C-ICL: Contrastive In-context Learning for Information Extraction
2402.11254
0
0
⛏️
Abstract
There has been increasing interest in exploring the capabilities of advanced large language models (LLMs) in the field of information extraction (IE), specifically focusing on tasks related to named entity recognition (NER) and relation extraction (RE). Although researchers are exploring the use of few-shot information extraction through in-context learning with LLMs, they tend to focus only on using correct or positive examples for demonstration, neglecting the potential value of incorporating incorrect or negative examples into the learning process. In this paper, we present c-ICL, a novel few-shot technique that leverages both correct and incorrect sample constructions to create in-context learning demonstrations. This approach enhances the ability of LLMs to extract entities and relations by utilizing prompts that incorporate not only the positive samples but also the reasoning behind them. This method allows for the identification and correction of potential interface errors. Specifically, our proposed method taps into the inherent contextual information and valuable information in hard negative samples and the nearest positive neighbors to the test and then applies the in-context learning demonstrations based on LLMs. Our experiments on various datasets indicate that c-ICL outperforms previous few-shot in-context learning methods, delivering substantial enhancements in performance across a broad spectrum of related tasks. These improvements are noteworthy, showcasing the versatility of our approach in miscellaneous scenarios.
Create account to get full access
Overview
- The paper explores using advanced large language models (LLMs) for information extraction tasks like named entity recognition (NER) and relation extraction (RE)
- Researchers often focus on using only correct or positive examples for demonstrations in few-shot information extraction, neglecting the potential value of incorporating incorrect or negative examples
- The paper presents a novel technique called c-ICL that leverages both correct and incorrect sample constructions to create in-context learning demonstrations, enhancing the ability of LLMs to extract entities and relations
Plain English Explanation
The paper is about using powerful language models, called large language models (LLMs), to extract information from text - things like identifying named entities (people, places, organizations, etc.) and the relationships between them. Researchers have been exploring how these LLMs can be used for this kind of information extraction in a "few-shot" way, where the model only needs a small number of examples to learn a new task.
However, the researchers noticed that most of the work in this area has focused only on using correct or positive examples to demonstrate the task to the LLM. They thought there might be value in also incorporating incorrect or negative examples, to help the model better understand what the task is looking for.
So the researchers developed a new technique called c-ICL (which stands for "context-based in-context learning"). This method uses prompts that include both correct and incorrect examples, along with an explanation of why the correct ones are right and the incorrect ones are wrong. The researchers believe this helps the LLM learn the task more effectively, allowing it to better identify entities and relationships in new text.
Technical Explanation
The c-ICL technique works by creating in-context learning demonstrations that incorporate both positive (correct) and negative (incorrect) sample constructions. These demonstrations tap into the inherent contextual information and valuable insights provided by the hard negative samples and the nearest positive neighbors to the test case.
The key idea is that by showing the model examples of both correct and incorrect ways to perform the information extraction task, along with explanations, the LLM can better learn the underlying patterns and rules. This enhances the model's ability to accurately identify named entities and extract relationships, compared to approaches that only use positive examples.
The researchers tested c-ICL on various datasets and found that it outperformed previous few-shot in-context learning methods, delivering substantial improvements in performance across a range of related tasks. This suggests the c-ICL approach is a versatile and effective way to leverage LLMs for few-shot information extraction in low-resource scenarios.
Critical Analysis
The paper presents a novel and promising technique for improving the performance of LLMs on information extraction tasks. However, the researchers acknowledge that their approach does have some limitations. For example, the effectiveness of c-ICL may depend on the quality and diversity of the negative examples used in the demonstrations.
Additionally, the paper does not provide a detailed analysis of the computational complexity or training time requirements of the c-ICL method, which could be an important consideration for real-world applications. The researchers also note the need for further research to better understand the underlying mechanisms and optimal configurations for this technique.
Overall, the c-ICL approach represents an interesting and potentially impactful contribution to the field of few-shot information extraction using large language models. While there are some areas for further exploration, the promising results suggest the technique is worth considering for researchers and practitioners working in this domain.
Conclusion
This paper presents a novel technique called c-ICL that leverages both correct and incorrect sample constructions to create in-context learning demonstrations for large language models (LLMs) engaged in information extraction tasks. By incorporating negative examples and explanations into the learning process, c-ICL enhances the ability of LLMs to accurately identify named entities and extract relationships from text.
The researchers' experiments show that c-ICL outperforms previous few-shot in-context learning methods, delivering substantial performance improvements across a range of related tasks. This suggests the versatility and effectiveness of the c-ICL approach in low-resource scenarios where only limited training data is available.
