Budgeted Recommendation with Delayed Feedback

0
Sign in to get full access
Overview
- This paper presents a new algorithm for budgeted recommendation systems with delayed feedback.
- The algorithm aims to maximize the cumulative reward under a budget constraint, while accounting for delays in the feedback received.
- The authors provide theoretical guarantees on the performance of their algorithm and validate its effectiveness through experiments.
Plain English Explanation
In many real-world recommendation systems, such as suggesting products to customers or content to users, there are often constraints on the resources (e.g., time, money) that can be spent on each recommendation. Additionally, the feedback on whether a recommendation was successful may not be immediately available, but rather delayed.
The authors of this paper have developed a new algorithm to address these challenges. Their algorithm tries to maximize the overall value or reward of the recommendations made, while staying within a given budget. Importantly, it also takes into account the delay in receiving feedback on how well each recommendation performed.
The key idea behind the algorithm is to carefully balance exploration (trying out new recommendations to learn about their potential) and exploitation (focusing on recommendations that have proven successful in the past). This tradeoff is crucial, as too much exploration can waste the limited budget, while too much exploitation may miss out on potentially better recommendations.
The authors provide mathematical guarantees on how well their algorithm performs compared to an ideal, omniscient system that has perfect knowledge of all recommendations. They also demonstrate the practical effectiveness of their approach through experiments on realistic datasets.
Technical Explanation
The paper introduces the Budgeted Recommendation with Delayed Feedback problem, where the goal is to maximize the cumulative reward of recommendations subject to a budget constraint, while accounting for delays in the feedback received.
The authors propose a new algorithm, called Delayed Feedback Budgeted Recommendation (DFBR), that dynamically allocates the budget to different recommendations based on their estimated rewards and the delay in feedback. DFBR uses an explore-then-commit strategy, where it first explores a set of candidate recommendations, and then commits to the most promising ones.
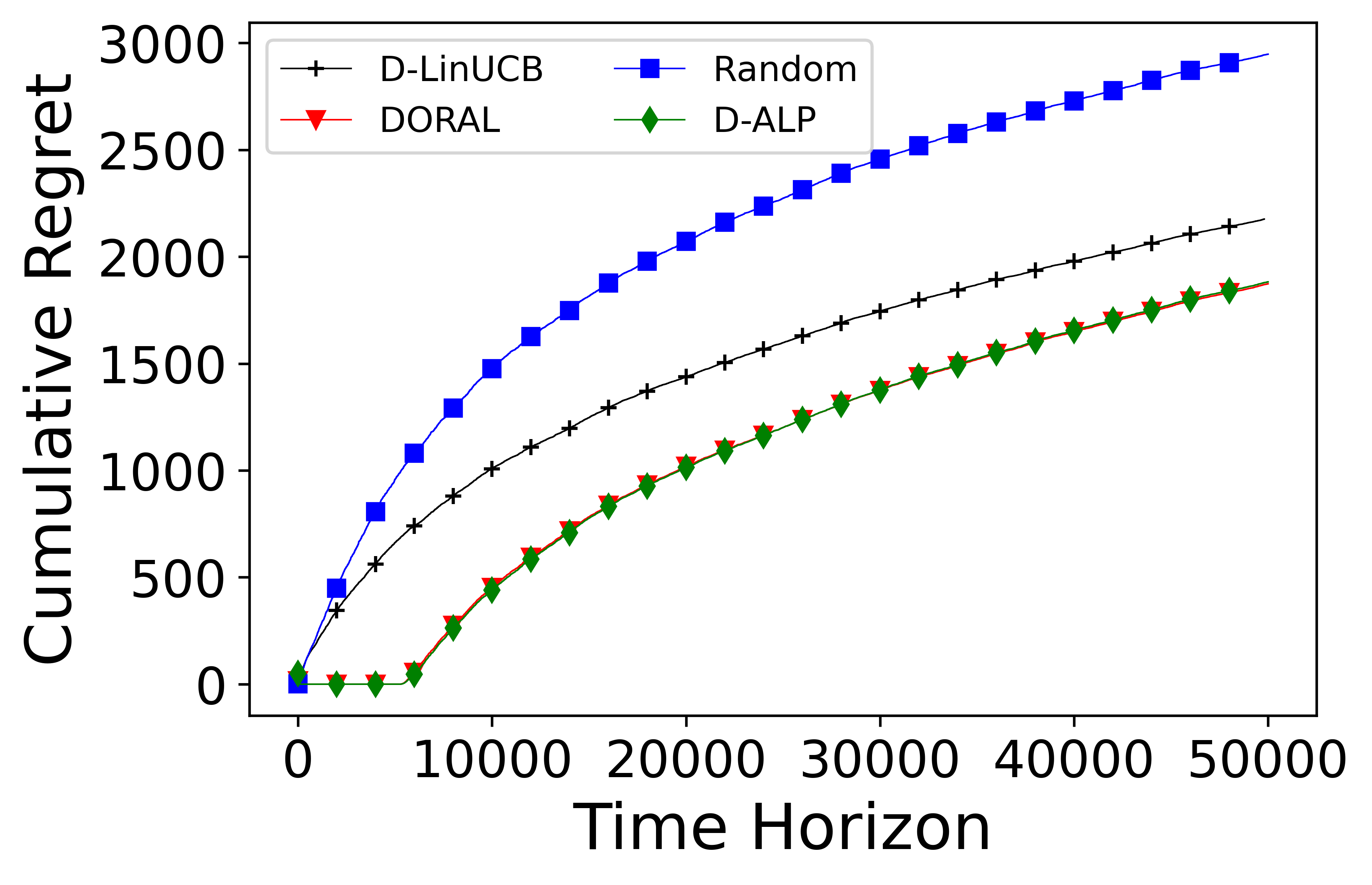
The paper provides a regret analysis of DFBR, showing that its regret scales logarithmically with the number of rounds, and is near-optimal compared to an omniscient algorithm with full information about the rewards. The authors also present experiments on synthetic and real-world datasets, demonstrating the superior performance of DFBR over baseline approaches.
Critical Analysis
