Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
2404.07143
38
0
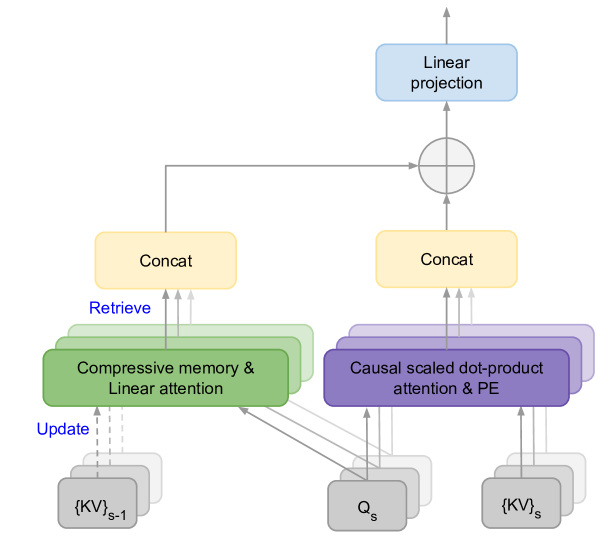
Abstract
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces a new attention mechanism called "Infini-attention" that enables Transformer models to efficiently process unlimited context.
- This addresses the challenge of long-context learning, where large language models struggle to effectively leverage information beyond a fixed-size context window.
- The Infini-attention mechanism allows the model to dynamically allocate attention resources based on the importance of different parts of the input, enabling efficient processing of unbounded sequences.
Plain English Explanation
The paper describes a new technique called "Infini-attention" that helps AI language models better understand and use very long texts. Large language models are powerful, but they often struggle to fully utilize information from texts that are longer than a certain size. This is because they have a fixed "context window" that limits how much of the text they can consider at once.
The Infini-attention mechanism solves this problem by allowing the model to dynamically focus its attention on the most relevant parts of the input, no matter how long the text is. It's like the model can zoom in on the important details while still keeping the overall context in mind, rather than just looking at a small section at a time. This enables the model to effectively leverage information from long contexts, which is crucial for tasks like summarization, question answering, and open-ended generation.
Technical Explanation
The key innovation in this work is the Infini-attention mechanism, which builds on previous approaches like Attention Sinks and Infini-Gram. Infini-attention allows the model to dynamically allocate attention resources based on the importance of different parts of the input sequence, rather than using a fixed-size context window.
This is achieved by maintaining an unbounded memory of past attention weights, which are used to guide the attention mechanism as the model processes new inputs. The model can then selectively focus on the most relevant parts of the context, unlocking the potential of large language models to effectively leverage long-range dependencies.
The authors evaluate the Infini-attention mechanism on various language modeling benchmarks and demonstrate its superior performance compared to standard Transformer models, especially in tasks that require long-range reasoning and integration of information across large contexts.
Critical Analysis
The paper presents a compelling solution to the long-standing challenge of long-context learning in large language models. The Infini-attention mechanism is a significant technical advance that could have widespread implications for the field of natural language processing.
However, the authors acknowledge that there are still some limitations to their approach. For example, the unbounded memory required by Infini-attention may have high computational and storage costs, particularly for very long inputs. Additionally, the paper does not explore the potential biases or unintended behaviors that could arise from the model's ability to selectively focus on certain parts of the input.
Further research is needed to fully understand the strengths and weaknesses of the Infini-attention mechanism, as well as its applicability to a wider range of language tasks and domains. It will also be important to investigate potential trade-offs between efficiency and performance and to explore ways to make the approach more scalable and practical for real-world deployment.
Conclusion
The "Leave No Context Behind" paper presents a novel Infini-attention mechanism that enables Transformer-based language models to efficiently process unlimited context, addressing a key limitation of large language models. This work represents an important step forward in the quest to build AI systems that can truly understand and reason about long-form, complex textual data.
The Infini-attention approach has the potential to unlock new capabilities in language models, enabling them to better capture and leverage long-range dependencies for a wide range of natural language processing tasks. As the field continues to push the boundaries of what is possible with large language models, this research is a valuable contribution that could have significant impacts on the future development of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Folded context condensation in Path Integral formalism for infinite context transformers
Won-Gi Paeng, Daesuk Kwon
0
0
This short note is written for rapid communication of long context training and to share the idea of how to train it with low memory usage. In the note, we generalize the attention algorithm and neural network of Generative Pre-Trained Transformers and reinterpret it in Path integral formalism. First, the role of the transformer is understood as the time evolution of the token state and second, it is suggested that the all key-token states in the same time as the query-token can attend to the attention with the query token states. As a result of the repetitive time evolution, it is discussed that the token states in the past sequence meats the token states in the present sequence so that the attention between separated sequences becomes possible for maintaining infinite contextual information just by using low memory for limited size of sequence. For the experiment, the $12$ input token window size was taken and one GPU with $24$GB memory was used for the pre-training. It was confirmed that more than $150$ length context is preserved. The sampling result of the training, the code and the other details will be included in the revised version of this note later.
