Calibrating Higher-Order Statistics for Few-Shot Class-Incremental Learning with Pre-trained Vision Transformers

0

Sign in to get full access
Overview
- This paper explores a method for improving few-shot class-incremental learning with pre-trained vision transformers.
- The key idea is to calibrate higher-order statistics of the pre-trained model to adapt it to new tasks with few examples.
- The approach aims to address the challenge of learning new visual concepts without forgetting previous knowledge.
Plain English Explanation
In machine learning, there is a common problem called "catastrophic forgetting," where a model trained on one set of tasks or classes forgets that information when trained on new tasks or classes. This makes it difficult to continuously learn new skills without losing old ones.
The researchers in this paper wanted to tackle this problem in the context of few-shot learning - where a model has to learn new visual concepts from just a handful of examples. They focused on using pre-trained vision transformer models, which are powerful image recognition models that have been trained on large datasets.
The core of their approach is to "calibrate" the higher-order statistics of the pre-trained model. In other words, they adjust the more complex statistical patterns in the model's internal representations to adapt it to the new task, without forgetting what it had learned before.
By doing this, the model is able to quickly learn new visual categories from just a few examples, while still retaining its previous knowledge. This allows the model to continuously expand its capabilities over time, without suffering from catastrophic forgetting.
Technical Explanation
The paper introduces a method called "Calibrating Higher-Order Statistics" (CAHOS) for few-shot class-incremental learning with pre-trained vision transformers.
The key insight is that the higher-order statistics (such as covariance and kurtosis) of the pre-trained model's internal representations capture important information about the visual concepts it has learned. By calibrating these higher-order statistics to adapt to new tasks, the model can quickly learn new classes without forgetting previous knowledge.
The CAHOS method works as follows:
- Extract the higher-order statistics (e.g. covariance, kurtosis) of the pre-trained model's features for the new task's few-shot examples.
- Use these statistics to calibrate the model's feature distributions, aligning them with the new task while preserving the old task knowledge.
- Fine-tune the model on the new task using the calibrated feature representations.
The authors evaluate CAHOS on several few-shot class-incremental learning benchmarks, including Learning Prompt Distribution based Feature Replay for Few-Shot Learning, Simple Semantic-Aided Few-Shot Learning, and Deep Feature Statistics Mapping for Generalized Screen Content Recognition. They show that CAHOS outperforms other state-of-the-art methods for this task.
Critical Analysis
The CAHOS method provides a promising approach to addressing catastrophic forgetting in few-shot class-incremental learning. By leveraging the rich feature representations of pre-trained vision transformers and calibrating their higher-order statistics, the model is able to quickly adapt to new tasks while preserving previous knowledge.
However, the paper does not explore the limitations of this approach. For example, it is unclear how well CAHOS would scale to learning a very large number of new classes over time, or how sensitive it is to the quality and diversity of the pre-trained model.
Additionally, the authors only evaluate CAHOS on a few specific benchmarks. It would be valuable to see how it performs on a wider range of few-shot class-incremental learning tasks, including those with more complex visual concepts or varying degrees of task similarity.
Further research could also investigate ways to make the calibration process more efficient or automated, reducing the need for careful hyperparameter tuning. Exploring connections to other few-shot learning techniques, such as Discriminative Sample-Guided Parameter-Efficient Feature Space or Pre-trained Vision-Language Transformers are Few-Shot Learners, could also yield fruitful insights.
Conclusion
This paper presents a novel approach called CAHOS for improving few-shot class-incremental learning with pre-trained vision transformers. By calibrating the higher-order statistics of the model's internal representations, CAHOS is able to adapt the pre-trained model to new tasks while preserving its previous knowledge.