The paper makes several important contributions to the field of budgeted recommendation systems with delayed feedback. The proposed DFBR algorithm is a well-designed and theoretically-grounded approach that addresses the key challenges in this problem setting.
One potential limitation of the work is that it assumes the delays in feedback are deterministic and known in advance. In many real-world scenarios, the delay may be stochastic and difficult to predict. An extension of the algorithm to handle uncertain delays could further improve its applicability.
Additionally, the paper focuses on a single-agent setting, where the recommendation system operates in isolation. Exploring multi-agent or competitive scenarios, where multiple recommendation systems interact, could lead to interesting extensions and insights.
Finally, while the experiments demonstrate the algorithm's effectiveness, it would be valuable to see more diverse real-world applications and case studies to understand the practical challenges and tradeoffs involved in deploying such a system in complex, large-scale environments.
Conclusion
This paper presents a novel algorithm, DFBR, for budgeted recommendation systems with delayed feedback. By carefully balancing exploration and exploitation, and accounting for the delay in feedback, the algorithm is able to maximize the cumulative reward while staying within a given budget constraint.
The theoretical guarantees and experimental results suggest that DFBR is a promising approach for practical recommendation systems facing resource limitations and delayed information. The insights and techniques developed in this work could inspire further research in this important and growing area of machine learning and decision-making under uncertainty.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Budgeted Recommendation with Delayed Feedback
Kweiguu Liu, Setareh Maghsudi
In a conventional contextual multi-armed bandit problem, the feedback (or reward) is immediately observable after an action. Nevertheless, delayed feedback arises in numerous real-life situations and is particularly crucial in time-sensitive applications. The exploration-exploitation dilemma becomes particularly challenging under such conditions, as it couples with the interplay between delays and limited resources. Besides, a limited budget often aggravates the problem by restricting the exploration potential. A motivating example is the distribution of medical supplies at the early stage of COVID-19. The delayed feedback of testing results, thus insufficient information for learning, degraded the efficiency of resource allocation. Motivated by such applications, we study the effect of delayed feedback on constrained contextual bandits. We develop a decision-making policy, delay-oriented resource allocation with learning (DORAL), to optimize the resource expenditure in a contextual multi-armed bandit problem with arm-dependent delayed feedback.
