INTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition
2406.06401
0
0

Abstract
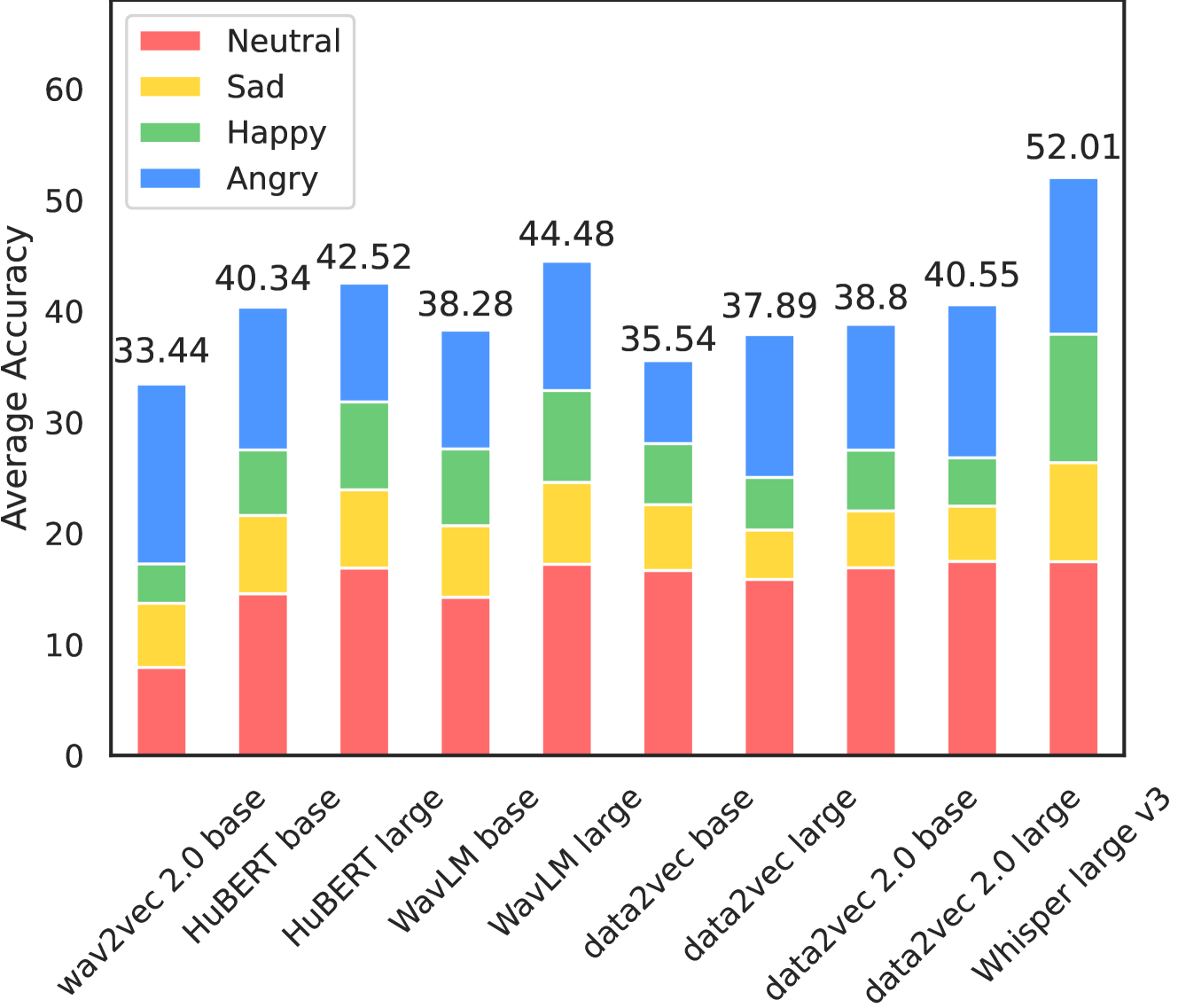
We revisit the INTERSPEECH 2009 Emotion Challenge -- the first ever speech emotion recognition (SER) challenge -- and evaluate a series of deep learning models that are representative of the major advances in SER research in the time since then. We start by training each model using a fixed set of hyperparameters, and further fine-tune the best-performing models of that initial setup with a grid search. Results are always reported on the official test set with a separate validation set only used for early stopping. Most models score below or close to the official baseline, while they marginally outperform the original challenge winners after hyperparameter tuning. Our work illustrates that, despite recent progress, FAU-AIBO remains a very challenging benchmark. An interesting corollary is that newer methods do not consistently outperform older ones, showing that progress towards `solving' SER is not necessarily monotonic.
Create account to get full access
Overview
- Revisits the INTERSPEECH 2009 Emotion Challenge, which focused on speech emotion recognition
- Benchmarks 15 years of progress in this field, analyzing how performance has improved over time
- Provides insights into the state of the art and future research directions in speech emotion recognition
Plain English Explanation
The paper revisits a previous competition, called the INTERSPEECH 2009 Emotion Challenge, which focused on developing systems that can recognize emotions expressed in speech. The authors examine how the performance of these emotion recognition systems has improved over the past 15 years.
By analyzing the results from this earlier challenge and comparing them to more recent research, the paper offers insights into the current capabilities of speech emotion recognition technology and where future work in this field might be headed. The [plain English explanation] helps make the technical details of the paper more accessible to a general audience.
