BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
2403.09347
0
0
Abstract
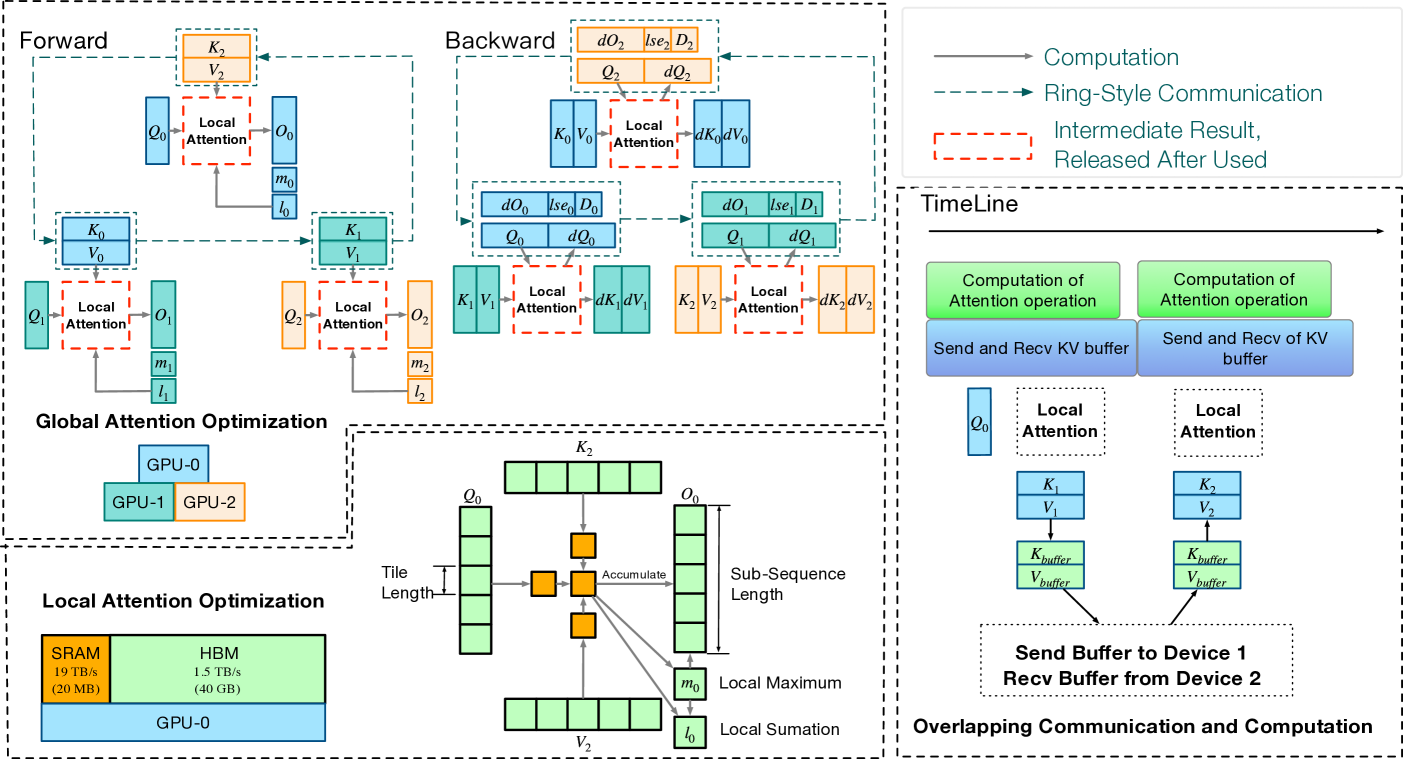
Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences. One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones. In this paper, we propose a distributed attention framework named ``BurstAttention'' to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing. The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 1.37 X speedup during training 128K sequence length on 32 X A100.
Create account to get full access
Overview
- The provided paper introduces "BurstAttention", an efficient distributed attention framework for processing extremely long sequences.
- The key innovations include a burst-based attention mechanism and a distributed attention architecture that enables parallel processing of long sequences.
- The framework aims to improve the computational efficiency and scalability of attention-based models for tasks involving very long inputs, such as long-form text, videos, or scientific documents.
Plain English Explanation
The paper proposes a new way of handling very long sequences of data, such as lengthy text documents or video recordings. Traditional attention-based models, which are commonly used in tasks like machine translation or text summarization, can struggle when dealing with extremely long inputs because the computational cost of the attention mechanism grows rapidly as the sequence length increases.
