Not All Contexts Are Equal: Teaching LLMs Credibility-aware Generation
2404.06809
0
0
Abstract
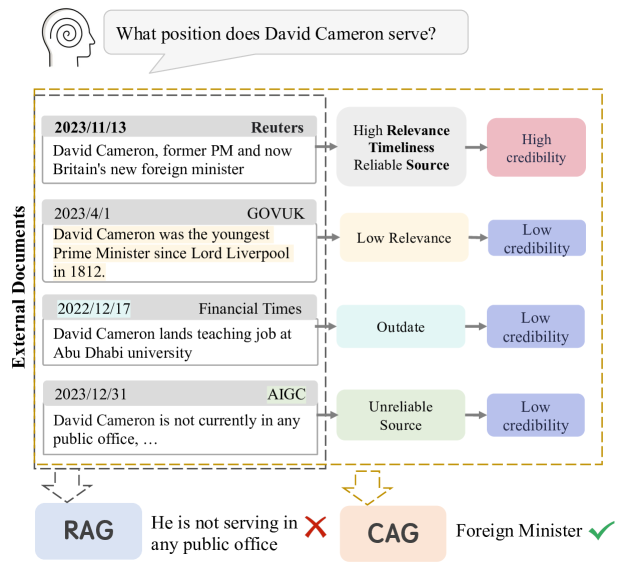
The rapid development of large language models has led to the widespread adoption of Retrieval-Augmented Generation (RAG), which integrates external knowledge to alleviate knowledge bottlenecks and mitigate hallucinations. However, the existing RAG paradigm inevitably suffers from the impact of flawed information introduced during the retrieval phrase, thereby diminishing the reliability and correctness of the generated outcomes. In this paper, we propose Credibility-aware Generation (CAG), a universally applicable framework designed to mitigate the impact of flawed information in RAG. At its core, CAG aims to equip models with the ability to discern and process information based on its credibility. To this end, we propose an innovative data transformation framework that generates data based on credibility, thereby effectively endowing models with the capability of CAG. Furthermore, to accurately evaluate the models' capabilities of CAG, we construct a comprehensive benchmark covering three critical real-world scenarios. Experimental results demonstrate that our model can effectively understand and utilize credibility for generation, significantly outperform other models with retrieval augmentation, and exhibit resilience against the disruption caused by noisy documents, thereby maintaining robust performance. Moreover, our model supports customized credibility, offering a wide range of potential applications.
Create account to get full access
Overview
- This research paper explores how to teach large language models (LLMs) to generate content that is credible and reliable, rather than simply generating plausible-sounding text.
- The key idea is that not all contexts are equal - some contexts provide stronger signals about the credibility of generated content than others.
- The paper proposes a framework for "credibility-aware generation" that aims to help LLMs understand which contexts are more or less credible, and generate content accordingly.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, this ability also comes with risks - LLMs can generate false or misleading information that appears convincing. This research paper explores ways to make LLMs more "credibility-aware" so they can generate content that is reliable and trustworthy.
The core insight is that the context surrounding the text generation task provides important clues about credibility. For example, if an LLM is generating text for a medical advice website, that context signals that the generated content should be factual and medically accurate. In contrast, if the LLM is generating text for a creative writing exercise, the credibility standards may be lower.
The paper proposes a framework to teach LLMs to be more aware of these contextual credibility signals, and to generate content that is appropriately credible for the given situation. This could help prevent LLMs from inadvertently spreading misinformation, and ensure they are used in a responsible and trustworthy manner.
Technical Explanation
The paper introduces the concept of "credibility-aware generation", which aims to help large language models (LLMs) understand the credibility standards that should be applied in different contexts. The key idea is that the context surrounding a text generation task provides important signals about the level of credibility that should be expected in the output.
The proposed framework consists of three main components:
- Credibility Classifier: This module evaluates the credibility of a given context, providing a score that reflects how credible the generated content should be.
- Credibility-Aware Generation: The language model is trained to consider the credibility score when generating text, adjusting its output to match the expected credibility level.
- Credibility Self-Reflection: During generation, the model continuously evaluates the credibility of its own output, and can refine or regenerate text if it falls short of the target credibility.
The paper evaluates this framework on several benchmarks, including CBR-RAG, CONFLARE, and Improving Medical Reasoning. The results demonstrate that credibility-aware generation can significantly improve the reliability and trustworthiness of LLM outputs, without sacrificing performance on standard language modeling tasks.
