Building Guardrails for Large Language Models
2402.01822
0
0

Abstract
As Large Language Models (LLMs) become more integrated into our daily lives, it is crucial to identify and mitigate their risks, especially when the risks can have profound impacts on human users and societies. Guardrails, which filter the inputs or outputs of LLMs, have emerged as a core safeguarding technology. This position paper takes a deep look at current open-source solutions (Llama Guard, Nvidia NeMo, Guardrails AI), and discusses the challenges and the road towards building more complete solutions. Drawing on robust evidence from previous research, we advocate for a systematic approach to construct guardrails for LLMs, based on comprehensive consideration of diverse contexts across various LLMs applications. We propose employing socio-technical methods through collaboration with a multi-disciplinary team to pinpoint precise technical requirements, exploring advanced neural-symbolic implementations to embrace the complexity of the requirements, and developing verification and testing to ensure the utmost quality of the final product.
Create account to get full access
Overview
- Explores the technical challenges of implementing safeguards and requirements for large language models (LLMs)
- Discusses existing solutions and their limitations
- Analyzes the difficulties in implementing individual requirements, such as safety, security, and transparency
- Highlights the need for a comprehensive framework to address the complexities of deploying LLMs in the real world
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence systems that can generate human-like text on a wide range of topics. However, as these models become more advanced, there are growing concerns about their potential misuse and the need for robust safeguards to ensure their responsible deployment.
This paper examines the technical challenges involved in implementing various requirements and guardrails for LLMs, such as ensuring safety, security, transparency, and alignment with human values. The authors explore existing solutions and their limitations, acknowledging the inherent complexities in addressing these issues.
For example, one requirement might be to prevent LLMs from generating harmful or biased content. However, the paper explains that implementing such a safeguard is not straightforward, as it requires a deep understanding of the model's inner workings, the ability to anticipate potential misuse, and the development of advanced mitigation techniques.
Similarly, the paper discusses the challenges of ensuring the security of LLMs, such as protecting them from adversarial attacks that could compromise their integrity or privacy. Achieving transparency, so that users can understand how the models arrive at their outputs, is another hurdle that the authors explore in depth.
Overall, the paper highlights the need for a comprehensive framework to address the multifaceted challenges of deploying LLMs in the real world. By understanding these technical complexities, researchers and developers can work towards building more reliable and trustworthy large language models that can be safely and responsibly used to benefit society.
Technical Explanation
The paper delves into the technical challenges of implementing various safeguards and requirements for large language models (LLMs). It begins by discussing existing solutions, such as causal-explainable-guardrails-large-language-models, framework-real-time-safeguarding-text-generation-large, and apprentices-to-research-assistants-advancing-research-large, and their limitations in addressing the complexities of LLM deployment.
The paper then examines the technical difficulties in implementing individual requirements, such as safety, security, and transparency. For example, the authors discuss the challenge of preventing LLMs from generating harmful or biased content, which requires a deep understanding of the model's inner workings, the ability to anticipate potential misuse, and the development of advanced mitigation techniques.
The paper also explores the challenges of ensuring the security of LLMs, such as protecting them from adversarial attacks that could compromise their integrity or privacy. Achieving transparency, so that users can understand how the models arrive at their outputs, is another hurdle that the authors analyze in depth.
The authors highlight the need for a comprehensive framework, such as genshin-general-shield-natural-language-processing-large and generative-ai-large-language-models-cyber-security, to address the multifaceted challenges of deploying LLMs in the real world. By understanding these technical complexities, researchers and developers can work towards building more reliable and trustworthy large language models that can be safely and responsibly used to benefit society.
Critical Analysis
The paper provides a comprehensive analysis of the technical challenges involved in implementing safeguards and requirements for large language models (LLMs). It acknowledges the inherent complexities in addressing issues such as safety, security, and transparency, and highlights the limitations of existing solutions.
One potential area for further research mentioned in the paper is the development of advanced mitigation techniques to prevent LLMs from generating harmful or biased content. While the authors discuss the challenges in this area, they do not provide specific solutions or recommendations for how to overcome these hurdles.
Additionally, the paper could have delved deeper into the security challenges posed by LLMs, such as the potential for adversarial attacks to compromise the models' integrity or privacy. While the authors touch on these issues, a more detailed discussion of the specific vulnerabilities and potential countermeasures could have strengthened the analysis.