Read more5/21/2024

0
Biased Dueling Bandits with Stochastic Delayed Feedback
Bongsoo Yi, Yue Kang, Yao Li
The dueling bandit problem, an essential variation of the traditional multi-armed bandit problem, has become significantly prominent recently due to its broad applications in online advertising, recommendation systems, information retrieval, and more. However, in many real-world applications, the feedback for actions is often subject to unavoidable delays and is not immediately available to the agent. This partially observable issue poses a significant challenge to existing dueling bandit literature, as it significantly affects how quickly and accurately the agent can update their policy on the fly. In this paper, we introduce and examine the biased dueling bandit problem with stochastic delayed feedback, revealing that this new practical problem will delve into a more realistic and intriguing scenario involving a preference bias between the selections. We present two algorithms designed to handle situations involving delay. Our first algorithm, requiring complete delay distribution information, achieves the optimal regret bound for the dueling bandit problem when there is no delay. The second algorithm is tailored for situations where the distribution is unknown, but only the expected value of delay is available. We provide a comprehensive regret analysis for the two proposed algorithms and then evaluate their empirical performance on both synthetic and real datasets.
Read more8/28/2024

0
Merit-based Fair Combinatorial Semi-Bandit with Unrestricted Feedback Delays
Ziqun Chen, Kechao Cai, Zhuoyue Chen, Jinbei Zhang, John C. S. Lui
We study the stochastic combinatorial semi-bandit problem with unrestricted feedback delays under merit-based fairness constraints. This is motivated by applications such as crowdsourcing, and online advertising, where immediate feedback is not immediately available and fairness among different choices (or arms) is crucial. We consider two types of unrestricted feedback delays: reward-independent delays where the feedback delays are independent of the rewards, and reward-dependent delays where the feedback delays are correlated with the rewards. Furthermore, we introduce merit-based fairness constraints to ensure a fair selection of the arms. We define the reward regret and the fairness regret and present new bandit algorithms to select arms under unrestricted feedback delays based on their merits. We prove that our algorithms all achieve sublinear expected reward regret and expected fairness regret, with a dependence on the quantiles of the delay distribution. We also conduct extensive experiments using synthetic and real-world data and show that our algorithms can fairly select arms with different feedback delays.
Read more7/30/2024
🔍
0
A Best-of-both-worlds Algorithm for Bandits with Delayed Feedback with Robustness to Excessive Delays
Saeed Masoudian, Julian Zimmert, Yevgeny Seldin
We propose a new best-of-both-worlds algorithm for bandits with variably delayed feedback. In contrast to prior work, which required prior knowledge of the maximal delay $d_{mathrm{max}}$ and had a linear dependence of the regret on it, our algorithm can tolerate arbitrary excessive delays up to order $T$ (where $T$ is the time horizon). The algorithm is based on three technical innovations, which may all be of independent interest: (1) We introduce the first implicit exploration scheme that works in best-of-both-worlds setting. (2) We introduce the first control of distribution drift that does not rely on boundedness of delays. The control is based on the implicit exploration scheme and adaptive skipping of observations with excessive delays. (3) We introduce a procedure relating standard regret with drifted regret that does not rely on boundedness of delays. At the conceptual level, we demonstrate that complexity of best-of-both-worlds bandits with delayed feedback is characterized by the amount of information missing at the time of decision making (measured by the number of outstanding observations) rather than the time that the information is missing (measured by the delays).
Read more5/29/2024