To address this, the researchers developed a technique called "BurstAttention". The core idea is to break up the long sequence into smaller "bursts" that can be processed in parallel, rather than processing the entire sequence as a single unit. This burst-based approach allows the attention mechanism to focus on the most relevant parts of the input, rather than wasting resources on less important information.
The researchers also designed a distributed attention architecture that further improves the efficiency of the system. By distributing the attention computations across multiple processing units, the model can scale to handle even longer sequences without running into memory or computational constraints.
The key benefits of this approach are improved efficiency, scalability, and the ability to process extremely long inputs that would be intractable for traditional attention-based models. This could enable new applications and further advances in areas like long-form text generation, video understanding, and large language model inference.
Technical Explanation
The paper introduces the BurstAttention framework, which consists of two key components:
-
Burst-based Attention Mechanism: The input sequence is divided into smaller "bursts", and the attention mechanism is applied within each burst independently. This allows the model to focus on the most relevant parts of the input while avoiding the computational overhead of applying attention across the entire sequence.
-
Distributed Attention Architecture: The attention computations are distributed across multiple processing units, enabling the model to scale to handle extremely long sequences. This distributed approach leverages sequence parallelism techniques to achieve efficient processing of long inputs.
The researchers conduct experiments on various tasks, including long-form text summarization and long document classification, to demonstrate the effectiveness of the BurstAttention framework. They show that their approach outperforms traditional attention-based models in terms of computational efficiency and scalability, without sacrificing task performance.
Critical Analysis
The paper presents a well-designed and experimentally validated approach to addressing the challenges of handling extremely long sequences in attention-based models. The burst-based attention mechanism and distributed attention architecture are innovative solutions that enable efficient processing of long inputs.
However, the paper does not discuss several potential limitations or areas for further research:
-
Burst Segmentation: The paper does not provide detailed information on how the input sequence is divided into bursts. The performance of the BurstAttention framework may be sensitive to the burst segmentation strategy, and further investigation into optimal segmentation methods could be beneficial.
-
Generalization to Other Tasks: The experiments in the paper focus on text-based tasks, such as summarization and classification. It would be interesting to explore the applicability of the BurstAttention framework to other domains, such as video understanding or large language model inference, to assess its broader utility.
