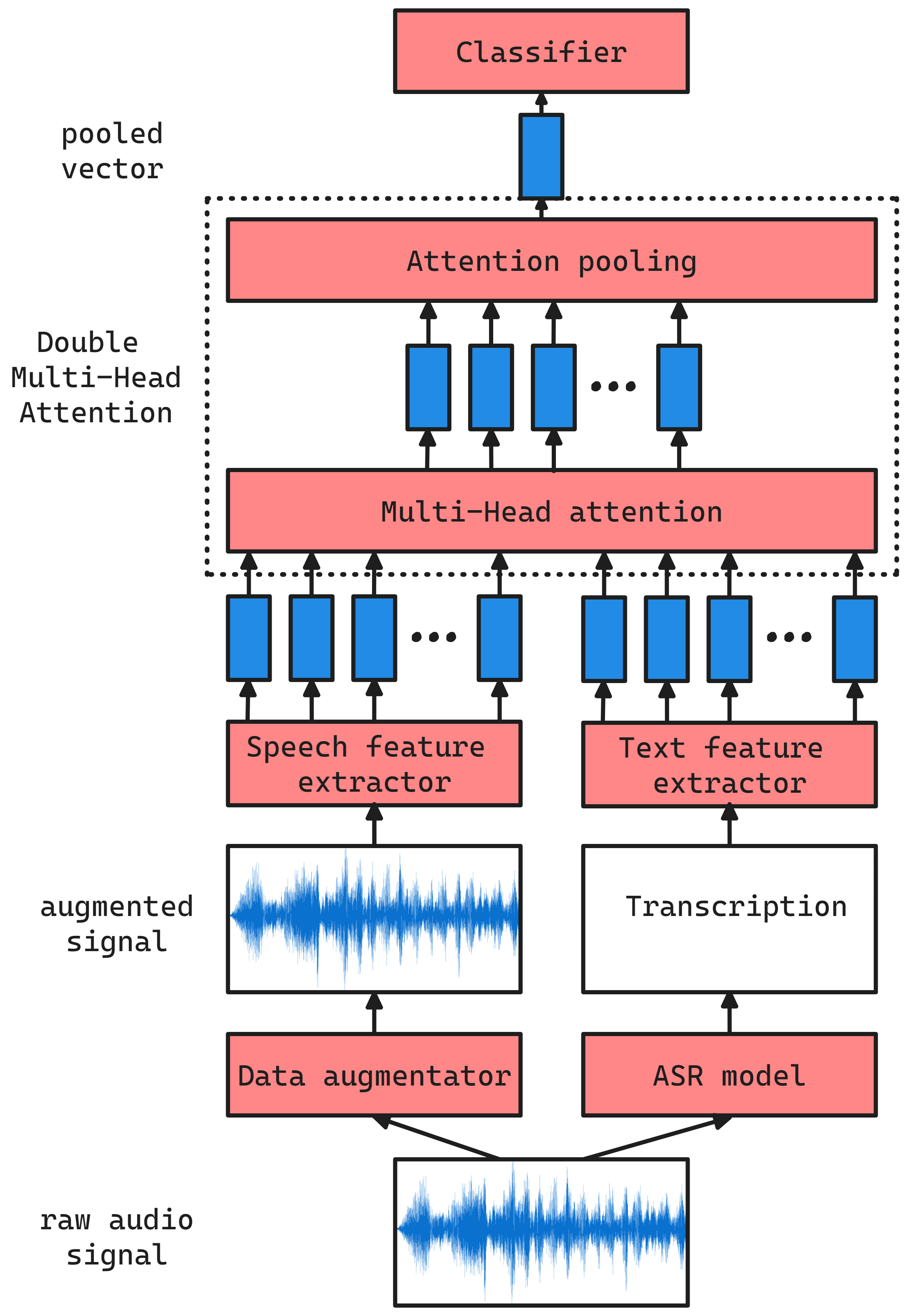
Double Multi-Head Attention Multimodal System for Odyssey 2024 Speech Emotion Recognition Challenge
Federico Costa, Miquel India, Javier Hernando
As computer-based applications are becoming more integrated into our daily lives, the importance of Speech Emotion Recognition (SER) has increased significantly. Promoting research with innovative approaches in SER, the Odyssey 2024 Speech Emotion Recognition Challenge was organized as part of the Odyssey 2024 Speaker and Language Recognition Workshop. In this paper we describe the Double Multi-Head Attention Multimodal System developed for this challenge. Pre-trained self-supervised models were used to extract informative acoustic and text features. An early fusion strategy was adopted, where a Multi-Head Attention layer transforms these mixed features into complementary contextualized representations. A second attention mechanism is then applied to pool these representations into an utterance-level vector. Our proposed system achieved the third position in the categorical task ranking with a 34.41% Macro-F1 score, where 31 teams participated in total.