The results demonstrate the effectiveness of this technique on several few-shot learning benchmarks, suggesting that CAHOS could be a valuable tool for building artificial intelligence systems that can continuously expand their capabilities over time. Further research is needed to explore the broader applicability and limitations of this approach, but it represents an important step forward in addressing the challenge of catastrophic forgetting in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Calibrating Higher-Order Statistics for Few-Shot Class-Incremental Learning with Pre-trained Vision Transformers
Dipam Goswami, Bart{l}omiej Twardowski, Joost van de Weijer
Few-shot class-incremental learning (FSCIL) aims to adapt the model to new classes from very few data (5 samples) without forgetting the previously learned classes. Recent works in many-shot CIL (MSCIL) (using all available training data) exploited pre-trained models to reduce forgetting and achieve better plasticity. In a similar fashion, we use ViT models pre-trained on large-scale datasets for few-shot settings, which face the critical issue of low plasticity. FSCIL methods start with a many-shot first task to learn a very good feature extractor and then move to the few-shot setting from the second task onwards. While the focus of most recent studies is on how to learn the many-shot first task so that the model generalizes to all future few-shot tasks, we explore in this work how to better model the few-shot data using pre-trained models, irrespective of how the first task is trained. Inspired by recent works in MSCIL, we explore how using higher-order feature statistics can influence the classification of few-shot classes. We identify the main challenge of obtaining a good covariance matrix from few-shot data and propose to calibrate the covariance matrix for new classes based on semantic similarity to the many-shot base classes. Using the calibrated feature statistics in combination with existing methods significantly improves few-shot continual classification on several FSCIL benchmarks. Code is available at https://github.com/dipamgoswami/FSCIL-Calibration.
Read more4/11/2024

0
Pre-trained Vision and Language Transformers Are Few-Shot Incremental Learners
Keon-Hee Park, Kyungwoo Song, Gyeong-Moon Park
Few-Shot Class Incremental Learning (FSCIL) is a task that requires a model to learn new classes incrementally without forgetting when only a few samples for each class are given. FSCIL encounters two significant challenges: catastrophic forgetting and overfitting, and these challenges have driven prior studies to primarily rely on shallow models, such as ResNet-18. Even though their limited capacity can mitigate both forgetting and overfitting