Rethinking Few-shot Class-incremental Learning: Learning from Yourself

0

Sign in to get full access
Overview
- This paper proposes a new approach to few-shot class-incremental learning, a challenging problem in machine learning where a model must learn new classes with only a few training examples while avoiding catastrophic forgetting of previously learned classes.
- The key idea is to leverage self-supervised learning to enable the model to learn from its own experience, without relying on external data or complex memory replay mechanisms.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing significant improvements over existing few-shot class-incremental learning methods.
Plain English Explanation
In machine learning, there is a problem called few-shot class-incremental learning. This means that a model needs to learn new classes or categories with only a small number of training examples, without forgetting what it has learned before. This is a challenging task because models can often "forget" previous knowledge when learning new information.
The authors of this paper have developed a new approach to solve this problem. Instead of relying on external data or complex memory replay techniques, their method allows the model to learn from its own experience. The key idea is to use self-supervised learning, which means the model can learn useful representations from the data itself, without needing additional labels or information.
By using this self-supervised approach, the model can continuously learn new classes while maintaining its knowledge of previous ones. The authors show that their method outperforms existing few-shot class-incremental learning techniques on several standard benchmarks.
This research is important because it could lead to more flexible and robust machine learning models that can adapt to new information over time, without forgetting what they have already learned. This could be particularly useful in real-world applications where the data and requirements are constantly changing.
Technical Explanation
The paper presents a new framework for few-shot class-incremental learning, which addresses the challenge of learning new classes with limited data while avoiding catastrophic forgetting of previously learned classes.
The key idea is to leverage self-supervised learning to enable the model to learn from its own experience, rather than relying on external data or complex memory replay mechanisms used in prior work.
Specifically, the authors propose a method called Learning from Yourself (LFY), which consists of three main components:
-
Self-supervised Pretraining: The model is first pretrained on a large corpus of unlabeled data using self-supervised learning, which allows it to learn useful representations without requiring manual labeling.
-
Class-incremental Fine-tuning: When presented with new classes, the model is fine-tuned on the few-shot training examples for those classes. Crucially, the model also learns from its own predictions on unlabeled data, using a self-supervised consistency loss to help it retain knowledge of previous classes.
-
Distillation-based Classifier Head: The authors use a distillation-based approach to update the classifier head, which helps the model preserve its performance on previous classes while learning the new ones.
The authors evaluate their method on several benchmark datasets for few-shot class-incremental learning and calibrating higher-order statistics in few-shot learning. The results demonstrate significant improvements over existing state-of-the-art approaches, highlighting the effectiveness of the proposed self-supervised learning strategy.
Critical Analysis
The paper presents a compelling approach to the challenging problem of few-shot class-incremental learning. The key strength of the proposed method is its ability to leverage self-supervised learning to enable the model to continuously acquire new knowledge without forgetting previous lessons.
One potential limitation of the work is that it assumes the availability of a large corpus of unlabeled data for self-supervised pretraining. In some real-world scenarios, such a large dataset may not be readily available, which could limit the applicability of the method.
Additionally, the authors do not provide a detailed analysis of the computational and memory requirements of their approach, which could be an important consideration for certain applications. Further research may be needed to understand the scalability and efficiency of the proposed framework.
Another area for potential improvement is the evaluation of the method's performance on more diverse and realistic datasets, which could uncover additional challenges or edge cases not captured by the current benchmarks.
Despite these minor caveats, the paper represents a significant contribution to the field of few-shot class-incremental learning, and the authors' innovative use of self-supervised learning is a promising direction for future research in this area.
Conclusion
This paper introduces a novel approach to the problem of few-shot class-incremental learning, a challenging task in machine learning where models must learn new classes with limited data while avoiding catastrophic forgetting of previously learned information.
The key innovation of the proposed method is its use of self-supervised learning, which allows the model to continuously learn from its own experience without relying on external data or complex memory replay techniques. The authors demonstrate the effectiveness of their approach on several benchmark datasets, showcasing significant improvements over existing state-of-the-art methods.
