CamemBERT-bio: Leveraging Continual Pre-training for Cost-Effective Models on French Biomedical Data
2306.15550
0
0
📊
Abstract
Clinical data in hospitals are increasingly accessible for research through clinical data warehouses. However these documents are unstructured and it is therefore necessary to extract information from medical reports to conduct clinical studies. Transfer learning with BERT-like models such as CamemBERT has allowed major advances for French, especially for named entity recognition. However, these models are trained for plain language and are less efficient on biomedical data. Addressing this gap, we introduce CamemBERT-bio, a dedicated French biomedical model derived from a new public French biomedical dataset. Through continual pre-training of the original CamemBERT, CamemBERT-bio achieves an improvement of 2.54 points of F1-score on average across various biomedical named entity recognition tasks, reinforcing the potential of continual pre-training as an equally proficient yet less computationally intensive alternative to training from scratch. Additionally, we highlight the importance of using a standard evaluation protocol that provides a clear view of the current state-of-the-art for French biomedical models.
Create account to get full access
Overview
- This paper introduces CamemBERT-bio, a French language model tailored for the healthcare domain.
- CamemBERT-bio is an extension of the original CamemBERT model, which was developed for general French language tasks.
- The researchers aimed to create a model that performs better on biomedical and clinical text data compared to the original CamemBERT.
Plain English Explanation
Language models are artificial intelligence systems that can understand and generate human language. CamemBERT is a French language model that was developed for general tasks like translation and text summarization. However, when used on specialized medical and clinical texts, the original CamemBERT model may not perform as well.
The researchers in this paper created a new version of CamemBERT called CamemBERT-bio, which is tailored for healthcare-related language. They "fine-tuned" the original model by training it on a large corpus of French biomedical and clinical documents. This allows CamemBERT-bio to better understand the specialized terminology, sentence structures, and context found in medical texts.
The end result is a language model that can more accurately process and understand French medical records, research papers, and other clinical documents. This could be valuable for tasks like automating medical note-taking, extracting insights from patient data, or developing French-language clinical decision support systems.
Technical Explanation
The researchers started with the pre-trained CamemBERT model, which was trained on a large corpus of general French text. They then further trained this model on a specialized dataset of over 400,000 French biomedical articles and clinical notes. This "fine-tuning" process allows CamemBERT-bio to learn the unique vocabulary, grammar, and contextual patterns found in healthcare-related language.
To evaluate the performance of CamemBERT-bio, the researchers conducted experiments on several French biomedical and clinical text classification tasks. These included classifying medical abstracts by topic, detecting named entities (e.g. diseases, drugs, symptoms) in clinical notes, and classifying whether clinical notes described a diagnosis or treatment. CamemBERT-bio was compared against the original CamemBERT as well as other French language models.
The results showed that CamemBERT-bio outperformed the baseline models across the various evaluation tasks. It demonstrated stronger performance on biomedical text classification, named entity recognition, and clinical text analysis. This suggests the fine-tuning process was successful in imbuing CamemBERT-bio with specialized knowledge and capabilities for healthcare-related French language understanding.
Critical Analysis
The paper provides a robust evaluation of CamemBERT-bio, using well-established benchmarks and comparisons to state-of-the-art models. However, the researchers acknowledge that their dataset was limited to French sources, and further validation on a more diverse set of clinical texts would be valuable.
Additionally, the paper does not delve into the specific types of errors or failure cases for CamemBERT-bio. Understanding the model's limitations would help guide future research and practical applications. It would also be interesting to see how CamemBERT-bio performs on more open-ended clinical language tasks, beyond just classification.
Overall, this work represents an important step in developing French-language AI tools tailored for the healthcare domain. Continued research and refinement of CamemBERT-bio could lead to meaningful improvements in areas like medical documentation, patient data analysis, and French-language clinical decision support.