Critical Analysis
The paper presents a compelling approach to addressing the important challenge of ensuring the credibility and reliability of content generated by large language models. The key strength of the proposed framework is its ability to adapt the generation process based on contextual cues about credibility, rather than applying a one-size-fits-all approach.
However, the paper does not address some potential limitations and areas for further research. For example, it's not clear how the credibility classifier module would handle ambiguous or nuanced contexts, where the appropriate level of credibility may be less clear. Additionally, the paper does not explore how this framework might scale to broader real-world deployment, where LLMs may encounter an even wider range of contexts and credibility demands.
Further research could also investigate the generalizability of this approach beyond the specific benchmarks used in the paper, and explore ways to make the credibility self-reflection process more robust and transparent to users. Integrating this framework with other techniques for improving the reliability of LLM outputs, such as retrieval-augmented generation or prompt engineering, could also be a fruitful area for future work.
Conclusion
This research paper presents a novel framework for teaching large language models to be more "credibility-aware" when generating content. By considering the context of the generation task and continuously evaluating the credibility of the output, the proposed approach aims to help LLMs produce reliable and trustworthy information, rather than simply generating plausible-sounding text.
The findings suggest that this credibility-aware generation approach can significantly improve the reliability of LLM outputs, without sacrificing performance on standard language modeling tasks. While the paper identifies some potential areas for further research, the overall framework represents an important step towards developing AI systems that can generate content in a more responsible and trustworthy manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
C-RAG: Certified Generation Risks for Retrieval-Augmented Language Models
Mintong Kang, Nezihe Merve Gurel, Ning Yu, Dawn Song, Bo Li
0
0
Despite the impressive capabilities of large language models (LLMs) across diverse applications, they still suffer from trustworthiness issues, such as hallucinations and misalignments. Retrieval-augmented language models (RAG) have been proposed to enhance the credibility of generations by grounding external knowledge, but the theoretical understandings of their generation risks remains unexplored. In this paper, we answer: 1) whether RAG can indeed lead to low generation risks, 2) how to provide provable guarantees on the generation risks of RAG and vanilla LLMs, and 3) what sufficient conditions enable RAG models to reduce generation risks. We propose C-RAG, the first framework to certify generation risks for RAG models. Specifically, we provide conformal risk analysis for RAG models and certify an upper confidence bound of generation risks, which we refer to as conformal generation risk. We also provide theoretical guarantees on conformal generation risks for general bounded risk functions under test distribution shifts. We prove that RAG achieves a lower conformal generation risk than that of a single LLM when the quality of the retrieval model and transformer is non-trivial. Our intensive empirical results demonstrate the soundness and tightness of our conformal generation risk guarantees across four widely-used NLP datasets on four state-of-the-art retrieval models.
