Efficient and Economic Large Language Model Inference with Attention Offloading
2405.01814
0
0
Abstract
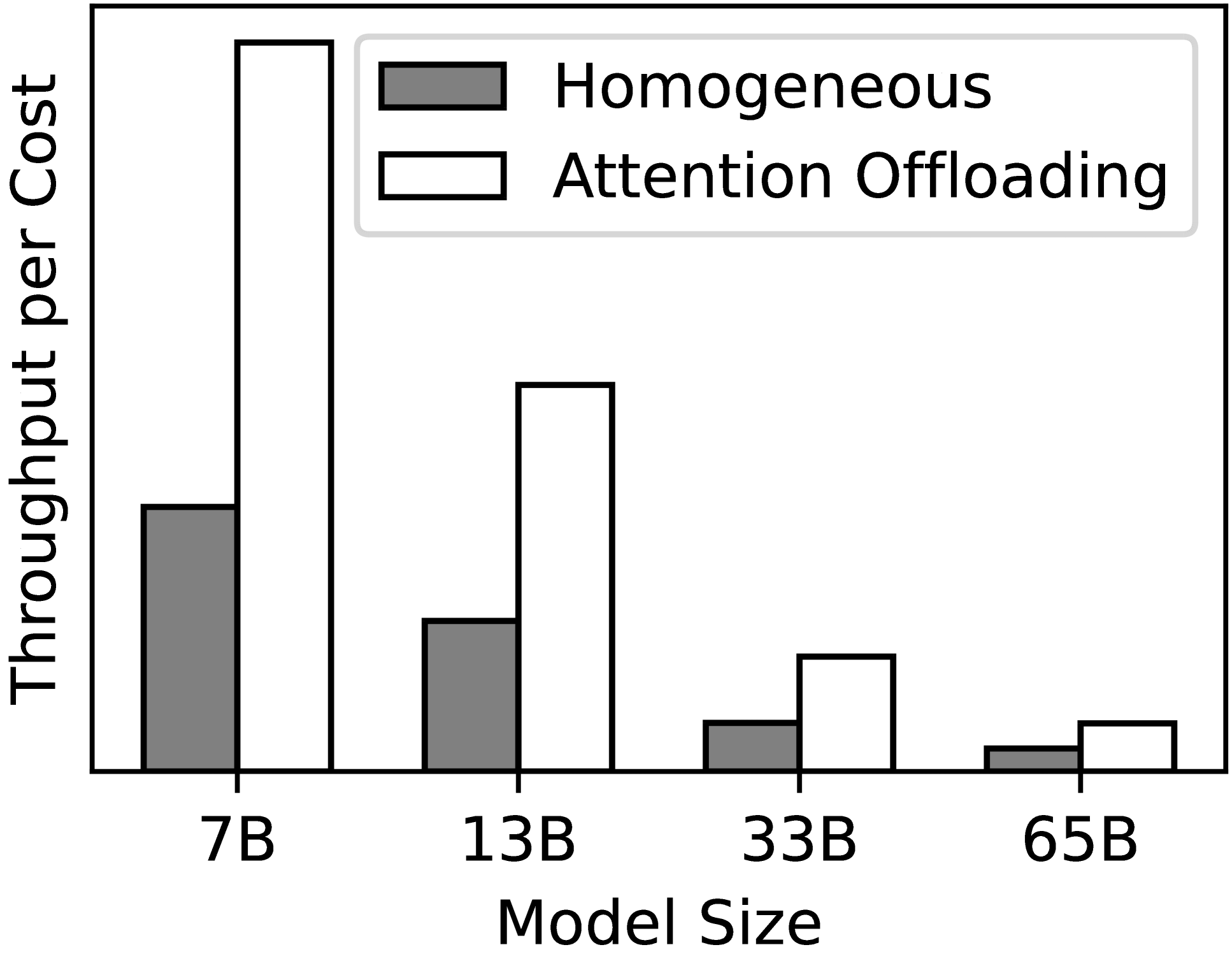
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
Create account to get full access
Overview
- This paper introduces a novel approach called "Attention Offloading" to efficiently and economically run large language models on resource-constrained devices.
- The key idea is to offload the attention mechanism, which is a computationally expensive component of large language models, to a remote server while keeping the rest of the model on the local device.
- This allows large language models to be deployed on edge devices with limited resources, while still maintaining high performance.
- The authors demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements in both inference speed and cost compared to running the full model on the local device.
Plain English Explanation
The paper is about a new way to use large language models, which are powerful AI systems that can understand and generate human-like text, on devices with limited computing power, like smartphones or smart home assistants. Large language models typically require a lot of computing resources to run, making it challenging to deploy them on these types of devices.
The key insight in this paper is to offload the most computationally intensive part of the language model, called the "attention" mechanism, to a remote server. The attention mechanism is responsible for understanding the relationships between different parts of the input text, which is crucial for generating high-quality output. By offloading this component, the authors can run the rest of the language model on the local device, while still maintaining the model's performance.
This approach allows large language models to be used on devices with limited resources, like Leave No Context Behind: Efficient Infinite Context for Language Models and Enhancing Inference Efficiency of Large Language Models by Investigating Different Approaches. It could enable a wide range of new applications, such as Attention-Driven Reasoning: Unlocking the Potential of Large Language Models, where large language models are used in smart home assistants, language translation apps, or other devices with limited computing power.
