C-RAG: Certified Generation Risks for Retrieval-Augmented Language Models
2402.03181
0
0
🛸
Abstract
Despite the impressive capabilities of large language models (LLMs) across diverse applications, they still suffer from trustworthiness issues, such as hallucinations and misalignments. Retrieval-augmented language models (RAG) have been proposed to enhance the credibility of generations by grounding external knowledge, but the theoretical understandings of their generation risks remains unexplored. In this paper, we answer: 1) whether RAG can indeed lead to low generation risks, 2) how to provide provable guarantees on the generation risks of RAG and vanilla LLMs, and 3) what sufficient conditions enable RAG models to reduce generation risks. We propose C-RAG, the first framework to certify generation risks for RAG models. Specifically, we provide conformal risk analysis for RAG models and certify an upper confidence bound of generation risks, which we refer to as conformal generation risk. We also provide theoretical guarantees on conformal generation risks for general bounded risk functions under test distribution shifts. We prove that RAG achieves a lower conformal generation risk than that of a single LLM when the quality of the retrieval model and transformer is non-trivial. Our intensive empirical results demonstrate the soundness and tightness of our conformal generation risk guarantees across four widely-used NLP datasets on four state-of-the-art retrieval models.
Create account to get full access
Overview
- Large language models (LLMs) have impressive capabilities, but still face issues with trustworthiness, including hallucinations and misalignments.
- Retrieval-augmented language models (RAG) have been proposed to improve the credibility of LLM generations by grounding them in external knowledge.
- However, the theoretical understanding of the generation risks of RAG models remains unexplored.
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text on a wide range of topics. While these models have shown remarkable capabilities, they still struggle with issues of trustworthiness. Sometimes, they can hallucinate or generate information that is factually incorrect or misaligned with the intended purpose.
To address these concerns, researchers have developed retrieval-augmented language models (RAG). RAG models try to enhance the credibility of their text generations by incorporating knowledge from external sources, such as databases or web pages. The idea is that by grounding the output in real information, RAG models can reduce the risks of hallucinations or misalignments.
However, the theoretical understanding of how well RAG models can mitigate generation risks is still an open question. This paper aims to provide a deeper analysis of the generation risks associated with RAG models and compare them to traditional LLMs.
Technical Explanation
This paper presents a framework called C-RAG (Conformal RAG) that can certify the generation risks of RAG models. The key contributions are:
-
Analyzing RAG Generation Risks: The authors investigate whether RAG models can indeed lead to lower generation risks compared to vanilla LLMs. They provide theoretical guarantees on the generation risks of both RAG and LLM models.
-
Conformal Risk Analysis: The C-RAG framework uses conformal risk analysis to provide an upper confidence bound on the generation risks of RAG models, which the authors call the "conformal generation risk."
-
Theoretical Guarantees: The paper proves that RAG achieves a lower conformal generation risk than a single LLM, as long as the quality of the retrieval model and transformer is reasonably good.
-
Empirical Validation: The authors conduct extensive experiments on four widely-used NLP datasets and four state-of-the-art retrieval models to demonstrate the soundness and tightness of their conformal generation risk guarantees.
Critical Analysis
The paper provides a solid theoretical and empirical analysis of the generation risks associated with RAG models, which is an important step in understanding the limitations and potential of these systems. The authors' approach of using conformal risk analysis to certify generation risks is a novel and promising direction.
However, a few caveats and areas for further research are worth noting:
-
The analysis assumes the availability of a high-quality retrieval model, which may not always be the case in real-world deployments. Further research is needed to understand the sensitivity of the results to the retrieval model quality.
-
The paper focuses on bounded risk functions, which may not capture all relevant aspects of generation risks. Exploring other risk measures or relaxing the bounded assumptions could lead to a more comprehensive understanding.
-
The empirical evaluation is limited to a few datasets and retrieval models. Expanding the scope of the experiments could provide a more robust assessment of the generalizability of the findings.
Overall, this paper makes a valuable contribution to the understanding of the trustworthiness of retrieval-augmented language models and sets the stage for further advancements in this important area of AI research.
Conclusion
This paper tackles the critical issue of trustworthiness in large language models by proposing a framework called C-RAG to analyze and certify the generation risks of retrieval-augmented language models (RAG). The key insight is that by grounding language model generations in external knowledge sources, RAG models can potentially achieve lower generation risks compared to traditional LLMs.