6/5/2024
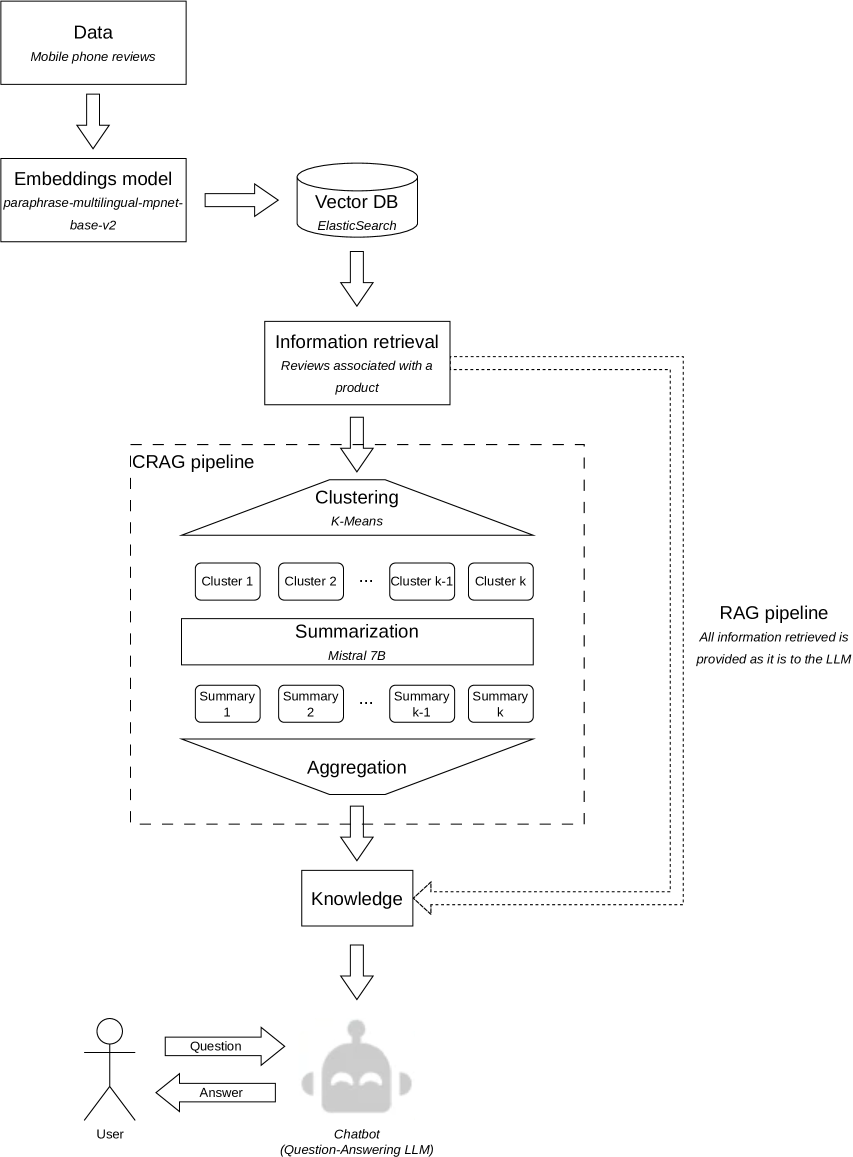
Clustered Retrieved Augmented Generation (CRAG)
Simon Akesson, Frances A. Santos
0
0
Providing external knowledge to Large Language Models (LLMs) is a key point for using these models in real-world applications for several reasons, such as incorporating up-to-date content in a real-time manner, providing access to domain-specific knowledge, and contributing to hallucination prevention. The vector database-based Retrieval Augmented Generation (RAG) approach has been widely adopted to this end. Thus, any part of external knowledge can be retrieved and provided to some LLM as the input context. Despite RAG approach's success, it still might be unfeasible for some applications, because the context retrieved can demand a longer context window than the size supported by LLM. Even when the context retrieved fits into the context window size, the number of tokens might be expressive and, consequently, impact costs and processing time, becoming impractical for most applications. To address these, we propose CRAG, a novel approach able to effectively reduce the number of prompting tokens without degrading the quality of the response generated compared to a solution using RAG. Through our experiments, we show that CRAG can reduce the number of tokens by at least 46%, achieving more than 90% in some cases, compared to RAG. Moreover, the number of tokens with CRAG does not increase considerably when the number of reviews analyzed is higher, unlike RAG, where the number of tokens is almost 9x higher when there are 75 reviews compared to 4 reviews.
6/4/2024

R^2AG: Incorporating Retrieval Information into Retrieval Augmented Generation
Fuda Ye, Shuangyin Li, Yongqi Zhang, Lei Chen
0
0
Retrieval augmented generation (RAG) has been applied in many scenarios to augment large language models (LLMs) with external documents provided by retrievers. However, a semantic gap exists between LLMs and retrievers due to differences in their training objectives and architectures. This misalignment forces LLMs to passively accept the documents provided by the retrievers, leading to incomprehension in the generation process, where the LLMs are burdened with the task of distinguishing these documents using their inherent knowledge. This paper proposes R$^2$AG, a novel enhanced RAG framework to fill this gap by incorporating Retrieval information into Retrieval Augmented Generation. Specifically, R$^2$AG utilizes the nuanced features from the retrievers and employs a R$^2$-Former to capture retrieval information. Then, a retrieval-aware prompting strategy is designed to integrate retrieval information into LLMs' generation. Notably, R$^2$AG suits low-source scenarios where LLMs and retrievers are frozen. Extensive experiments across five datasets validate the effectiveness, robustness, and efficiency of R$^2$AG. Our analysis reveals that retrieval information serves as an anchor to aid LLMs in the generation process, thereby filling the semantic gap.
6/21/2024

CodeRAG-Bench: Can Retrieval Augment Code Generation?
Zora Zhiruo Wang, Akari Asai, Xinyan Velocity Yu, Frank F. Xu, Yiqing Xie, Graham Neubig, Daniel Fried
0
0
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
6/21/2024