FMamba: Mamba based on Fast-attention for Multivariate Time-series Forecasting

0
Sign in to get full access
Overview
- FMamba is a new multivariate time-series forecasting model based on the Mamba architecture and fast-attention mechanisms.
- The paper proposes several key innovations to improve the performance and efficiency of Mamba for complex forecasting tasks.
- Experimental results show FMamba outperforming state-of-the-art models on various multivariate time-series datasets.
Plain English Explanation
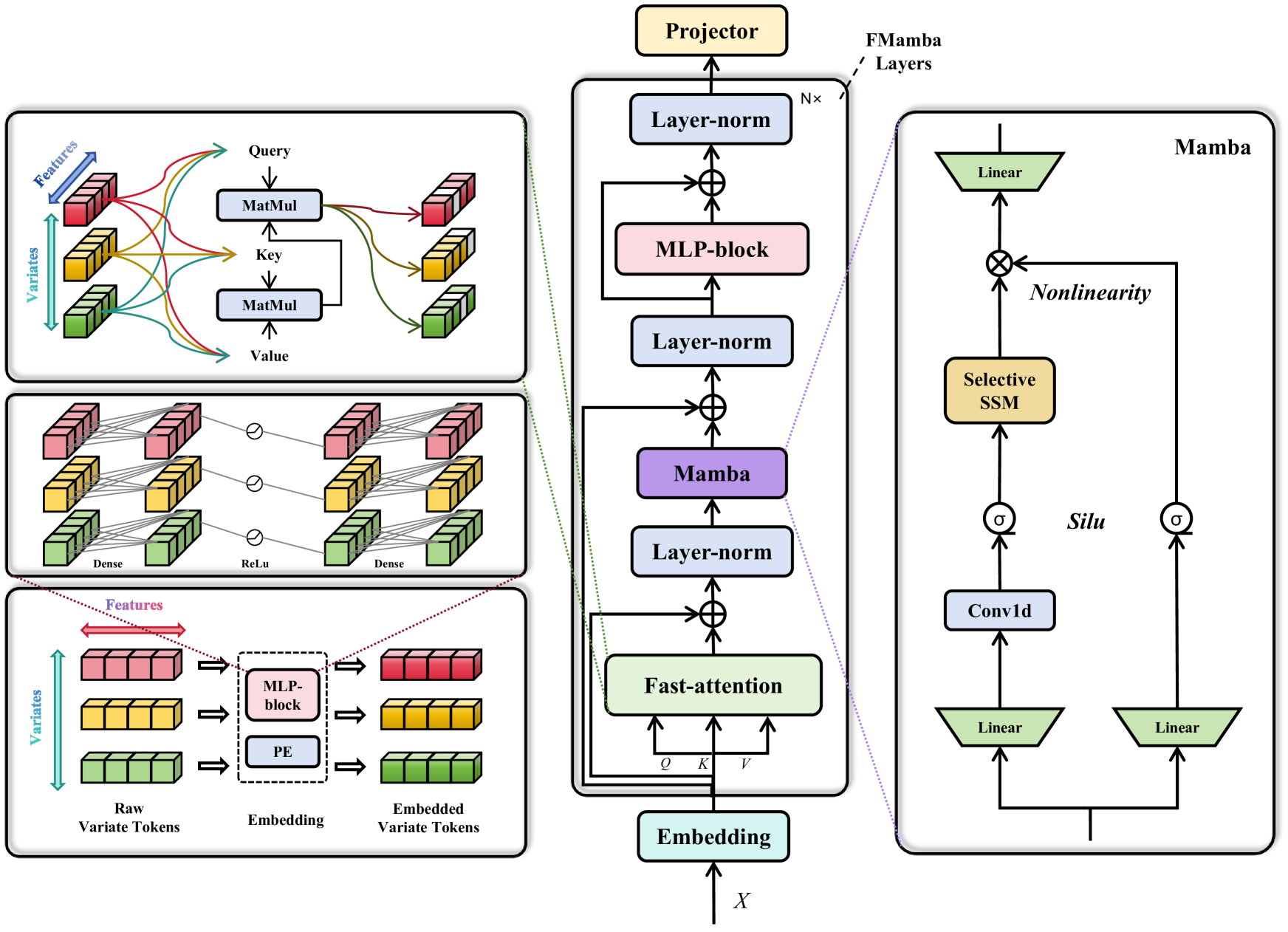
FMamba is a new machine learning model designed to forecast future values in complex, multi-variable time-series data. It builds on the existing Mamba architecture, which uses advanced techniques like state-space models and transformer-based attention to capture both short-term and long-term dependencies in the data.