This research has important implications for the development of more flexible and adaptable machine learning models, which could be particularly valuable in real-world applications where the data and requirements are constantly evolving. By leveraging self-supervised learning, the authors have opened up new avenues for addressing the critical challenge of catastrophic forgetting in continuous learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking Few-shot Class-incremental Learning: Learning from Yourself
Yu-Ming Tang, Yi-Xing Peng, Jingke Meng, Wei-Shi Zheng
Few-shot class-incremental learning (FSCIL) aims to learn sequential classes with limited samples in a few-shot fashion. Inherited from the classical class-incremental learning setting, the popular benchmark of FSCIL uses averaged accuracy (aAcc) and last-task averaged accuracy (lAcc) as the evaluation metrics. However, we reveal that such evaluation metrics may not provide adequate emphasis on the novel class performance, and the continual learning ability of FSCIL methods could be ignored under this benchmark. In this work, as a complement to existing metrics, we offer a new metric called generalized average accuracy (gAcc) which is designed to provide an extra equitable evaluation by incorporating different perspectives of the performance under the guidance of a parameter $alpha$. We also present an overall metric in the form of the area under the curve (AUC) along the $alpha$. Under the guidance of gAcc, we release the potential of intermediate features of the vision transformers to boost the novel-class performance. Taking information from intermediate layers which are less class-specific and more generalizable, we manage to rectify the final features, leading to a more generalizable transformer-based FSCIL framework. Without complex network designs or cumbersome training procedures, our method outperforms existing FSCIL methods at aAcc and gAcc on three datasets. See codes at https://github.com/iSEE-Laboratory/Revisting_FSCIL
Read more7/11/2024

0
A Bag of Tricks for Few-Shot Class-Incremental Learning
Shuvendu Roy, Chunjong Park, Aldi Fahrezi, Ali Etemad
We present a bag of tricks framework for few-shot class-incremental learning (FSCIL), which is a challenging form of continual learning that involves continuous adaptation to new tasks with limited samples. FSCIL requires both stability and adaptability, i.e., preserving proficiency in previously learned tasks while learning new ones. Our proposed bag of tricks brings together six key and highly influential techniques that improve stability, adaptability, and overall performance under a unified framework for FSCIL. We organize these tricks into three categories: stability tricks, adaptability tricks, and training tricks. Stability tricks aim to mitigate the forgetting of previously learned classes by enhancing the separation between the embeddings of learned classes and minimizing interference when learning new ones. On the other hand, adaptability tricks focus on the effective learning of new classes. Finally, training tricks improve the overall performance without compromising stability or adaptability. We perform extensive experiments on three benchmark datasets, CIFAR-100, CUB-200, and miniIMageNet, to evaluate the impact of our proposed framework. Our detailed analysis shows that our approach substantially improves both stability and adaptability, establishing a new state-of-the-art by outperforming prior works in the area. We believe our method provides a go-to solution and establishes a robust baseline for future research in this area.
Read more9/10/2024

0
Calibrating Higher-Order Statistics for Few-Shot Class-Incremental Learning with Pre-trained Vision Transformers
Dipam Goswami, Bart{l}omiej Twardowski, Joost van de Weijer
Few-shot class-incremental learning (FSCIL) aims to adapt the model to new classes from very few data (5 samples) without forgetting the previously learned classes. Recent works in many-shot CIL (MSCIL) (using all available training data) exploited pre-trained models to reduce forgetting and achieve better plasticity. In a similar fashion, we use ViT models pre-trained on large-scale datasets for few-shot settings, which face the critical issue of low plasticity. FSCIL methods start with a many-shot first task to learn a very good feature extractor and then move to the few-shot setting from the second task onwards. While the focus of most recent studies is on how to learn the many-shot first task so that the model generalizes to all future few-shot tasks, we explore in this work how to better model the few-shot data using pre-trained models, irrespective of how the first task is trained. Inspired by recent works in MSCIL, we explore how using higher-order feature statistics can influence the classification of few-shot classes. We identify the main challenge of obtaining a good covariance matrix from few-shot data and propose to calibrate the covariance matrix for new classes based on semantic similarity to the many-shot base classes. Using the calibrated feature statistics in combination with existing methods significantly improves few-shot continual classification on several FSCIL benchmarks. Code is available at https://github.com/dipamgoswami/FSCIL-Calibration.