-
Attention Reuse: The paper does not discuss the potential for attention reuse across multiple bursts or processing units, which could further improve the efficiency of the framework.
Despite these limitations, the BurstAttention framework represents a significant contribution to the field of attention-based models, particularly for tasks involving extremely long sequences. The paper's insights and techniques could inspire further research and development in this important area.
Conclusion
The BurstAttention paper introduces an efficient distributed attention framework that addresses the challenges of processing extremely long sequences in attention-based models. By employing a burst-based attention mechanism and a distributed attention architecture, the framework enables improved computational efficiency and scalability without sacrificing task performance.
The key innovations and potential implications of this work include:
- Enhanced ability to handle long-form text, videos, and other data with extremely long sequences
- Opportunities for new applications and advances in areas like long-form text generation, video understanding, and large language model inference
- Inspiring further research into attention-based models, sequence parallelism, and efficient processing of long inputs
Overall, the BurstAttention framework represents an important step forward in addressing the limitations of traditional attention-based models and expanding the capabilities of AI systems to handle increasingly complex and long-form data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024
RelayAttention for Efficient Large Language Model Serving with Long System Prompts
Lei Zhu, Xinjiang Wang, Wayne Zhang, Rynson W. H. Lau
0
0
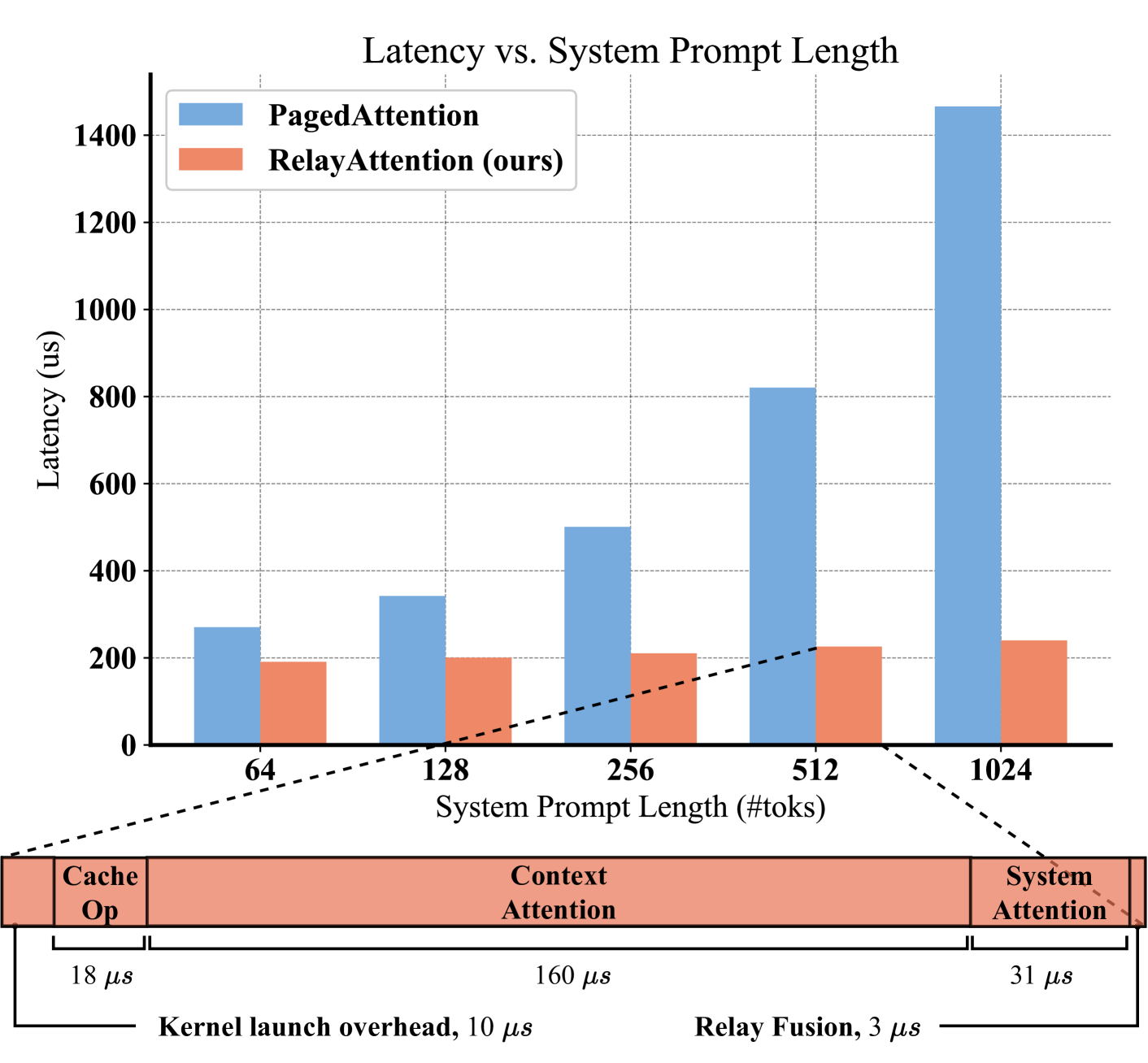
A practical large language model (LLM) service may involve a long system prompt, which specifies the instructions, examples, and knowledge documents of the task and is reused across requests. However, the long system prompt causes throughput/latency bottlenecks as the cost of generating the next token grows w.r.t. the sequence length. This paper aims to improve the efficiency of LLM services that involve long system prompts. Our key observation is that handling these system prompts requires heavily redundant memory accesses in existing causal attention computation algorithms. Specifically, for batched requests, the cached hidden states (ie, key-value pairs) of system prompts are transferred from off-chip DRAM to on-chip SRAM multiple times, each corresponding to an individual request. To eliminate such a redundancy, we propose RelayAttention, an attention algorithm that allows reading these hidden states from DRAM exactly once for a batch of input tokens. RelayAttention is a free lunch: it maintains the generation quality while requiring no model retraining, as it is based on a mathematical reformulation of causal attention. We have observed significant performance improvements to a production-level system, vLLM, through integration with RelayAttention. The improvements are even more profound with longer system prompts.
