Safeguarding Large Language Models: A Survey
2406.02622
0
0
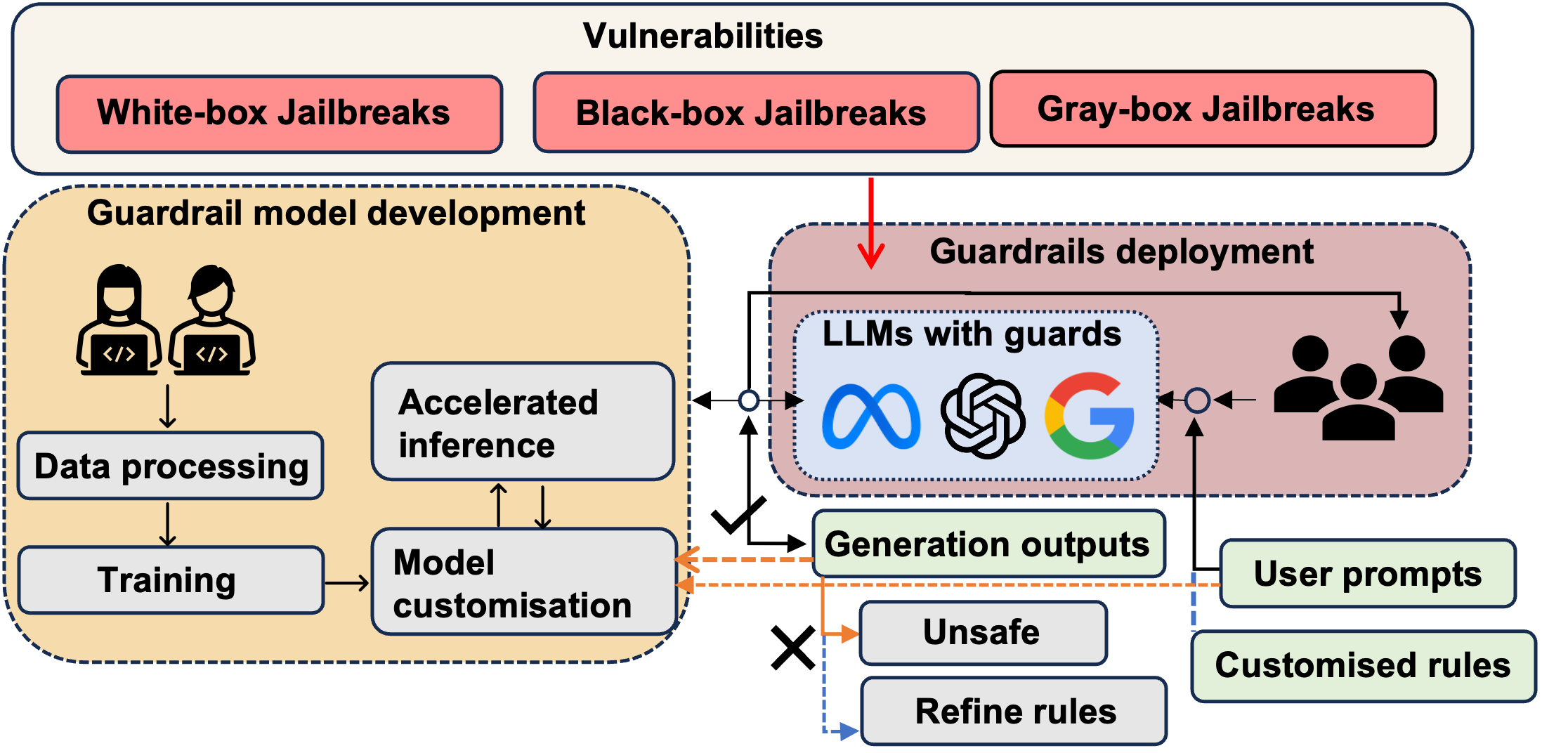
Abstract
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as safeguards or guardrails, has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
Create account to get full access
Overview
- Examines the challenges and current approaches to safeguarding large language models (LLMs), which are powerful AI systems that can generate human-like text.
