A Self-boosted Framework for Calibrated Ranking

0

Sign in to get full access
Overview
- This paper proposes a self-boosted framework for calibrated ranking, which aims to improve the reliability and fairness of search ranking systems.
- The researchers develop a novel approach that learns to calibrate the ranking model's output probabilities, ensuring they accurately reflect the true relevance of search results.
- The framework incorporates a feedback loop that continuously updates the calibration based on user interactions, allowing the system to adapt and improve over time.
Plain English Explanation
Search engines and online platforms often use complex machine learning models to rank and display content for users. However, these models can sometimes be miscalibrated, meaning their output probabilities don't accurately reflect the true relevance of the search results. This can lead to unreliable or unfair rankings, where highly relevant content is not shown at the top, or less relevant content is given a high ranking.
The researchers in this paper have developed a new approach to address this issue. Their self-boosted framework for calibrated ranking learns to calibrate the ranking model's output probabilities, ensuring they better match the true relevance of the search results. This is achieved through a feedback loop that continuously updates the calibration based on user interactions, allowing the system to adapt and improve over time.
By improving the calibration of the ranking model, the researchers aim to make search and recommendation systems more reliable and fair, ensuring that the most relevant content is consistently displayed at the top of the results. This could have significant implications for optimizing calibration by gaining aware prediction correctness, calibrated regression against adversary without regret, posterior probability matters doubly adaptive calibration neural, confidence-aware multi-field model calibration, and adaptively learning to select rank online platforms.
Technical Explanation
The researchers propose a self-boosted framework for calibrated ranking that aims to improve the reliability and fairness of search ranking systems. The key components of their approach include:
-
Calibration Model: The framework includes a separate calibration model that learns to adjust the output probabilities of the ranking model, ensuring they accurately reflect the true relevance of the search results.
-
Feedback Loop: The calibration model is updated based on user interactions, such as clicks and dwell time. This feedback loop allows the system to continuously adapt and improve the calibration over time.
-
Multi-task Learning: The researchers use a multi-task learning approach, where the ranking model and calibration model are trained jointly to optimize both relevance and calibration.
The researchers evaluate their framework on several benchmark datasets and find that it outperforms standard ranking models in terms of calibration metrics, while maintaining comparable or better ranking performance. The self-boosted approach proves effective in improving the reliability and fairness of the search ranking system.
Critical Analysis
The researchers acknowledge several limitations and areas for future research in their paper. One key limitation is the reliance on user interaction data, which may not always be available or representative of the true relevance of the search results. Additionally, the researchers note that their framework assumes the availability of a well-calibrated initial ranking model, which may not always be the case in practice.
While the proposed framework represents a significant step forward in improving search ranking systems, there are still open challenges and potential areas for further exploration. For example, the researchers do not address how the framework would handle dynamic changes in user preferences or search intent over time, or how it could be extended to other types of recommendation systems beyond search.
Furthermore, the paper does not delve into the potential ethical and societal implications of a more reliable and fair search ranking system. It would be important to consider how such a system could impact marginalized communities, information access, and the overall dynamics of online platforms.
Conclusion
The self-boosted framework for calibrated ranking proposed in this paper represents a significant advancement in improving the reliability and fairness of search ranking systems. By learning to calibrate the output probabilities of the ranking model, the framework ensures that the most relevant content is consistently displayed at the top of the search results.
The incorporation of a feedback loop that continuously updates the calibration based on user interactions is a key innovation that allows the system to adapt and improve over time. This approach could have far-reaching implications for a wide range of optimizing calibration by gaining aware prediction correctness, calibrated regression against adversary without regret, posterior probability matters doubly adaptive calibration neural, confidence-aware multi-field model calibration, and adaptively learning to select rank online platforms.