5/13/2024

New!Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024
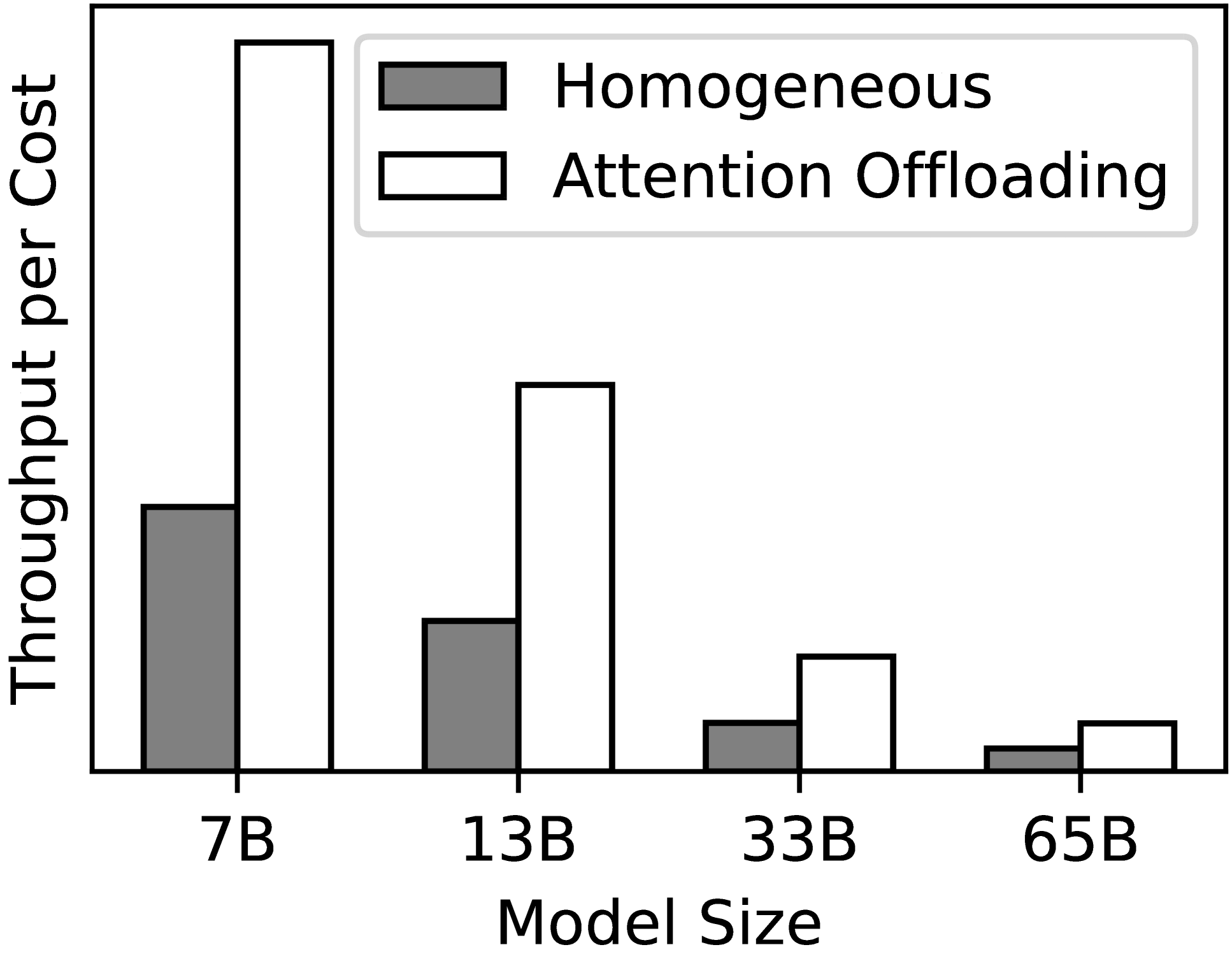
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
💬
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis
0
0
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach -- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a sink even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup. Code and datasets are provided at https://github.com/mit-han-lab/streaming-llm.
4/9/2024