issues, it leads to inadequate knowledge transfer during few-shot incremental sessions. In this paper, we argue that large models such as vision and language transformers pre-trained on large datasets can be excellent few-shot incremental learners. To this end, we propose a novel FSCIL framework called PriViLege, Pre-trained Vision and Language transformers with prompting functions and knowledge distillation. Our framework effectively addresses the challenges of catastrophic forgetting and overfitting in large models through new pre-trained knowledge tuning (PKT) and two losses: entropy-based divergence loss and semantic knowledge distillation loss. Experimental results show that the proposed PriViLege significantly outperforms the existing state-of-the-art methods with a large margin, e.g., +9.38% in CUB200, +20.58% in CIFAR-100, and +13.36% in miniImageNet. Our implementation code is available at https://github.com/KHU-AGI/PriViLege.
Read more4/3/2024
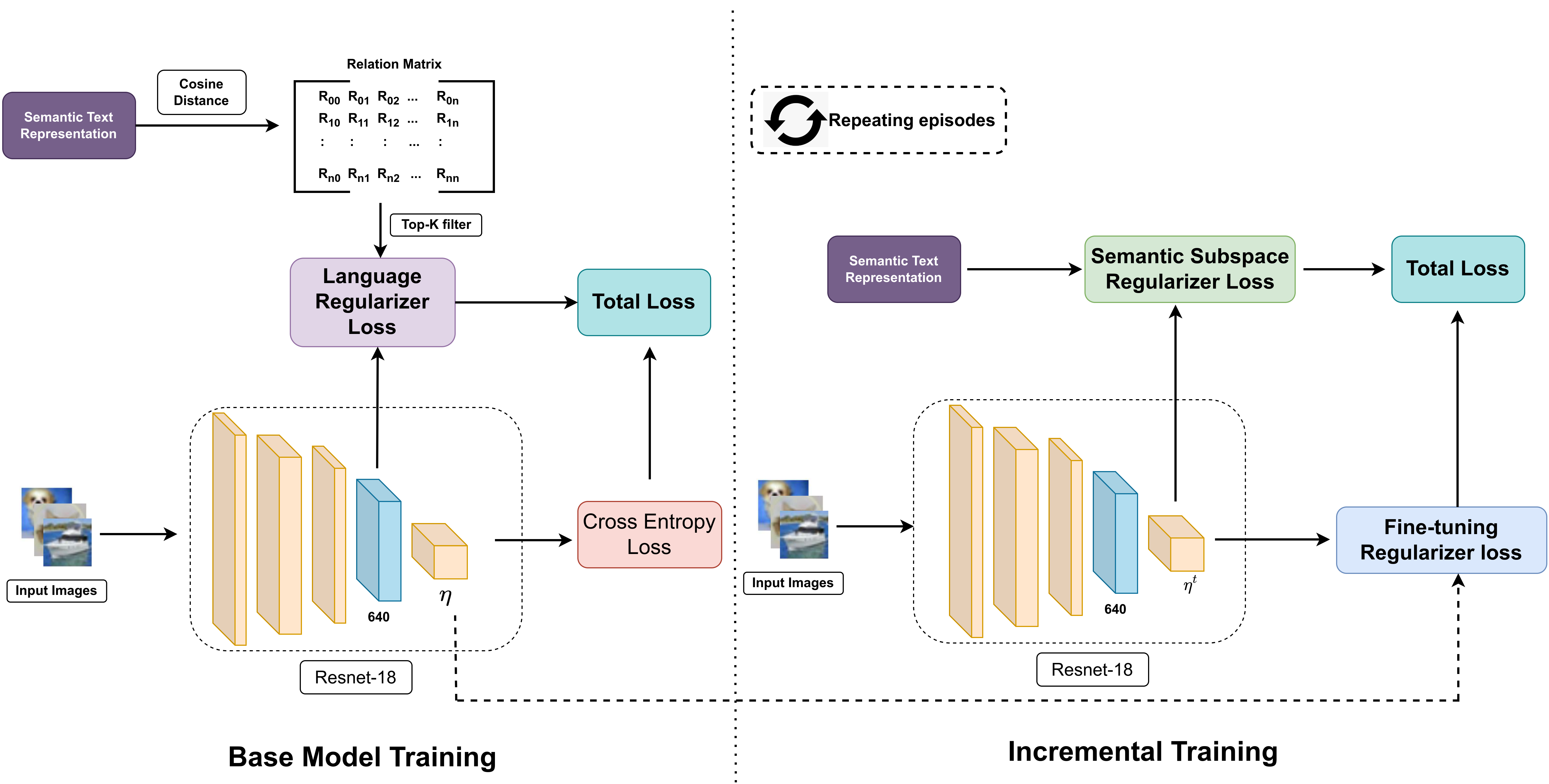
0
Few Shot Class Incremental Learning using Vision-Language models
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
Read more8/16/2024

0
Rethinking Few-shot Class-incremental Learning: Learning from Yourself
Yu-Ming Tang, Yi-Xing Peng, Jingke Meng, Wei-Shi Zheng
Few-shot class-incremental learning (FSCIL) aims to learn sequential classes with limited samples in a few-shot fashion. Inherited from the classical class-incremental learning setting, the popular benchmark of FSCIL uses averaged accuracy (aAcc) and last-task averaged accuracy (lAcc) as the evaluation metrics. However, we reveal that such evaluation metrics may not provide adequate emphasis on the novel class performance, and the continual learning ability of FSCIL methods could be ignored under this benchmark. In this work, as a complement to existing metrics, we offer a new metric called generalized average accuracy (gAcc) which is designed to provide an extra equitable evaluation by incorporating different perspectives of the performance under the guidance of a parameter $alpha$. We also present an overall metric in the form of the area under the curve (AUC) along the $alpha$. Under the guidance of gAcc, we release the potential of intermediate features of the vision transformers to boost the novel-class performance. Taking information from intermediate layers which are less class-specific and more generalizable, we manage to rectify the final features, leading to a more generalizable transformer-based FSCIL framework. Without complex network designs or cumbersome training procedures, our method outperforms existing FSCIL methods at aAcc and gAcc on three datasets. See codes at https://github.com/iSEE-Laboratory/Revisting_FSCIL
Read more7/11/2024