As the researchers continue to refine and expand this framework, it will be crucial to address the limitations and potential ethical concerns identified in the paper. Ultimately, the successful implementation of this approach could lead to more reliable, fair, and trustworthy search and recommendation systems that better serve the needs of users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Self-boosted Framework for Calibrated Ranking
Shunyu Zhang, Hu Liu, Wentian Bao, Enyun Yu, Yang Song
Scale-calibrated ranking systems are ubiquitous in real-world applications nowadays, which pursue accurate ranking quality and calibrated probabilistic predictions simultaneously. For instance, in the advertising ranking system, the predicted click-through rate (CTR) is utilized for ranking and required to be calibrated for the downstream cost-per-click ads bidding. Recently, multi-objective based methods have been wildly adopted as a standard approach for Calibrated Ranking, which incorporates the combination of two loss functions: a pointwise loss that focuses on calibrated absolute values and a ranking loss that emphasizes relative orderings. However, when applied to industrial online applications, existing multi-objective CR approaches still suffer from two crucial limitations. First, previous methods need to aggregate the full candidate list within a single mini-batch to compute the ranking loss. Such aggregation strategy violates extensive data shuffling which has long been proven beneficial for preventing overfitting, and thus degrades the training effectiveness. Second, existing multi-objective methods apply the two inherently conflicting loss functions on a single probabilistic prediction, which results in a sub-optimal trade-off between calibration and ranking. To tackle the two limitations, we propose a Self-Boosted framework for Calibrated Ranking (SBCR).
Read more6/13/2024
0
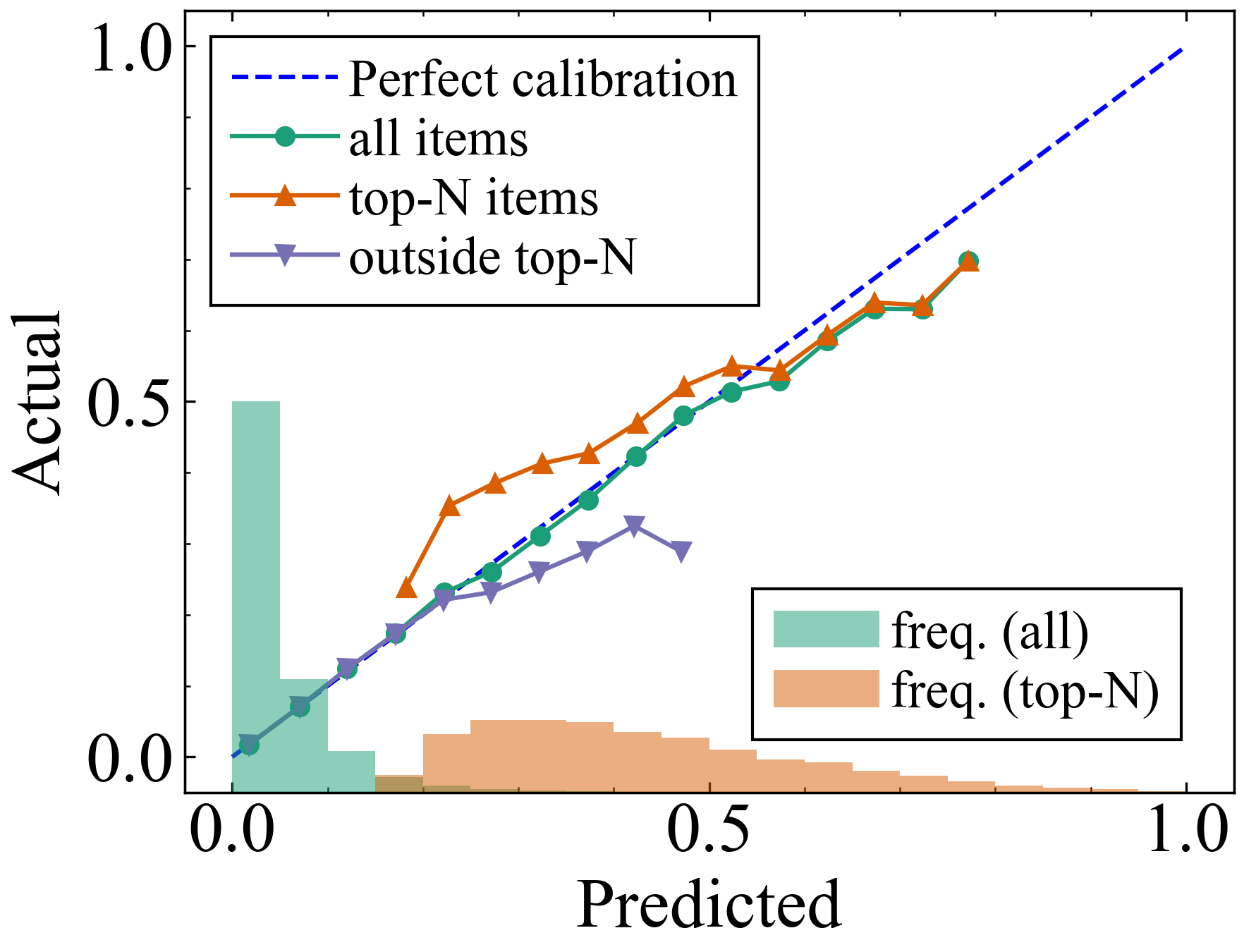
Calibrating the Predictions for Top-N Recommendations
Masahiro Sato
Well-calibrated predictions of user preferences are essential for many applications. Since recommender systems typically select the top-N items for users, calibration for those top-N items, rather than for all items, is important. We show that previous calibration methods result in miscalibrated predictions for the top-N items, despite their excellent calibration performance when evaluated on all items. In this work, we address the miscalibration in the top-N recommended items. We first define evaluation metrics for this objective and then propose a generic method to optimize calibration models focusing on the top-N items. It groups the top-N items by their ranks and optimizes distinct calibration models for each group with rank-dependent training weights. We verify the effectiveness of the proposed method for both explicit and implicit feedback datasets, using diverse classes of recommender models.
Read more8/22/2024
0
Optimizing Calibration by Gaining Aware of Prediction Correctness
Yuchi Liu, Lei Wang, Yuli Zou, James Zou, Liang Zheng
