Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
2406.13632
0
0
Abstract
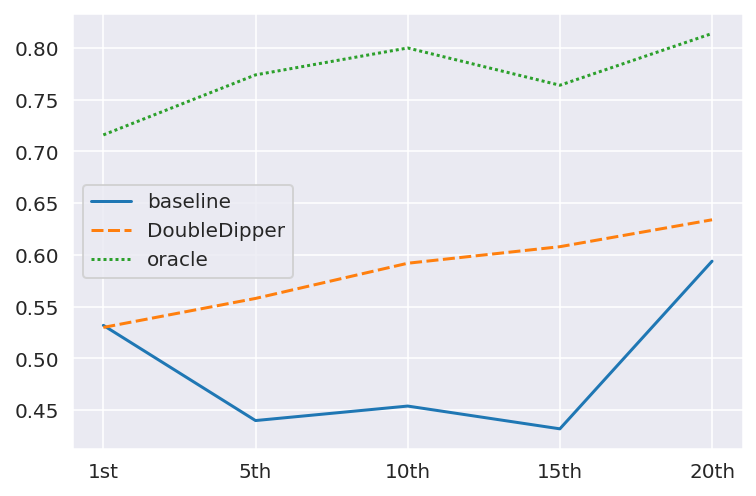
Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements (+23% on average across models) on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
Create account to get full access
Overview
- This paper investigates whether few-shot learning can work effectively in the context of long passages of text, rather than just short prompts.
- The researchers propose a method called "Context Recycling" which aims to leverage the existing context in a passage to generate demonstrations that can be used for few-shot learning.
- The paper evaluates this approach on various language tasks and finds that it can improve performance compared to standard few-shot methods, especially for long-context settings.
Plain English Explanation
In this paper, the researchers are exploring whether few-shot learning can work well when dealing with long passages of text, rather than just short prompts. Typically, few-shot learning is used with small amounts of training data, but the researchers wanted to see if it could be effective even when the context is more extensive.
To do this, they developed a new technique called "Context Recycling." The idea is to take the existing context in a long passage and use it to generate demonstration examples that can then be used for the few-shot learning process. This allows the model to leverage the rich information already present in the passage, rather than having to learn from scratch with just a few examples.
The researchers tested this approach on various language tasks, like question answering and text summarization. They found that the Context Recycling method can indeed improve performance compared to standard few-shot techniques, especially when working with longer passages of text. This suggests that context learning in long-context models can be a valuable tool for making few-shot learning work in low-resource settings.
Technical Explanation
The paper proposes a method called "Context Recycling" to address the challenge of applying few-shot learning techniques to long passages of text. Traditionally, few-shot learning has been more effective with short prompts, as there is less context for the model to learn from.
The Context Recycling approach works by first identifying relevant context from the input passage that could be useful for generating demonstration examples. This context is then used to prompt a large language model (LLM) to produce demonstrations that can be used for the few-shot learning task.
The researchers evaluate this technique on a variety of language understanding and generation tasks, including question answering, text summarization, and logical reasoning. They find that Context Recycling can outperform standard few-shot learning approaches, especially in long-context settings. This suggests that LLMs can effectively leverage the low-resource context to generate high-quality demonstrations, which can then be used to align the model to the target task.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenges of few-shot learning in long-context settings. The Context Recycling method leverages the existing information in the passage to generate relevant demonstrations, which helps the model learn more effectively from a small number of examples.
One potential limitation of the approach is that it relies on the ability of the LLM to generate high-quality demonstrations from the given context. If the LLM struggles to produce useful examples, the few-shot learning process may not benefit as much. The paper does not provide a detailed analysis of the quality of the generated demonstrations, which would be helpful for understanding the limitations of the technique.
Additionally, the paper only evaluates the method on a limited set of tasks. While the results are promising, further research is needed to understand how well Context Recycling generalizes to a wider range of long-context language problems. Exploring the technique's performance on more diverse datasets and tasks would help establish its broader applicability.
Overall, the paper presents an interesting and potentially valuable approach to improving few-shot learning in long-context settings. The Context Recycling method is a promising step towards making few-shot techniques more effective in real-world scenarios with rich, contextual information.
Conclusion
This paper introduces a new method called "Context Recycling" that aims to make few-shot learning more effective in the context of long passages of text. By leveraging the existing information in the passage to generate demonstration examples, the approach can improve few-shot performance, especially for tasks with extensive contextual information.