Through a combination of theoretical analysis and extensive empirical validation, the authors demonstrate that RAG models can indeed achieve lower certified generation risks, as long as the retrieval model and transformer are of reasonable quality. This work represents an important step towards developing more trustworthy and reliable language AI systems, which is crucial for their safe and ethical deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

BadRAG: Identifying Vulnerabilities in Retrieval Augmented Generation of Large Language Models
Jiaqi Xue, Mengxin Zheng, Yebowen Hu, Fei Liu, Xun Chen, Qian Lou
0
0
Large Language Models (LLMs) are constrained by outdated information and a tendency to generate incorrect data, commonly referred to as hallucinations. Retrieval-Augmented Generation (RAG) addresses these limitations by combining the strengths of retrieval-based methods and generative models. This approach involves retrieving relevant information from a large, up-to-date dataset and using it to enhance the generation process, leading to more accurate and contextually appropriate responses. Despite its benefits, RAG introduces a new attack surface for LLMs, particularly because RAG databases are often sourced from public data, such as the web. In this paper, we propose TrojRAG{} to identify the vulnerabilities and attacks on retrieval parts (RAG database) and their indirect attacks on generative parts (LLMs). Specifically, we identify that poisoning several customized content passages could achieve a retrieval backdoor, where the retrieval works well for clean queries but always returns customized poisoned adversarial queries. Triggers and poisoned passages can be highly customized to implement various attacks. For example, a trigger could be a semantic group like The Republican Party, Donald Trump, etc. Adversarial passages can be tailored to different contents, not only linked to the triggers but also used to indirectly attack generative LLMs without modifying them. These attacks can include denial-of-service attacks on RAG and semantic steering attacks on LLM generations conditioned by the triggers. Our experiments demonstrate that by just poisoning 10 adversarial passages can induce 98.2% success rate to retrieve the adversarial passages. Then, these passages can increase the reject ratio of RAG-based GPT-4 from 0.01% to 74.6% or increase the rate of negative responses from 0.22% to 72% for targeted queries.
6/7/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024
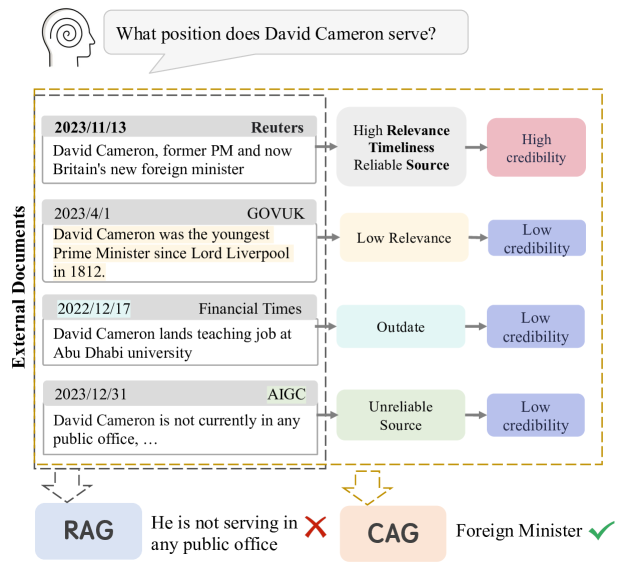
Not All Contexts Are Equal: Teaching LLMs Credibility-aware Generation
Ruotong Pan, Boxi Cao, Hongyu Lin, Xianpei Han, Jia Zheng, Sirui Wang, Xunliang Cai, Le Sun
0
0
The rapid development of large language models has led to the widespread adoption of Retrieval-Augmented Generation (RAG), which integrates external knowledge to alleviate knowledge bottlenecks and mitigate hallucinations. However, the existing RAG paradigm inevitably suffers from the impact of flawed information introduced during the retrieval phrase, thereby diminishing the reliability and correctness of the generated outcomes. In this paper, we propose Credibility-aware Generation (CAG), a universally applicable framework designed to mitigate the impact of flawed information in RAG. At its core, CAG aims to equip models with the ability to discern and process information based on its credibility. To this end, we propose an innovative data transformation framework that generates data based on credibility, thereby effectively endowing models with the capability of CAG. Furthermore, to accurately evaluate the models' capabilities of CAG, we construct a comprehensive benchmark covering three critical real-world scenarios. Experimental results demonstrate that our model can effectively understand and utilize credibility for generation, significantly outperform other models with retrieval augmentation, and exhibit resilience against the disruption caused by noisy documents, thereby maintaining robust performance. Moreover, our model supports customized credibility, offering a wide range of potential applications.
5/10/2024

Unveil the Duality of Retrieval-Augmented Generation: Theoretical Analysis and Practical Solution
Shicheng Xu, Liang Pang, Huawei Shen, Xueqi Cheng
0
0
Retrieval-augmented generation (RAG) utilizes retrieved texts to enhance large language models (LLMs). However, studies show that RAG is not consistently effective and can even mislead LLMs due to noisy or incorrect retrieved texts. This suggests that RAG possesses a duality including both benefit and detriment. Although many existing methods attempt to address this issue, they lack a theoretical explanation for the duality in RAG. The benefit and detriment within this duality remain a black box that cannot be quantified or compared in an explainable manner. This paper takes the first step in theoretically giving the essential explanation of benefit and detriment in RAG by: (1) decoupling and formalizing them from RAG prediction, (2) approximating the gap between their values by representation similarity and (3) establishing the trade-off mechanism between them, to make them explainable, quantifiable, and comparable. We demonstrate that the distribution difference between retrieved texts and LLMs' knowledge acts as double-edged sword, bringing both benefit and detriment. We also prove that the actual effect of RAG can be predicted at token level. Based on our theory, we propose a practical novel method, X-RAG, which achieves collaborative generation between pure LLM and RAG at token level to preserve benefit and avoid detriment. Experiments in real-world tasks based on LLMs including OPT, LLaMA-2, and Mistral show the effectiveness of our method and support our theoretical results.
6/4/2024