Conclusion
The CamemBERT-bio model introduced in this paper demonstrates the value of fine-tuning general language models to specialized domains. By training the original CamemBERT on a large corpus of French biomedical and clinical texts, the researchers were able to create a more capable model for understanding healthcare-related language.
The superior performance of CamemBERT-bio on key evaluation tasks suggests it could be a valuable tool for automating the analysis and processing of French medical records, research papers, and other clinical documents. This has the potential to improve clinical workflows, accelerate medical research, and enhance French-language healthcare applications powered by artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Benchmark Evaluation of Clinical Named Entity Recognition in French
Nesrine Bannour (STL), Christophe Servan (STL), Aur'elie N'ev'eol (STL), Xavier Tannier (LIMICS)
0
0
Background: Transformer-based language models have shown strong performance on many Natural LanguageProcessing (NLP) tasks. Masked Language Models (MLMs) attract sustained interest because they can be adaptedto different languages and sub-domains through training or fine-tuning on specific corpora while remaining lighterthan modern Large Language Models (LLMs). Recently, several MLMs have been released for the biomedicaldomain in French, and experiments suggest that they outperform standard French counterparts. However, nosystematic evaluation comparing all models on the same corpora is available. Objective: This paper presentsan evaluation of masked language models for biomedical French on the task of clinical named entity recognition.Material and methods: We evaluate biomedical models CamemBERT-bio and DrBERT and compare them tostandard French models CamemBERT, FlauBERT and FrALBERT as well as multilingual mBERT using three publicallyavailable corpora for clinical named entity recognition in French. The evaluation set-up relies on gold-standardcorpora as released by the corpus developers. Results: Results suggest that CamemBERT-bio outperformsDrBERT consistently while FlauBERT offers competitive performance and FrAlBERT achieves the lowest carbonfootprint. Conclusion: This is the first benchmark evaluation of biomedical masked language models for Frenchclinical entity recognition that compares model performance consistently on nested entity recognition using metricscovering performance and environmental impact.
4/1/2024
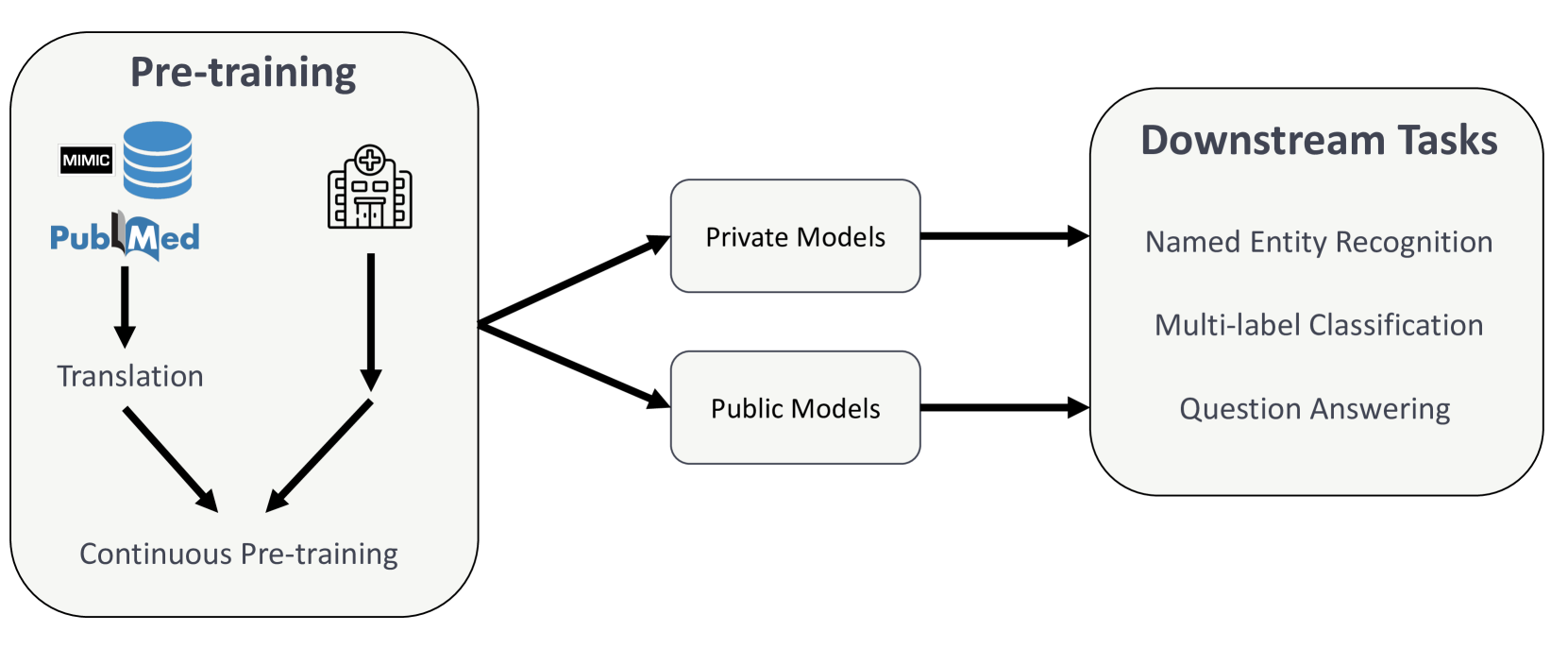
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
0
0
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
5/9/2024
🚀
Improving Transformer Performance for French Clinical Notes Classification Using Mixture of Experts on a Limited Dataset
Thanh-Dung Le, Philippe Jouvet, Rita Noumeir
0
0