Read more4/11/2024
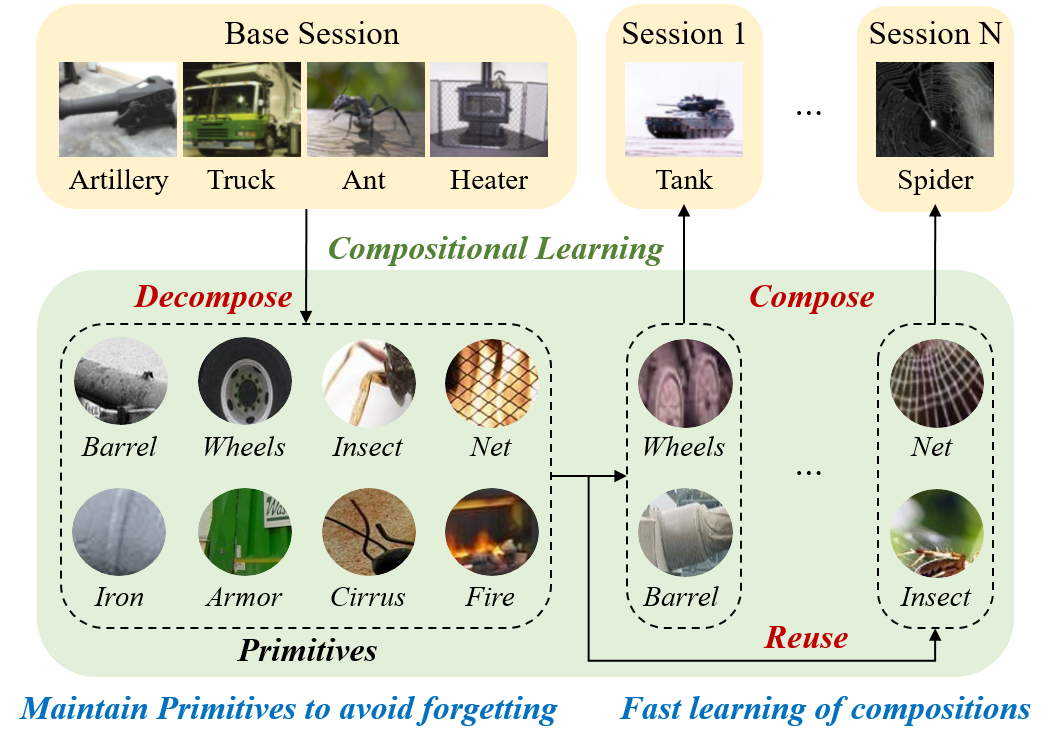
0
Compositional Few-Shot Class-Incremental Learning
Yixiong Zou, Shanghang Zhang, Haichen Zhou, Yuhua Li, Ruixuan Li
Few-shot class-incremental learning (FSCIL) is proposed to continually learn from novel classes with only a few samples after the (pre-)training on base classes with sufficient data. However, this remains a challenge. In contrast, humans can easily recognize novel classes with a few samples. Cognitive science demonstrates that an important component of such human capability is compositional learning. This involves identifying visual primitives from learned knowledge and then composing new concepts using these transferred primitives, making incremental learning both effective and interpretable. To imitate human compositional learning, we propose a cognitive-inspired method for the FSCIL task. We define and build a compositional model based on set similarities, and then equip it with a primitive composition module and a primitive reuse module. In the primitive composition module, we propose to utilize the Centered Kernel Alignment (CKA) similarity to approximate the similarity between primitive sets, allowing the training and evaluation based on primitive compositions. In the primitive reuse module, we enhance primitive reusability by classifying inputs based on primitives replaced with the closest primitives from other classes. Experiments on three datasets validate our method, showing it outperforms current state-of-the-art methods with improved interpretability. Our code is available at https://github.com/Zoilsen/Comp-FSCIL.
Read more5/28/2024