Calibrating the Predictions for Top-N Recommendations

0
Sign in to get full access
Overview
- The paper explores techniques for calibrating the predictions of top-N recommendation systems to improve their reliability and accuracy.
- It focuses on reducing the expected calibration error and prediction bias in these systems.
- The authors propose novel methods and evaluate their performance on real-world datasets.
Plain English Explanation
Recommendation systems are commonly used to suggest products, content, or services that users might like based on their past preferences. However, these systems can sometimes make inaccurate or unreliable predictions, leading to poor user experiences.
This paper tackles the challenge of calibrating the predictions made by top-N recommendation systems. Calibration refers to ensuring that the system's confidence in its predictions matches the actual probability of those predictions being correct. For example, if the system is 80% confident that a user will like a particular item, then 80% of the time, the user should actually like that item.
The researchers explore ways to reduce two key metrics: expected calibration error and prediction bias. Expected calibration error measures how much the system's confidence in its predictions differs from the actual likelihood of those predictions being correct. Prediction bias refers to the system consistently over- or under-estimating the likelihood of certain predictions.
By addressing these issues, the authors aim to make top-N recommendation systems more reliable and trustworthy for users.
Technical Explanation
The paper proposes several techniques for calibrating the predictions of top-N recommendation systems:
-
Calibration-aware Loss Functions: The authors develop new loss functions that explicitly incorporate calibration-related objectives, such as minimizing expected calibration error, during the model training process.
-
Calibration-aware Regularization: They also introduce calibration-aware regularization terms that can be added to existing loss functions to encourage better calibration of the model's predictions.
-
Adaptive Calibration Layers: The researchers design specialized neural network layers that can be inserted into recommendation models to dynamically calibrate the output probabilities during inference.
The performance of these techniques is evaluated on real-world datasets, and the results show significant improvements in reducing expected calibration error and prediction bias compared to standard recommendation models.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of the calibration problem in top-N recommendation systems. The proposed methods are well-designed and demonstrate clear improvements over existing approaches.
However, the paper does not address the potential trade-offs between calibration and other important metrics, such as recommendation accuracy or diversity. It's possible that optimizing for calibration could negatively impact these other aspects of system performance.
Additionally, the paper focuses on offline evaluation using held-out test data. More research may be needed to understand how these calibration techniques perform in real-world, online settings with dynamic user preferences and interactions.
Conclusion
This paper makes a valuable contribution to the field of recommendation systems by introducing novel techniques for improving the calibration of top-N predictions. By reducing expected calibration error and prediction bias, the authors enhance the reliability and trustworthiness of these systems, which can lead to better user experiences and more informed decision-making.
The insights and methods presented in this work have the potential to be widely applicable across various recommendation domains, from e-commerce to content discovery. Further research and development in this area could greatly benefit both users and providers of recommendation services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Calibrating the Predictions for Top-N Recommendations
Masahiro Sato
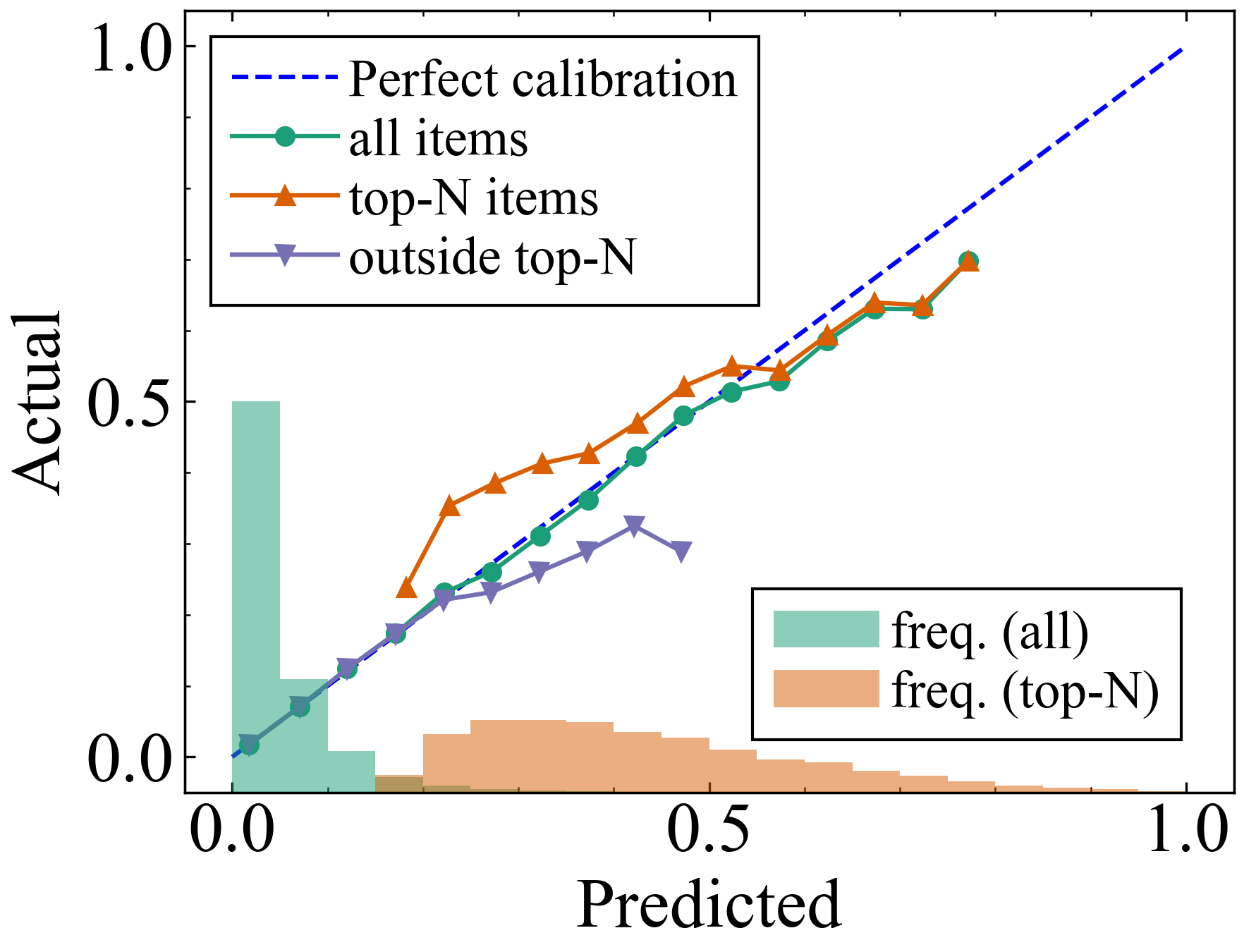
Well-calibrated predictions of user preferences are essential for many applications. Since recommender systems typically select the top-N items for users, calibration for those top-N items, rather than for all items, is important. We show that previous calibration methods result in miscalibrated predictions for the top-N items, despite their excellent calibration performance when evaluated on all items. In this work, we address the miscalibration in the top-N recommended items. We first define evaluation metrics for this objective and then propose a generic method to optimize calibration models focusing on the top-N items. It groups the top-N items by their ranks and optimizes distinct calibration models for each group with rank-dependent training weights. We verify the effectiveness of the proposed method for both explicit and implicit feedback datasets, using diverse classes of recommender models.
Read more8/22/2024