The key innovations in FMamba are the use of "fast-attention" mechanisms, which can efficiently process long input sequences, and other architectural changes to improve the model's performance and computational efficiency. This allows FMamba to better handle the complexities of real-world multivariate time-series forecasting problems, like forecasting multiple interdependent variables over long time horizons.
Technical Explanation
The paper first reviews relevant prior work on time-series forecasting, including the original Mamba model and other state-of-the-art approaches like Transformers and channel-correlation enhanced models.
The core of the FMamba architecture is built around a fast-attention mechanism that can efficiently operate on long input sequences, a key limitation of standard attention mechanisms. This is combined with other Mamba components like the state-space model and selective updating to capture both short-term and long-term patterns in the data.
The paper also introduces several other architectural innovations, such as multi-head attention and residual connections, to further improve the model's performance and stability. Comprehensive experiments are conducted on multiple real-world multivariate time-series datasets, demonstrating that FMamba outperforms other leading forecasting models.
Critical Analysis
The paper provides a thorough technical explanation of the FMamba model and its key innovations. The experimental results are compelling, showing significant performance improvements over state-of-the-art forecasting approaches.
However, the paper does not extensively discuss the potential limitations or caveats of the FMamba model. For example, it would be helpful to know how the model's performance scales with the size and complexity of the input time-series, or how sensitive it is to hyperparameter tuning and other implementation details.
Additionally, while the paper highlights the efficiency advantages of the fast-attention mechanism, it would be valuable to see more analysis on the actual computational and memory requirements of FMamba compared to other models, especially for real-world deployment scenarios.
Conclusion
The FMamba model represents an important advance in multivariate time-series forecasting, leveraging innovative attention mechanisms and other architectural enhancements to significantly improve upon existing state-of-the-art approaches. The strong empirical results demonstrate the practical potential of FMamba for tackling complex real-world forecasting problems.
While the paper could benefit from a more thorough discussion of the model's limitations and tradeoffs, it provides a solid technical foundation for further research and development in this area. Overall, FMamba is a promising contribution to the field of time-series forecasting that merits further exploration and refinement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FMamba: Mamba based on Fast-attention for Multivariate Time-series Forecasting
Shusen Ma, Yu Kang, Peng Bai, Yun-Bo Zhao
In multivariate time-series forecasting (MTSF), extracting the temporal correlations of the input sequences is crucial. While popular Transformer-based predictive models can perform well, their quadratic computational complexity results in inefficiency and high overhead. The recently emerged Mamba, a selective state space model, has shown promising results in many fields due to its strong temporal feature extraction capabilities and linear computational complexity. However, due to the unilateral nature of Mamba, channel-independent predictive models based on Mamba cannot attend to the relationships among all variables in the manner of Transformer-based models. To address this issue, we combine fast-attention with Mamba to introduce a novel framework named FMamba for MTSF. Technically, we first extract the temporal features of the input variables through an embedding layer, then compute the dependencies among input variables via the fast-attention module. Subsequently, we use Mamba to selectively deal with the input features and further extract the temporal dependencies of the variables through the multi-layer perceptron block (MLP-block). Finally, FMamba obtains the predictive results through the projector, a linear layer. Experimental results on eight public datasets demonstrate that FMamba can achieve state-of-the-art performance while maintaining low computational overhead.