- Covers a range of safeguarding strategies, from technical solutions to governance frameworks.
- Highlights the need for a comprehensive, multifaceted approach to ensure the safe and responsible development and deployment of LLMs.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can generate human-like text. They have become extremely powerful, with the ability to write articles, answer questions, and even engage in conversations. However, these models also come with significant risks, such as the potential to spread misinformation, be used for malicious purposes, or exhibit biases and other undesirable behaviors.
This paper provides an overview of the current efforts to address these challenges and safeguard LLMs. It explores a range of approaches, from technical solutions like Building Guardrails for Large Language Models and A Framework for Real-Time Safeguarding of Text Generation in Large Language Models, to governance frameworks like SLM as Guardian: A Pioneering Approach to AI Safety at Scale and Large Language Models in Cyber Security: A Systematic Literature Review.
The paper emphasizes the need for a comprehensive, multifaceted approach to ensure the safe and responsible development and deployment of LLMs. This includes addressing technical challenges, implementing effective governance and oversight, and fostering a culture of responsible AI development.
Technical Explanation
The paper provides a comprehensive overview of the current state of research and practice in safeguarding large language models (LLMs). It explores a range of technical approaches, such as Building Guardrails for Large Language Models, which focuses on developing safeguards to prevent LLMs from generating harmful or biased content.
The paper also examines governance frameworks, such as SLM as Guardian: A Pioneering Approach to AI Safety at Scale, which proposes the use of "Supervising Language Models" to monitor and control the behavior of LLMs. Additionally, it reviews A Framework for Real-Time Safeguarding of Text Generation in Large Language Models, which outlines a system for real-time detection and mitigation of potential harms from LLM-generated text.
The paper also explores the use of LLMs in cybersecurity, as detailed in Large Language Models in Cyber Security: A Systematic Literature Review, and discusses the need for Safe and Responsible Large Language Model Development.
Overall, the paper highlights the importance of a comprehensive, multifaceted approach to safeguarding LLMs, involving both technical and governance-related solutions.
Critical Analysis
The paper provides a thorough overview of the current state of research and practice in safeguarding large language models (LLMs), but it also acknowledges the significant challenges and limitations involved.
One key limitation is the inherent complexity of LLMs, which can make it difficult to fully understand and predict their behavior. The paper notes that much of the current research focuses on specific, narrow use cases, and there is a need for more comprehensive and generalizable safeguarding approaches.
Additionally, the paper highlights the potential for unintended consequences and the need for ongoing monitoring and adaptation as LLMs continue to evolve. It emphasizes the importance of governance frameworks and the involvement of diverse stakeholders, including policymakers, ethicists, and the general public, to ensure the safe and responsible development of these powerful technologies.
While the paper presents a range of promising technical and governance-related solutions, it also acknowledges the need for further research and experimentation to fully address the challenges posed by LLMs. Readers are encouraged to critically evaluate the proposed approaches and consider the potential trade-offs and long-term implications of safeguarding strategies.
Conclusion
This paper provides a comprehensive survey of the current efforts to safeguard large language models (LLMs), highlighting the multifaceted nature of the challenge. It explores a range of technical solutions, such as Building Guardrails for Large Language Models and A Framework for Real-Time Safeguarding of Text Generation in Large Language Models, as well as governance frameworks like SLM as Guardian: A Pioneering Approach to AI Safety at Scale and Large Language Models in Cyber Security: A Systematic Literature Review.
The paper emphasizes the need for a comprehensive, multifaceted approach to safeguarding LLMs, involving both technical and governance-related solutions. It highlights the inherent complexity of these models and the potential for unintended consequences, underscoring the importance of ongoing monitoring, adaptation, and the involvement of diverse stakeholders to ensure the safe and responsible development of these powerful technologies.