Transformer-based models have shown outstanding results in natural language processing but face challenges in applications like classifying small-scale clinical texts, especially with constrained computational resources. This study presents a customized Mixture of Expert (MoE) Transformer models for classifying small-scale French clinical texts at CHU Sainte-Justine Hospital. The MoE-Transformer addresses the dual challenges of effective training with limited data and low-resource computation suitable for in-house hospital use. Despite the success of biomedical pre-trained models such as CamemBERT-bio, DrBERT, and AliBERT, their high computational demands make them impractical for many clinical settings. Our MoE-Transformer model not only outperforms DistillBERT, CamemBERT, FlauBERT, and Transformer models on the same dataset but also achieves impressive results: an accuracy of 87%, precision of 87%, recall of 85%, and F1-score of 86%. While the MoE-Transformer does not surpass the performance of biomedical pre-trained BERT models, it can be trained at least 190 times faster, offering a viable alternative for settings with limited data and computational resources. Although the MoE-Transformer addresses challenges of generalization gaps and sharp minima, demonstrating some limitations for efficient and accurate clinical text classification, this model still represents a significant advancement in the field. It is particularly valuable for classifying small French clinical narratives within the privacy and constraints of hospital-based computational resources.
5/28/2024

Bag of Lies: Robustness in Continuous Pre-training BERT
Ine Gevers, Walter Daelemans
0
0
This study aims to acquire more insights into the continuous pre-training phase of BERT regarding entity knowledge, using the COVID-19 pandemic as a case study. Since the pandemic emerged after the last update of BERT's pre-training data, the model has little to no entity knowledge about COVID-19. Using continuous pre-training, we control what entity knowledge is available to the model. We compare the baseline BERT model with the further pre-trained variants on the fact-checking benchmark Check-COVID. To test the robustness of continuous pre-training, we experiment with several adversarial methods to manipulate the input data, such as training on misinformation and shuffling the word order until the input becomes nonsensical. Surprisingly, our findings reveal that these methods do not degrade, and sometimes even improve, the model's downstream performance. This suggests that continuous pre-training of BERT is robust against misinformation. Furthermore, we are releasing a new dataset, consisting of original texts from academic publications in the LitCovid repository and their AI-generated false counterparts.
6/17/2024