Read more7/23/2024
0
Bi-Mamba+: Bidirectional Mamba for Time Series Forecasting
Aobo Liang, Xingguo Jiang, Yan Sun, Xiaohou Shi, Ke Li
Long-term time series forecasting (LTSF) provides longer insights into future trends and patterns. Over the past few years, deep learning models especially Transformers have achieved advanced performance in LTSF tasks. However, LTSF faces inherent challenges such as long-term dependencies capturing and sparse semantic characteristics. Recently, a new state space model (SSM) named Mamba is proposed. With the selective capability on input data and the hardware-aware parallel computing algorithm, Mamba has shown great potential in balancing predicting performance and computational efficiency compared to Transformers. To enhance Mamba's ability to preserve historical information in a longer range, we design a novel Mamba+ block by adding a forget gate inside Mamba to selectively combine the new features with the historical features in a complementary manner. Furthermore, we apply Mamba+ both forward and backward and propose Bi-Mamba+, aiming to promote the model's ability to capture interactions among time series elements. Additionally, multivariate time series data in different scenarios may exhibit varying emphasis on intra- or inter-series dependencies. Therefore, we propose a series-relation-aware decider that controls the utilization of channel-independent or channel-mixing tokenization strategy for specific datasets. Extensive experiments on 8 real-world datasets show that our model achieves more accurate predictions compared with state-of-the-art methods.
Read more6/28/2024

0
MambaTS: Improved Selective State Space Models for Long-term Time Series Forecasting
Xiuding Cai, Yaoyao Zhu, Xueyao Wang, Yu Yao
In recent years, Transformers have become the de-facto architecture for long-term sequence forecasting (LTSF), but faces challenges such as quadratic complexity and permutation invariant bias. A recent model, Mamba, based on selective state space models (SSMs), has emerged as a competitive alternative to Transformer, offering comparable performance with higher throughput and linear complexity related to sequence length. In this study, we analyze the limitations of current Mamba in LTSF and propose four targeted improvements, leading to MambaTS. We first introduce variable scan along time to arrange the historical information of all the variables together. We suggest that causal convolution in Mamba is not necessary for LTSF and propose the Temporal Mamba Block (TMB). We further incorporate a dropout mechanism for selective parameters of TMB to mitigate model overfitting. Moreover, we tackle the issue of variable scan order sensitivity by introducing variable permutation training. We further propose variable-aware scan along time to dynamically discover variable relationships during training and decode the optimal variable scan order by solving the shortest path visiting all nodes problem during inference. Extensive experiments conducted on eight public datasets demonstrate that MambaTS achieves new state-of-the-art performance.
Read more5/28/2024

0
Is Mamba Effective for Time Series Forecasting?
Zihan Wang, Fanheng Kong, Shi Feng, Ming Wang, Xiaocui Yang, Han Zhao, Daling Wang, Yifei Zhang
In the realm of time series forecasting (TSF), it is imperative for models to adeptly discern and distill hidden patterns within historical time series data to forecast future states. Transformer-based models exhibit formidable efficacy in TSF, primarily attributed to their advantage in apprehending these patterns. However, the quadratic complexity of the Transformer leads to low computational efficiency and high costs, which somewhat hinders the deployment of the TSF model in real-world scenarios. Recently, Mamba, a selective state space model, has gained traction due to its ability to process dependencies in sequences while maintaining near-linear complexity. For TSF tasks, these characteristics enable Mamba to comprehend hidden patterns as the Transformer and reduce computational overhead compared to the Transformer. Therefore, we propose a Mamba-based model named Simple-Mamba (S-Mamba) for TSF. Specifically, we tokenize the time points of each variate autonomously via a linear layer. A bidirectional Mamba layer is utilized to extract inter-variate correlations and a Feed-Forward Network is set to learn temporal dependencies. Finally, the generation of forecast outcomes through a linear mapping layer. Experiments on thirteen public datasets prove that S-Mamba maintains low computational overhead and achieves leading performance. Furthermore, we conduct extensive experiments to explore Mamba's potential in TSF tasks. Our code is available at https://github.com/wzhwzhwzh0921/S-D-Mamba.
Read more4/30/2024