As LLMs continue to evolve and become more ubiquitous, the insights and recommendations provided in this paper will be crucial in guiding the research and development of effective safeguarding strategies, ultimately contributing to the safe and beneficial deployment of these transformative AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
0
0
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
6/21/2024

Building Guardrails for Large Language Models
Yi Dong, Ronghui Mu, Gaojie Jin, Yi Qi, Jinwei Hu, Xingyu Zhao, Jie Meng, Wenjie Ruan, Xiaowei Huang
0
0
As Large Language Models (LLMs) become more integrated into our daily lives, it is crucial to identify and mitigate their risks, especially when the risks can have profound impacts on human users and societies. Guardrails, which filter the inputs or outputs of LLMs, have emerged as a core safeguarding technology. This position paper takes a deep look at current open-source solutions (Llama Guard, Nvidia NeMo, Guardrails AI), and discusses the challenges and the road towards building more complete solutions. Drawing on robust evidence from previous research, we advocate for a systematic approach to construct guardrails for LLMs, based on comprehensive consideration of diverse contexts across various LLMs applications. We propose employing socio-technical methods through collaboration with a multi-disciplinary team to pinpoint precise technical requirements, exploring advanced neural-symbolic implementations to embrace the complexity of the requirements, and developing verification and testing to ensure the utmost quality of the final product.
5/30/2024
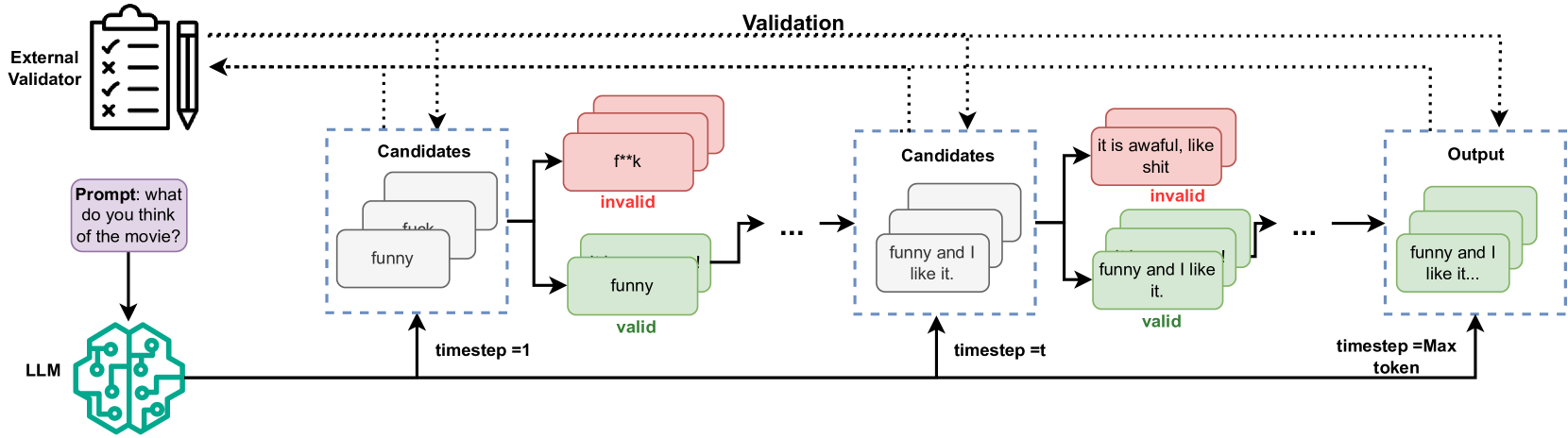
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
0
0
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
5/3/2024

SLM as Guardian: Pioneering AI Safety with Small Language Models
Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park
0
0
Most prior safety research of large language models (LLMs) has focused on enhancing the alignment of LLMs to better suit the safety requirements of humans. However, internalizing such safeguard features into larger models brought challenges of higher training cost and unintended degradation of helpfulness. To overcome such challenges, a modular approach employing a smaller LLM to detect harmful user queries is regarded as a convenient solution in designing LLM-based system with safety requirements. In this paper, we leverage a smaller LLM for both harmful query detection and safeguard response generation. We introduce our safety requirements and the taxonomy of harmfulness categories, and then propose a multi-task learning mechanism fusing the two tasks into a single model. We demonstrate the effectiveness of our approach, providing on par or surpassing harmful query detection and safeguard response performance compared to the publicly available LLMs.
5/31/2024