C-Mamba: Channel Correlation Enhanced State Space Models for Multivariate Time Series Forecasting

0

Sign in to get full access
Overview
- This paper introduces a novel time series forecasting model called C-Mamba, which enhances traditional state space models by incorporating channel correlation information.
- C-Mamba is designed to improve multivariate time series forecasting by capturing the complex relationships between different channels or features of the data.
- The paper compares C-Mamba's performance to other state-of-the-art time series forecasting models on several benchmark datasets, demonstrating its superior accuracy and efficiency.
Plain English Explanation
C-Mamba is a new type of forecasting model that can make predictions about the future values of multiple variables or "channels" of data at the same time. Traditional forecasting models often treat each channel independently, but C-Mamba recognizes that the channels are often related and can use this information to make more accurate predictions.
The key insight behind C-Mamba is that by understanding how the different channels of data are correlated with each other, the model can learn more about the underlying patterns and dynamics of the system being studied. This allows C-Mamba to outperform other forecasting models, especially when dealing with complex, multivariate time series data.
C-Mamba builds upon previous state-space models like MAMBA and Bi-MAMBA, incorporating additional mechanisms to capture the relationships between different channels of data. This helps the model make more accurate predictions, especially for datasets with complex, interdependent variables.
Technical Explanation
C-Mamba is a state-space model that extends previous work on the MAMBA and Bi-MAMBA models. The key innovation in C-Mamba is the incorporation of channel correlation information into the state-space representation.
Traditionally, state-space models treat each channel or variable in a multivariate time series independently, modeling the dynamics of each channel separately. In contrast, C-Mamba learns a shared latent state representation that captures the relationships between the different channels, allowing it to make more accurate joint predictions.
The authors evaluate C-Mamba on several benchmark time series forecasting datasets and compare its performance to other state-of-the-art models, including MAMBATS and Coupled-MAMBA. The results demonstrate that C-Mamba is able to outperform these other approaches, particularly on multivariate datasets where the relationships between channels are important for accurate forecasting.
Critical Analysis
The C-Mamba paper presents a novel and promising approach to multivariate time series forecasting. By incorporating channel correlation information into the state-space representation, the model is able to capture more complex patterns in the data and make more accurate joint predictions.
One potential limitation of the C-Mamba approach is that it may be computationally more expensive than simpler, channel-independent models, especially as the number of channels grows. The paper does not provide a detailed analysis of the computational complexity or runtime of the C-Mamba algorithm.
Additionally, the paper only evaluates C-Mamba on a limited set of benchmark datasets. While the results are promising, it would be helpful to see how the model performs on a wider range of real-world, large-scale time series datasets with varying levels of complexity and interdependence between channels.
Finally, the authors do not discuss potential limitations or failure modes of the C-Mamba approach. It would be valuable to understand the types of datasets or scenarios where C-Mamba may struggle, as well as any potential biases or vulnerabilities in the model.
Conclusion
Overall, the C-Mamba paper presents a novel and compelling approach to multivariate time series forecasting. By incorporating channel correlation information into the state-space representation, the model is able to capture more complex patterns in the data and make more accurate joint predictions.
The experimental results demonstrate the superiority of C-Mamba over other state-of-the-art models, particularly on datasets where the relationships between channels are important for accurate forecasting. This suggests that C-Mamba could be a valuable tool for a wide range of applications, from supply chain optimization to financial modeling and beyond.
While the paper leaves some open questions and areas for further research, the core ideas behind C-Mamba represent an important step forward in the field of time series forecasting. As the amount and complexity of multivariate data continues to grow, models like C-Mamba will become increasingly crucial for extracting meaningful insights and making accurate predictions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
C-Mamba: Channel Correlation Enhanced State Space Models for Multivariate Time Series Forecasting
Chaolv Zeng, Zhanyu Liu, Guanjie Zheng, Linghe Kong
In recent years, significant progress has been made in multivariate time series forecasting using Linear-based, Transformer-based, and Convolution-based models. However, these approaches face notable limitations: linear forecasters struggle with representation capacities, attention mechanisms suffer from quadratic complexity, and convolutional models have a restricted receptive field. These constraints impede their effectiveness in modeling complex time series, particularly those with numerous variables. Additionally, many models adopt the Channel-Independent (CI) strategy, treating multivariate time series as uncorrelated univariate series while ignoring their correlations. For models considering inter-channel relationships, whether through the self-attention mechanism, linear combination, or convolution, they all incur high computational costs and focus solely on weighted summation relationships, neglecting potential proportional relationships between channels. In this work, we address these issues by leveraging the newly introduced state space model and propose textbf{C-Mamba}, a novel approach that captures cross-channel dependencies while maintaining linear complexity without losing the global receptive field. Our model consists of two key components: (i) channel mixup, where two channels are mixed to enhance the training sets; (ii) channel attention enhanced patch-wise Mamba encoder that leverages the ability of the state space models to capture cross-time dependencies and models correlations between channels by mining their weight relationships. Our model achieves state-of-the-art performance on seven real-world time series datasets. Moreover, the proposed mixup and attention strategy exhibits strong generalizability across other frameworks.
Read more8/20/2024