Technical Explanation
The key technical contribution of this paper is the "Attention Offloading" approach, which separates the computationally expensive attention mechanism from the rest of the language model. The authors implement this by:
- Identifying the attention computation as the main bottleneck in large language model inference.
- Developing a novel architecture that offloads the attention computation to a remote server, while keeping the rest of the model on the local device.
- Designing efficient communication protocols and caching mechanisms to minimize the overhead of offloading the attention computation.
Through extensive experiments, the authors demonstrate that their Attention Offloading approach significantly improves both the inference speed and cost (in terms of compute resources) compared to running the full model on the local device. They show that their method can achieve up to 3.5x speedup in inference time and 3x reduction in compute costs, without compromising the model's performance.
The authors also analyze the trade-offs between various design choices, such as the level of offloading, the caching strategy, and the communication overhead, to provide insights for practitioners looking to deploy large language models on resource-constrained devices.
Critical Analysis
The Attention Offloading approach presented in this paper is a promising solution for efficiently deploying large language models on edge devices. However, there are a few potential limitations and areas for further research:
-
Latency and network dependence: While the authors address the communication overhead, the approach still relies on a remote server for the attention computation. This introduces latency and network dependence, which may be a concern for some real-time applications, such as Self-Selected Attention Span: Accelerating Large Language Models via Learned Attention Span.
-
Security and privacy: Offloading sensitive data to a remote server raises potential security and privacy concerns, especially for applications handling personal or sensitive information. The authors do not discuss how these issues could be addressed.
-
Generalization to other model architectures: The current approach is focused on the specific attention mechanism used in transformer-based language models. It would be valuable to explore whether the principles of Attention Offloading can be extended to other model architectures, such as Survey of Efficient Inference Methods for Large Language Models.
-
Impact on model fine-tuning and adaptation: The paper does not discuss how the Attention Offloading approach might affect the model's ability to be fine-tuned or adapted to specific domains or tasks. This could be an important consideration for real-world deployments.
Overall, the Attention Offloading approach is a thoughtful and well-executed contribution to the challenge of efficient large language model inference. Further research addressing the potential limitations could lead to even more practical and widely-applicable solutions.
Conclusion
This paper presents a novel "Attention Offloading" approach that enables efficient and cost-effective deployment of large language models on resource-constrained devices. By offloading the computationally expensive attention mechanism to a remote server while keeping the rest of the model on the local device, the authors demonstrate significant improvements in both inference speed and compute costs without sacrificing model performance.
The insights and techniques developed in this work have the potential to unlock new applications of large language models in edge computing scenarios, such as smart home assistants, language translation apps, and other AI-powered services running on devices with limited resources. As the demand for large language models continues to grow, strategies like Attention Offloading will become increasingly important for making these powerful AI systems accessible and practical for a wide range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Self-Selected Attention Span for Accelerating Large Language Model Inference
Tian Jin, Wanzin Yazar, Zifei Xu, Sayeh Sharify, Xin Wang
0
0
Large language models (LLMs) can solve challenging tasks. However, their inference computation on modern GPUs is highly inefficient due to the increasing number of tokens they must attend to as they generate new ones. To address this inefficiency, we capitalize on LLMs' problem-solving capabilities to optimize their own inference-time efficiency. We demonstrate with two specific tasks: (a) evaluating complex arithmetic expressions and (b) summarizing news articles. For both tasks, we create custom datasets to fine-tune an LLM. The goal of fine-tuning is twofold: first, to make the LLM learn to solve the evaluation or summarization task, and second, to train it to identify the minimal attention spans required for each step of the task. As a result, the fine-tuned model is able to convert these self-identified minimal attention spans into sparse attention masks on-the-fly during inference. We develop a custom CUDA kernel to take advantage of the reduced context to attend to. We demonstrate that using this custom CUDA kernel improves the throughput of LLM inference by 28%. Our work presents an end-to-end demonstration showing that training LLMs to self-select their attention spans speeds up autoregressive inference in solving real-world tasks.
4/16/2024

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024

When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
Haoran You (Celine), Yichao Fu (Celine), Zheng Wang (Celine), Amir Yazdanbakhsh (Celine), Yingyan (Celine), Lin
0
0
Autoregressive Large Language Models (LLMs) have achieved impressive performance in language tasks but face two significant bottlenecks: (1) quadratic complexity in the attention module as the number of tokens increases, and (2) limited efficiency due to the sequential processing nature of autoregressive LLMs during generation. While linear attention and speculative decoding offer potential solutions, their applicability and synergistic potential for enhancing autoregressive LLMs remain uncertain. We conduct the first comprehensive study on the efficacy of existing linear attention methods for autoregressive LLMs, integrating them with speculative decoding. We introduce an augmentation technique for linear attention that ensures compatibility with speculative decoding, enabling more efficient training and serving of LLMs. Extensive experiments and ablation studies involving seven existing linear attention models and five encoder/decoder-based LLMs consistently validate the effectiveness of our augmented linearized LLMs. Notably, our approach achieves up to a 6.67 reduction in perplexity on the LLaMA model and up to a 2$times$ speedup during generation compared to prior linear attention methods. Codes and models are available at https://github.com/GATECH-EIC/Linearized-LLM.
6/12/2024
🤯
Efficient LLM inference solution on Intel GPU
Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu, Peng Zhao
0
0
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency. In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.
6/26/2024