The researchers' evaluation of this technique on various language understanding and generation tasks suggests that Context Recycling can outperform standard few-shot learning methods. This indicates that the ability to learn from context in long-context models can be a valuable tool for enabling few-shot learning in low-resource settings.
Overall, the paper presents an interesting and promising approach to addressing the challenges of few-shot learning in real-world, long-context scenarios. Further research is needed to fully understand the limitations and broader applicability of the Context Recycling method, but this work represents an important step forward in making few-shot techniques more effective in complex, language-based tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
0
0
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
5/24/2024
In-Context Learning with Long-Context Models: An In-Depth Exploration
Amanda Bertsch, Maor Ivgi, Uri Alon, Jonathan Berant, Matthew R. Gormley, Graham Neubig
0
0
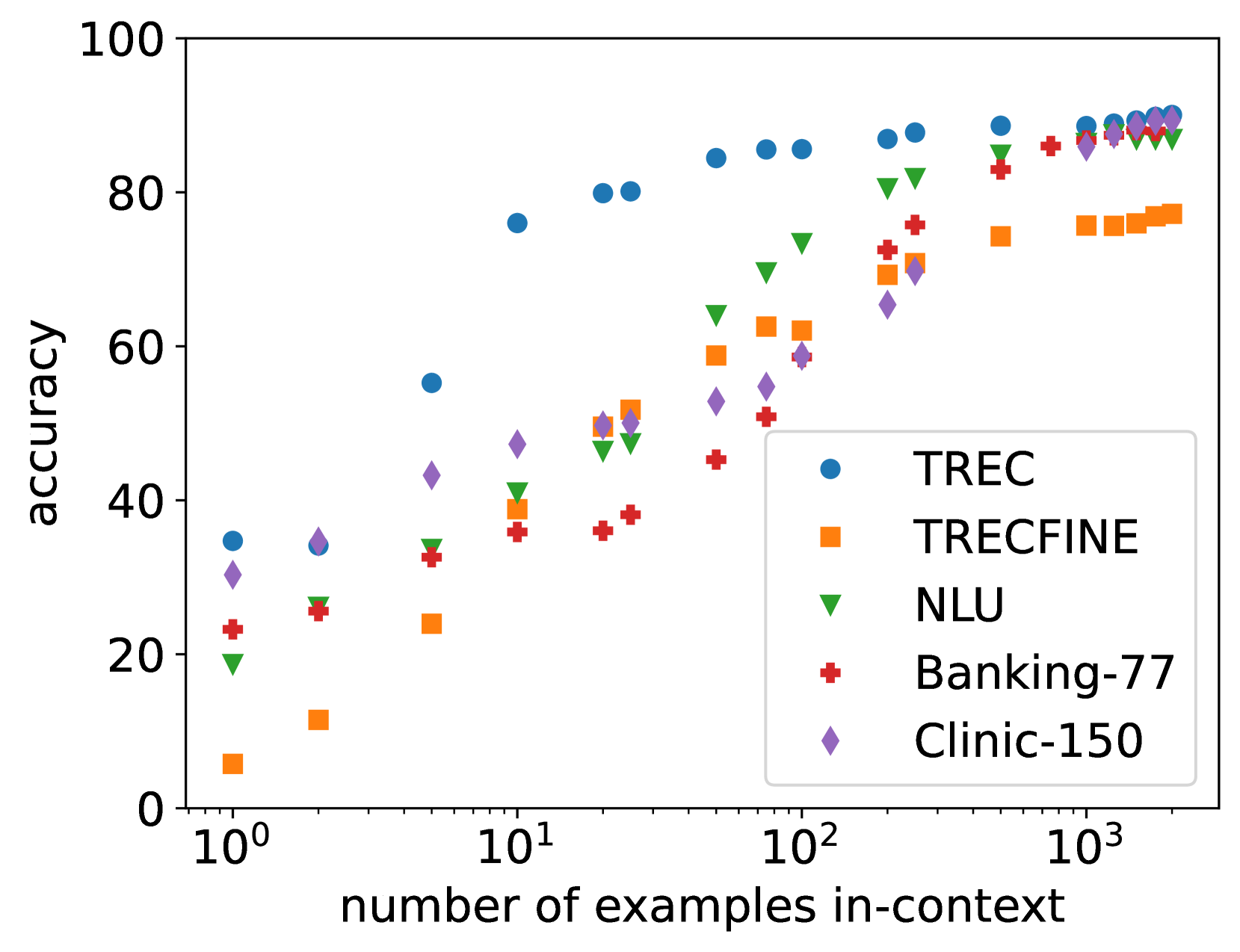
As model context lengths continue to increase, the number of demonstrations that can be provided in-context approaches the size of entire training datasets. We study the behavior of in-context learning (ICL) at this extreme scale on multiple datasets and models. We show that, for many datasets with large label spaces, performance continues to increase with hundreds or thousands of demonstrations. We contrast this with example retrieval and finetuning: example retrieval shows excellent performance at low context lengths but has diminished gains with more demonstrations; finetuning is more data hungry than ICL but can sometimes exceed long-context ICL performance with additional data. We use this ICL setting as a testbed to study several properties of both in-context learning and long-context models. We show that long-context ICL is less sensitive to random input shuffling than short-context ICL, that grouping of same-label examples can negatively impact performance, and that the performance boosts we see do not arise from cumulative gain from encoding many examples together. We conclude that although long-context ICL can be surprisingly effective, most of this gain comes from attending back to similar examples rather than task learning.