0
CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration
Rui Deng, Tianpei Gu
Reconstructing degraded images is a critical task in image processing. Although CNN and Transformer-based models are prevalent in this field, they exhibit inherent limitations, such as inadequate long-range dependency modeling and high computational costs. To overcome these issues, we introduce the Channel-Aware U-Shaped Mamba (CU-Mamba) model, which incorporates a dual State Space Model (SSM) framework into the U-Net architecture. CU-Mamba employs a Spatial SSM module for global context encoding and a Channel SSM component to preserve channel correlation features, both in linear computational complexity relative to the feature map size. Extensive experimental results validate CU-Mamba's superiority over existing state-of-the-art methods, underscoring the importance of integrating both spatial and channel contexts in image restoration.
Read more4/19/2024
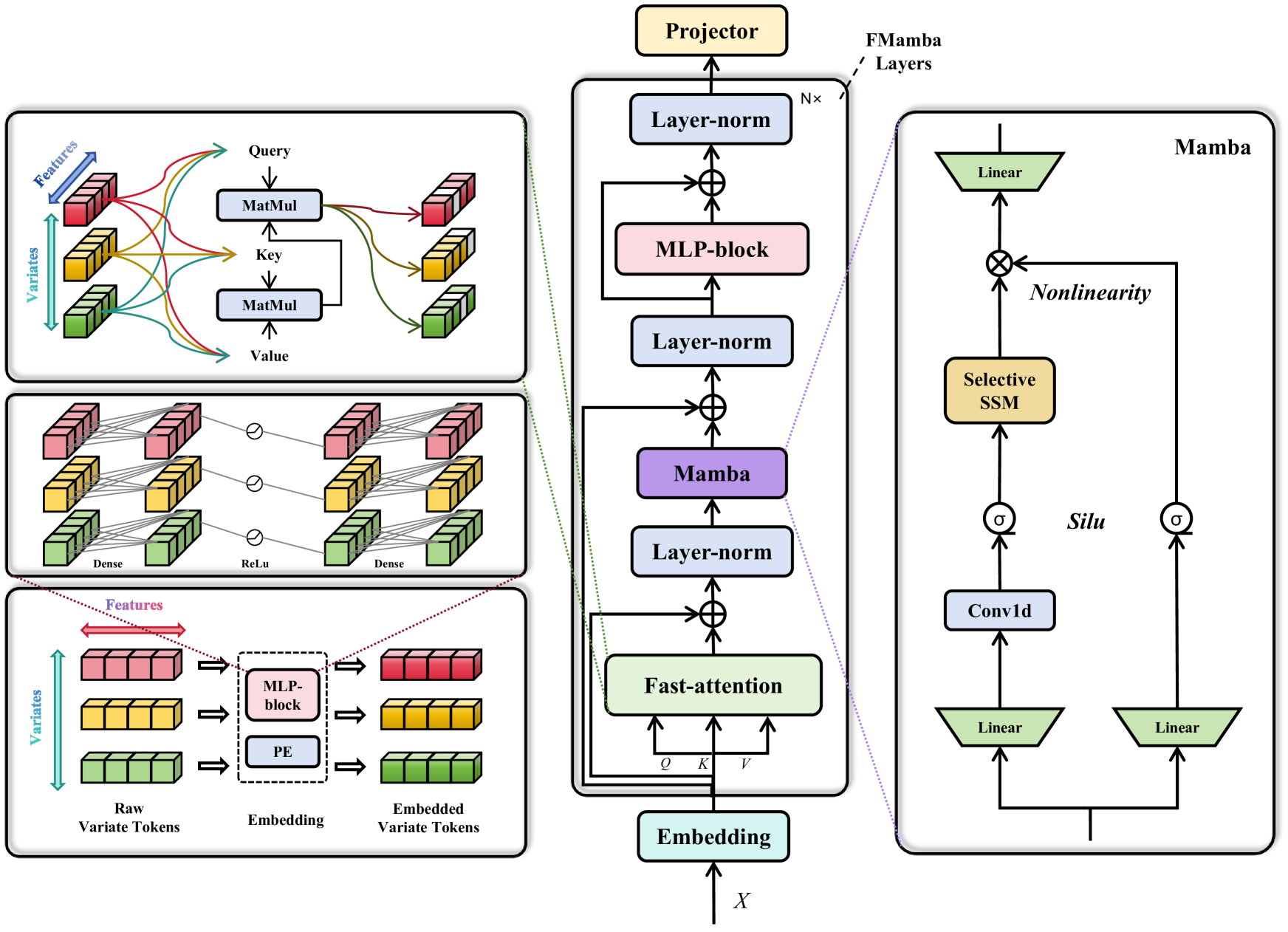
0
FMamba: Mamba based on Fast-attention for Multivariate Time-series Forecasting
Shusen Ma, Yu Kang, Peng Bai, Yun-Bo Zhao
In multivariate time-series forecasting (MTSF), extracting the temporal correlations of the input sequences is crucial. While popular Transformer-based predictive models can perform well, their quadratic computational complexity results in inefficiency and high overhead. The recently emerged Mamba, a selective state space model, has shown promising results in many fields due to its strong temporal feature extraction capabilities and linear computational complexity. However, due to the unilateral nature of Mamba, channel-independent predictive models based on Mamba cannot attend to the relationships among all variables in the manner of Transformer-based models. To address this issue, we combine fast-attention with Mamba to introduce a novel framework named FMamba for MTSF. Technically, we first extract the temporal features of the input variables through an embedding layer, then compute the dependencies among input variables via the fast-attention module. Subsequently, we use Mamba to selectively deal with the input features and further extract the temporal dependencies of the variables through the multi-layer perceptron block (MLP-block). Finally, FMamba obtains the predictive results through the projector, a linear layer. Experimental results on eight public datasets demonstrate that FMamba can achieve state-of-the-art performance while maintaining low computational overhead.
Read more7/23/2024
🤷
91
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Read more6/3/2024