Read more6/18/2024
0
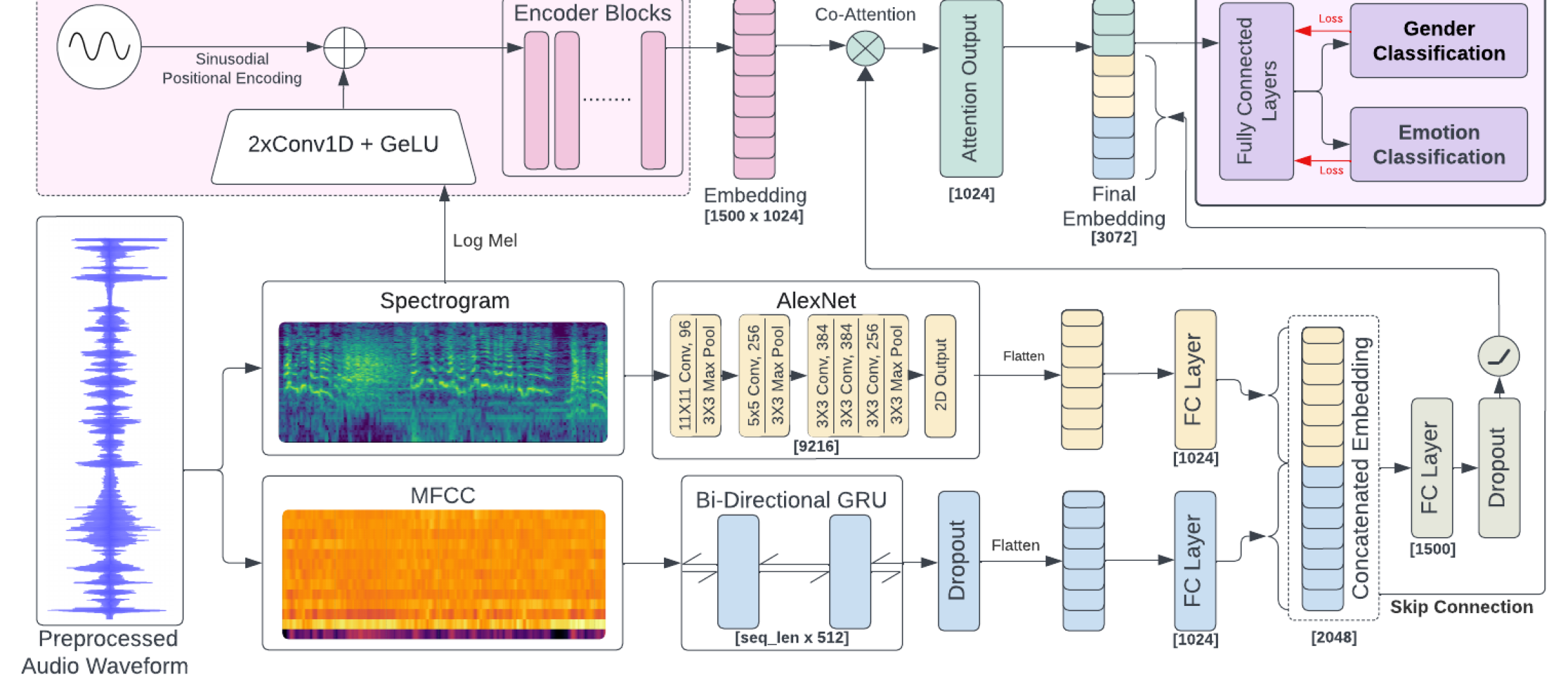
Exploring Multilingual Unseen Speaker Emotion Recognition: Leveraging Co-Attention Cues in Multitask Learning
Arnav Goel, Medha Hira, Anubha Gupta
Advent of modern deep learning techniques has given rise to advancements in the field of Speech Emotion Recognition (SER). However, most systems prevalent in the field fail to generalize to speakers not seen during training. This study focuses on handling challenges of multilingual SER, specifically on unseen speakers. We introduce CAMuLeNet, a novel architecture leveraging co-attention based fusion and multitask learning to address this problem. Additionally, we benchmark pretrained encoders of Whisper, HuBERT, Wav2Vec2.0, and WavLM using 10-fold leave-speaker-out cross-validation on five existing multilingual benchmark datasets: IEMOCAP, RAVDESS, CREMA-D, EmoDB and CaFE and, release a novel dataset for SER on the Hindi language (BhavVani). CAMuLeNet shows an average improvement of approximately 8% over all benchmarks on unseen speakers determined by our cross-validation strategy.
Read more6/21/2024
🗣️
0
MSP-Podcast SER Challenge 2024: L'antenne du Ventoux Multimodal Self-Supervised Learning for Speech Emotion Recognition
Jarod Duret (LIA), Mickael Rouvier (LIA), Yannick Est`eve (LIA)
In this work, we detail our submission to the 2024 edition of the MSP-Podcast Speech Emotion Recognition (SER) Challenge. This challenge is divided into two distinct tasks: Categorical Emotion Recognition and Emotional Attribute Prediction. We concentrated our efforts on Task 1, which involves the categorical classification of eight emotional states using data from the MSP-Podcast dataset. Our approach employs an ensemble of models, each trained independently and then fused at the score level using a Support Vector Machine (SVM) classifier. The models were trained using various strategies, including Self-Supervised Learning (SSL) fine-tuning across different modalities: speech alone, text alone, and a combined speech and text approach. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. Thus, the system obtained F1-macro of 0.35% on development set.
Read more7/9/2024