Model calibration aims to align confidence with prediction correctness. The Cross-Entropy (CE) loss is widely used for calibrator training, which enforces the model to increase confidence on the ground truth class. However, we find the CE loss has intrinsic limitations. For example, for a narrow misclassification, a calibrator trained by the CE loss often produces high confidence on the wrongly predicted class (e.g., a test sample is wrongly classified and its softmax score on the ground truth class is around 0.4), which is undesirable. In this paper, we propose a new post-hoc calibration objective derived from the aim of calibration. Intuitively, the proposed objective function asks that the calibrator decrease model confidence on wrongly predicted samples and increase confidence on correctly predicted samples. Because a sample itself has insufficient ability to indicate correctness, we use its transformed versions (e.g., rotated, greyscaled and color-jittered) during calibrator training. Trained on an in-distribution validation set and tested with isolated, individual test samples, our method achieves competitive calibration performance on both in-distribution and out-of-distribution test sets compared with the state of the art. Further, our analysis points out the difference between our method and commonly used objectives such as CE loss and mean square error loss, where the latters sometimes deviates from the calibration aim.
Read more4/26/2024

0
Building a Scalable, Effective, and Steerable Search and Ranking Platform
Marjan Celikik, Jacek Wasilewski, Ana Peleteiro Ramallo, Alexey Kurennoy, Evgeny Labzin, Danilo Ascione, Tural Gurbanov, G'eraud Le Falher, Andrii Dzhoha, Ian Harris
Modern e-commerce platforms offer vast product selections, making it difficult for customers to find items that they like and that are relevant to their current session intent. This is why it is key for e-commerce platforms to have near real-time scalable and adaptable personalized ranking and search systems. While numerous methods exist in the scientific literature for building such systems, many are unsuitable for large-scale industrial use due to complexity and performance limitations. Consequently, industrial ranking systems often resort to computationally efficient yet simplistic retrieval or candidate generation approaches, which overlook near real-time and heterogeneous customer signals, which results in a less personalized and relevant experience. Moreover, related customer experiences are served by completely different systems, which increases complexity, maintenance, and inconsistent experiences. In this paper, we present a personalized, adaptable near real-time ranking platform that is reusable across various use cases, such as browsing and search, and that is able to cater to millions of items and customers under heavy load (thousands of requests per second). We employ transformer-based models through different ranking layers which can learn complex behavior patterns directly from customer action sequences while being able to incorporate temporal (e.g. in-session) and contextual information. We validate our system through a series of comprehensive offline and online real-world experiments at a large online e-commerce platform, and we demonstrate its superiority when compared to existing systems, both in terms of customer experience as well as in net revenue. Finally, we share the lessons learned from building a comprehensive, modern ranking platform for use in a large-scale e-commerce environment.
Read more9/5/2024