5/2/2024
Can Many-Shot In-Context Learning Help Long-Context LLM Judges? See More, Judge Better!
Mingyang Song, Mao Zheng, Xuan Luo
0
0
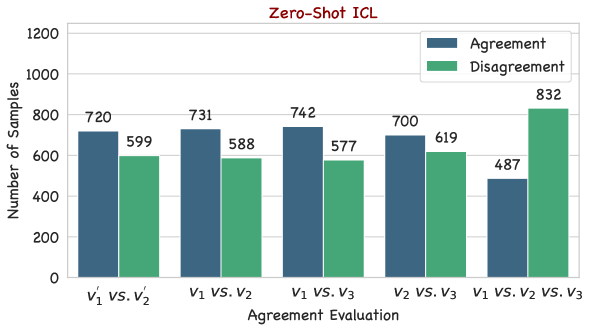
Leveraging Large Language Models (LLMs) as judges for judging the performance of LLMs has recently garnered attention. However, this type of approach is affected by the potential biases in LLMs, raising concerns about the reliability of the evaluation results. To mitigate this issue, we propose and study two versions of many-shot in-context prompts, which rely on two existing settings of many-shot ICL for helping GPT-4o-as-a-Judge in single answer grading to mitigate the potential biases in LLMs, Reinforced ICL and Unsupervised ICL. Concretely, the former utilizes in-context examples with model-generated rationales, and the latter without. Based on the designed prompts, we investigate the impact of scaling the number of in-context examples on the consistency and quality of the judgment results. Furthermore, we reveal the symbol bias hidden in the pairwise comparison of GPT-4o-as-a-Judge and propose a simple yet effective approach to mitigate it. Experimental results show that advanced long-context LLMs, such as GPT-4o, perform better in the many-shot regime than in the zero-shot regime. Meanwhile, the experimental results further verify the effectiveness of the symbol bias mitigation approach.
7/2/2024
💬
LLMs Are Few-Shot In-Context Low-Resource Language Learners
Samuel Cahyawijaya, Holy Lovenia, Pascale Fung
0
0
In-context learning (ICL) empowers large language models (LLMs) to perform diverse tasks in underrepresented languages using only short in-context information, offering a crucial avenue for narrowing the gap between high-resource and low-resource languages. Nonetheless, there is only a handful of works explored ICL for low-resource languages with most of them focusing on relatively high-resource languages, such as French and Spanish. In this work, we extensively study ICL and its cross-lingual variation (X-ICL) on 25 low-resource and 7 relatively higher-resource languages. Our study not only assesses the effectiveness of ICL with LLMs in low-resource languages but also identifies the shortcomings of in-context label alignment, and introduces a more effective alternative: query alignment. Moreover, we provide valuable insights into various facets of ICL for low-resource languages. Our study concludes the significance of few-shot in-context information on enhancing the low-resource understanding quality of LLMs through semantically relevant information by closing the language gap in the target language and aligning the semantics between the targeted low-resource and the high-resource language that the model is proficient in. Our work highlights the importance of advancing ICL research, particularly for low-resource languages. Our code is publicly released at https://github.com/SamuelCahyawijaya/in-context-alignment
6/26/2024