Furthermore, the paper could have explored the ethical implications of deploying LLMs and the potential societal impact of these systems. As these models become more advanced and widespread, it is crucial to consider the broader implications beyond the technical challenges addressed in the paper.
Overall, the paper provides a valuable contribution to the ongoing discussions around the responsible development and deployment of large language models. By highlighting the technical complexities involved, the authors underscore the need for a comprehensive and multifaceted approach to building trustworthy and reliable LLMs.
Conclusion
This paper delves into the technical challenges of implementing safeguards and requirements for large language models (LLMs), a critical issue as these powerful AI systems become more advanced and prevalent. The authors explore existing solutions and their limitations, and analyze the difficulties in implementing individual requirements such as safety, security, and transparency.
The paper emphasizes the need for a comprehensive framework to address the multifaceted challenges of deploying LLMs in the real world. By understanding these technical complexities, researchers and developers can work towards building more reliable and trustworthy large language models that can be safely and responsibly used to benefit society.
The insights and analysis provided in this paper contribute to the ongoing efforts to ensure the responsible development and deployment of large language models, which have the potential to revolutionize various industries and applications, but also come with significant risks and challenges that must be addressed.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Safeguarding Large Language Models: A Survey
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, Saddek Bensalem, Xiaowei Huang
0
0
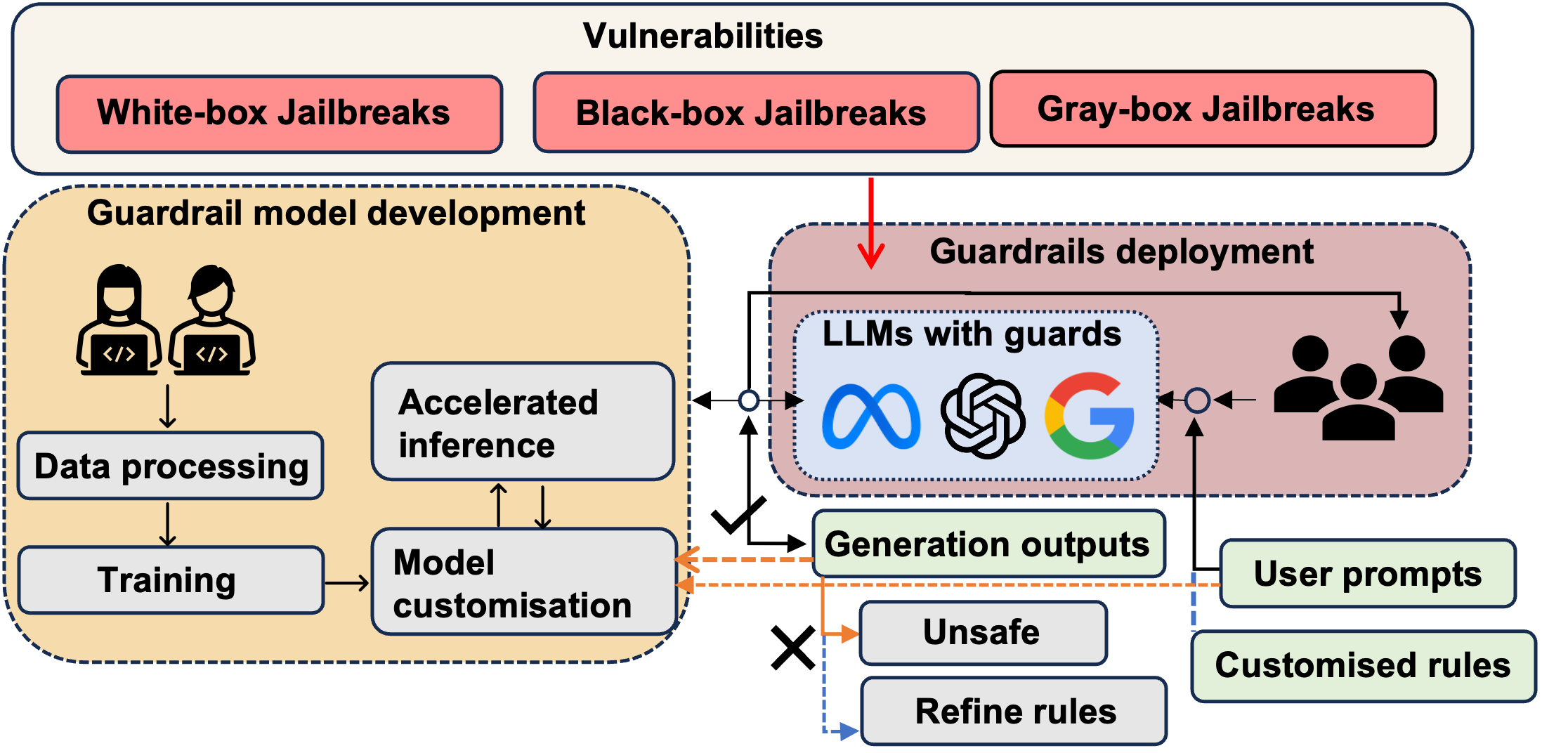
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as safeguards or guardrails, has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
6/6/2024
🤖
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
0
0
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
6/21/2024
💬
A Causal Explainable Guardrails for Large Language Models
Zhixuan Chu, Yan Wang, Longfei Li, Zhibo Wang, Zhan Qin, Kui Ren
0
0
Large Language Models (LLMs) have shown impressive performance in natural language tasks, but their outputs can exhibit undesirable attributes or biases. Existing methods for steering LLMs towards desired attributes often assume unbiased representations and rely solely on steering prompts. However, the representations learned from pre-training can introduce semantic biases that influence the steering process, leading to suboptimal results. We propose LLMGuardaril, a novel framework that incorporates causal analysis and adversarial learning to obtain unbiased steering representations in LLMs. LLMGuardaril systematically identifies and blocks the confounding effects of biases, enabling the extraction of unbiased steering representations. Additionally, it includes an explainable component that provides insights into the alignment between the generated output and the desired direction. Experiments demonstrate LLMGuardaril's effectiveness in steering LLMs towards desired attributes while mitigating biases. Our work contributes to the development of safe and reliable LLMs that align with desired attributes. We discuss the limitations and future research directions, highlighting the need for ongoing research to address the ethical implications of large language models.
5/8/2024
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
0
0
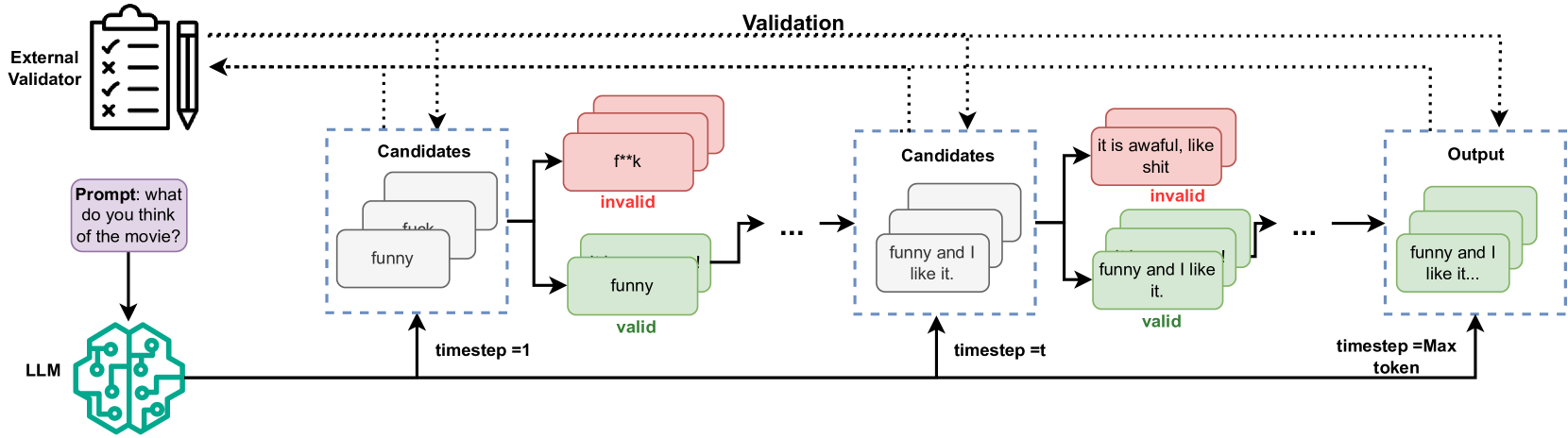
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
5/3/2024