5/31/2024
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
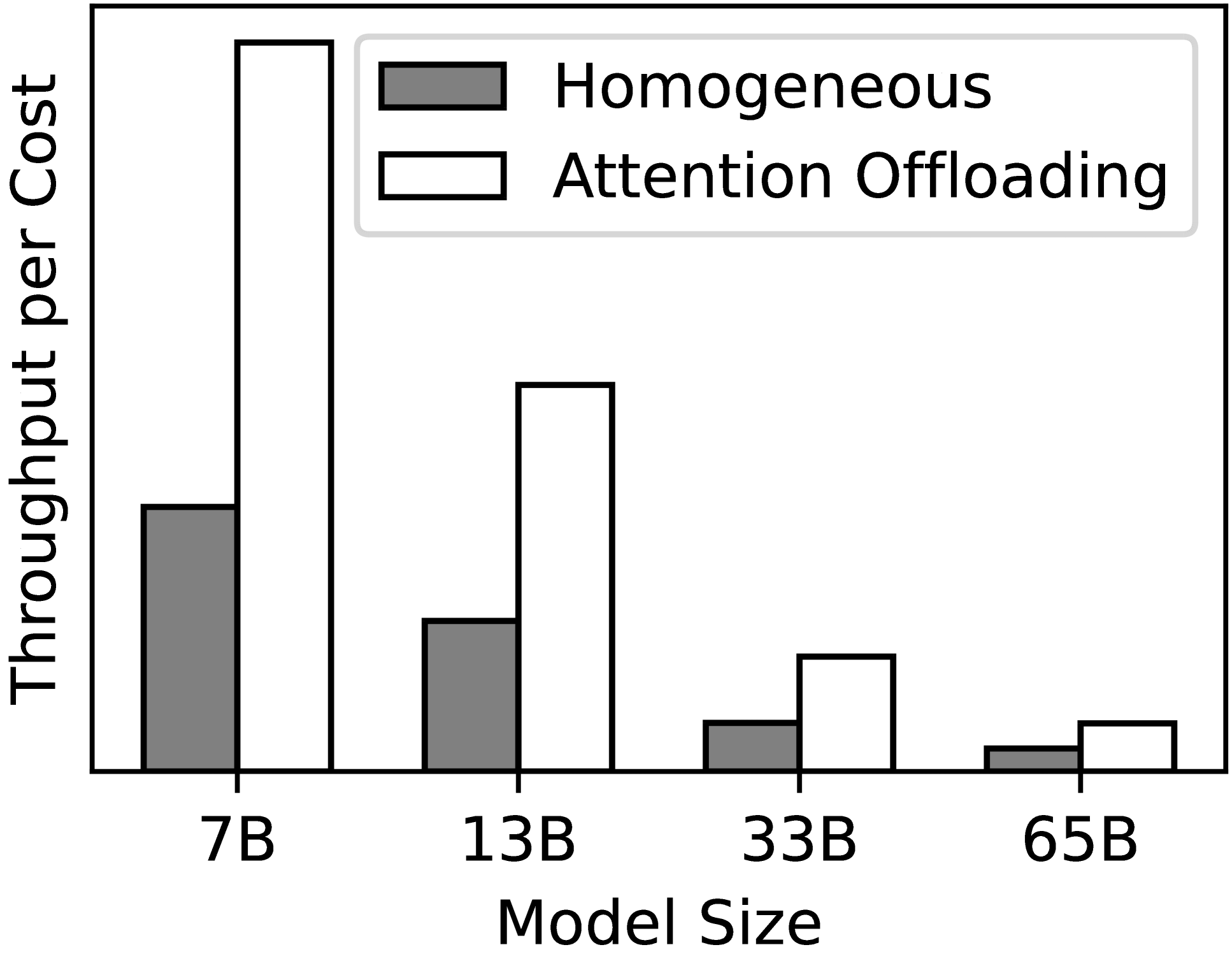
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
0
0
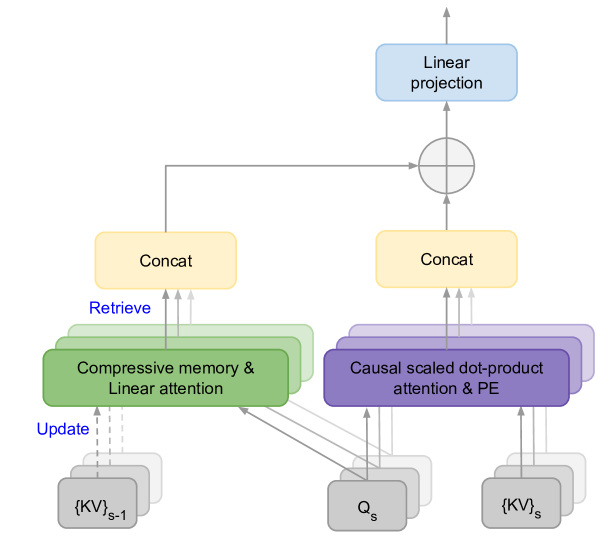
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
4/11/2024