Technical Explanation
The paper focuses on the FAU-AIBO emotion corpus, which was used in the original INTERSPEECH 2009 Emotion Challenge. This dataset contains spontaneous child-robot interactions, with the goal of recognizing the child's emotional state from their speech.
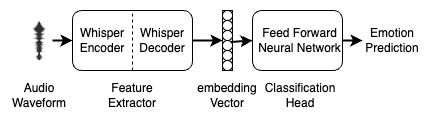
The authors re-evaluate the performance of various [speech emotion recognition] systems on this dataset, including both traditional machine learning approaches as well as more recent [deep learning] techniques. They analyze how accuracy, F1-score, and other metrics have improved over the years, providing a comprehensive [benchmark] of progress in this field.
The paper also discusses the challenges and limitations of speech emotion recognition, such as the difficulty of collecting natural, spontaneous emotional data, as well as biases in the datasets used to train these systems. The authors [encourage critical thinking] about the current state of the art and future research directions in this area.
Critical Analysis
The paper provides a valuable retrospective on the progress made in speech emotion recognition over the past 15 years. However, it also acknowledges several limitations and areas for further research:
- The FAU-AIBO dataset, while a common benchmark, may not be representative of real-world speech emotion scenarios. More diverse and naturalistic datasets are needed to fully evaluate these systems.
- The paper focuses on traditional performance metrics like accuracy and F1-score, but does not explore other important factors like algorithmic bias or [explainability](https://aimodels.fyi/papers/arxiv/unveiling-hidden-factors-explainable-ai-feature-boosting, https://aimodels.fyi/papers/arxiv/iterative-feature-boosting-explainable-speech-emotion-recognition).
- The analysis is limited to a single dataset and does not consider the performance of these systems on more diverse or challenging scenarios, such as adversarial attacks.
Overall, the paper provides a solid foundation for understanding the progress in speech emotion recognition, but more research is needed to fully assess the capabilities and limitations of these systems in real-world applications.
Conclusion
This paper offers a valuable retrospective on the field of speech emotion recognition, tracking the performance improvements over the past 15 years. By revisiting the INTERSPEECH 2009 Emotion Challenge dataset, the authors provide a comprehensive [benchmark] of how far the technology has come, while also highlighting the ongoing challenges and areas for future research.
The insights presented in this paper can help guide the development of more robust and reliable speech emotion recognition systems, with the potential to impact a wide range of applications, from human-robot interaction to mental health monitoring. As the field continues to evolve, it will be important to critically evaluate the performance, fairness, and explainability of these systems to ensure they serve the needs of all users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Ziyang Ma, Mingjie Chen, Hezhao Zhang, Zhisheng Zheng, Wenxi Chen, Xiquan Li, Jiaxin Ye, Xie Chen, Thomas Hain
0
0
Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
6/12/2024
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Adham Ibrahim, Shady Shehata, Ajinkya Kulkarni, Mukhtar Mohamed, Muhammad Abdul-Mageed
0
0
Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
6/17/2024
🗣️
Speech Emotion Recognition under Resource Constraints with Data Distillation
Yi Chang, Zhao Ren, Zhonghao Zhao, Thanh Tam Nguyen, Kun Qian, Tanja Schultz, Bjorn W. Schuller
0
0
Speech emotion recognition (SER) plays a crucial role in human-computer interaction. The emergence of edge devices in the Internet of Things (IoT) presents challenges in constructing intricate deep learning models due to constraints in memory and computational resources. Moreover, emotional speech data often contains private information, raising concerns about privacy leakage during the deployment of SER models. To address these challenges, we propose a data distillation framework to facilitate efficient development of SER models in IoT applications using a synthesised, smaller, and distilled dataset. Our experiments demonstrate that the distilled dataset can be effectively utilised to train SER models with fixed initialisation, achieving performances comparable to those developed using the original full emotional speech dataset.
6/24/2024

Unveiling Hidden Factors: Explainable AI for Feature Boosting in Speech Emotion Recognition
Alaa Nfissi, Wassim Bouachir, Nizar Bouguila, Brian Mishara
0
0
Speech emotion recognition (SER) has gained significant attention due to its several application fields, such as mental health, education, and human-computer interaction. However, the accuracy of SER systems is hindered by high-dimensional feature sets that may contain irrelevant and redundant information. To overcome this challenge, this study proposes an iterative feature boosting approach for SER that emphasizes feature relevance and explainability to enhance machine learning model performance. Our approach involves meticulous feature selection and analysis to build efficient SER systems. In addressing our main problem through model explainability, we employ a feature evaluation loop with Shapley values to iteratively refine feature sets. This process strikes a balance between model performance and transparency, which enables a comprehensive understanding of the model's predictions. The proposed approach offers several advantages, including the identification and removal of irrelevant and redundant features, leading to a more effective model. Additionally, it promotes explainability, facilitating comprehension of the model's predictions and the identification of crucial features for emotion determination. The effectiveness of the proposed method is validated on the SER benchmarks of the Toronto emotional speech set (TESS), Berlin Database of Emotional Speech (EMO-DB), Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS), and Surrey Audio-Visual Expressed Emotion (SAVEE) datasets, outperforming state-of-the-art methods. To the best of our knowledge, this is the first work to incorporate model explainability into an SER framework. The source code of this paper is publicly available via this https://github.com/alaaNfissi/Unveiling-Hidden-Factors-Explainable-AI-for-Feature-Boosting-in-Speech-Emotion-Recognition.
6/7/2024