0
Beyond Static Calibration: The Impact of User Preference Dynamics on Calibrated Recommendation
Kun Lin, Masoud Mansoury, Farzad Eskandanian, Milad Sabouri, Bamshad Mobasher
Calibration in recommender systems is an important performance criterion that ensures consistency between the distribution of user preference categories and that of recommendations generated by the system. Standard methods for mitigating miscalibration typically assume that user preference profiles are static, and they measure calibration relative to the full history of user's interactions, including possibly outdated and stale preference categories. We conjecture that this approach can lead to recommendations that, while appearing calibrated, in fact, distort users' true preferences. In this paper, we conduct a preliminary investigation of recommendation calibration at a more granular level, taking into account evolving user preferences. By analyzing differently sized training time windows from the most recent interactions to the oldest, we identify the most relevant segment of user's preferences that optimizes the calibration metric. We perform an exploratory analysis with datasets from different domains with distinctive user-interaction characteristics. We demonstrate how the evolving nature of user preferences affects recommendation calibration, and how this effect is manifested differently depending on the characteristics of the data in a given domain. Datasets, codes, and more detailed experimental results are available at: https://github.com/nicolelin13/DynamicCalibrationUMAP.
Read more5/17/2024

0
Towards Fair and Rigorous Evaluations: Hyperparameter Optimization for Top-N Recommendation Task with Implicit Feedback
Hui Fang, Xu Feng, Lu Qin, Zhu Sun
The widespread use of the internet has led to an overwhelming amount of data, which has resulted in the problem of information overload. Recommender systems have emerged as a solution to this problem by providing personalized recommendations to users based on their preferences and historical data. However, as recommendation models become increasingly complex, finding the best hyperparameter combination for different models has become a challenge. The high-dimensional hyperparameter search space poses numerous challenges for researchers, and failure to disclose hyperparameter settings may impede the reproducibility of research results. In this paper, we investigate the Top-N implicit recommendation problem and focus on optimizing the benchmark recommendation algorithm commonly used in comparative experiments using hyperparameter optimization algorithms. We propose a research methodology that follows the principles of a fair comparison, employing seven types of hyperparameter search algorithms to fine-tune six common recommendation algorithms on three datasets. We have identified the most suitable hyperparameter search algorithms for various recommendation algorithms on different types of datasets as a reference for later study. This study contributes to algorithmic research in recommender systems based on hyperparameter optimization, providing a fair basis for comparison.
Read more8/15/2024

0
A Self-boosted Framework for Calibrated Ranking
Shunyu Zhang, Hu Liu, Wentian Bao, Enyun Yu, Yang Song
Scale-calibrated ranking systems are ubiquitous in real-world applications nowadays, which pursue accurate ranking quality and calibrated probabilistic predictions simultaneously. For instance, in the advertising ranking system, the predicted click-through rate (CTR) is utilized for ranking and required to be calibrated for the downstream cost-per-click ads bidding. Recently, multi-objective based methods have been wildly adopted as a standard approach for Calibrated Ranking, which incorporates the combination of two loss functions: a pointwise loss that focuses on calibrated absolute values and a ranking loss that emphasizes relative orderings. However, when applied to industrial online applications, existing multi-objective CR approaches still suffer from two crucial limitations. First, previous methods need to aggregate the full candidate list within a single mini-batch to compute the ranking loss. Such aggregation strategy violates extensive data shuffling which has long been proven beneficial for preventing overfitting, and thus degrades the training effectiveness. Second, existing multi-objective methods apply the two inherently conflicting loss functions on a single probabilistic prediction, which results in a sub-optimal trade-off between calibration and ranking. To tackle the two limitations, we propose a Self-Boosted framework for Calibrated Ranking (SBCR).
Read more6/13/2024