While the paper identifies some potential limitations and areas for future research, the c-ICL technique represents an exciting advancement in the field of few-shot information extraction using powerful language models. As LLMs continue to evolve, approaches like c-ICL could play an increasingly important role in unlocking their potential for a wide variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
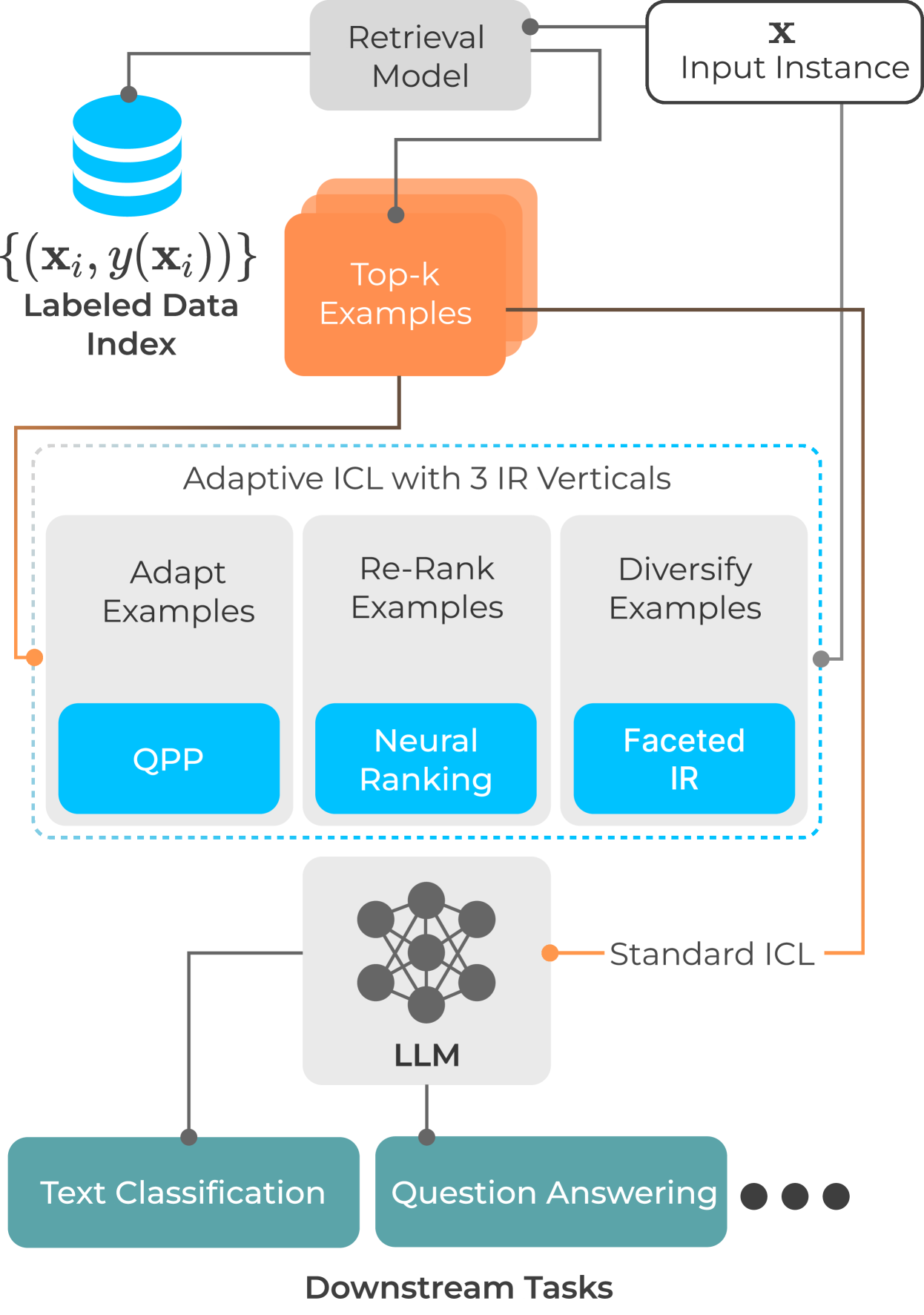
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
0
0
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
5/3/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
💬
LLMs Are Few-Shot In-Context Low-Resource Language Learners
Samuel Cahyawijaya, Holy Lovenia, Pascale Fung
0
0
In-context learning (ICL) empowers large language models (LLMs) to perform diverse tasks in underrepresented languages using only short in-context information, offering a crucial avenue for narrowing the gap between high-resource and low-resource languages. Nonetheless, there is only a handful of works explored ICL for low-resource languages with most of them focusing on relatively high-resource languages, such as French and Spanish. In this work, we extensively study ICL and its cross-lingual variation (X-ICL) on 25 low-resource and 7 relatively higher-resource languages. Our study not only assesses the effectiveness of ICL with LLMs in low-resource languages but also identifies the shortcomings of in-context label alignment, and introduces a more effective alternative: query alignment. Moreover, we provide valuable insights into various facets of ICL for low-resource languages. Our study concludes the significance of few-shot in-context information on enhancing the low-resource understanding quality of LLMs through semantically relevant information by closing the language gap in the target language and aligning the semantics between the targeted low-resource and the high-resource language that the model is proficient in. Our work highlights the importance of advancing ICL research, particularly for low-resource languages. Our code is publicly released at https://github.com/SamuelCahyawijaya/in-context-alignment
6/26/2024
💬
Hint-enhanced In-Context Learning wakes Large Language Models up for knowledge-intensive tasks
Yifan Wang, Qingyan Guo, Xinzhe Ni, Chufan Shi, Lemao Liu, Haiyun Jiang, Yujiu Yang
0
0
In-context learning (ICL) ability has emerged with the increasing scale of large language models (LLMs), enabling them to learn input-label mappings from demonstrations and perform well on downstream tasks. However, under the standard ICL setting, LLMs may sometimes neglect query-related information in demonstrations, leading to incorrect predictions. To address this limitation, we propose a new paradigm called Hint-enhanced In-Context Learning (HICL) to explore the power of ICL in open-domain question answering, an important form in knowledge-intensive tasks. HICL leverages LLMs' reasoning ability to extract query-related knowledge from demonstrations, then concatenates the knowledge to prompt LLMs in a more explicit way. Furthermore, we track the source of this knowledge to identify specific examples, and introduce a Hint-related Example Retriever (HER) to select informative examples for enhanced demonstrations. We evaluate HICL with HER on 3 open-domain QA benchmarks, and observe average performance gains of 2.89 EM score and 2.52 F1 score on gpt-3.5-turbo, 7.62 EM score and 7.27 F1 score on LLaMA-2-Chat-7B compared with standard setting.
4/19/2024