In-Context Learning with Long-Context Models: An In-Depth Exploration
2405.00200
0
0
Abstract
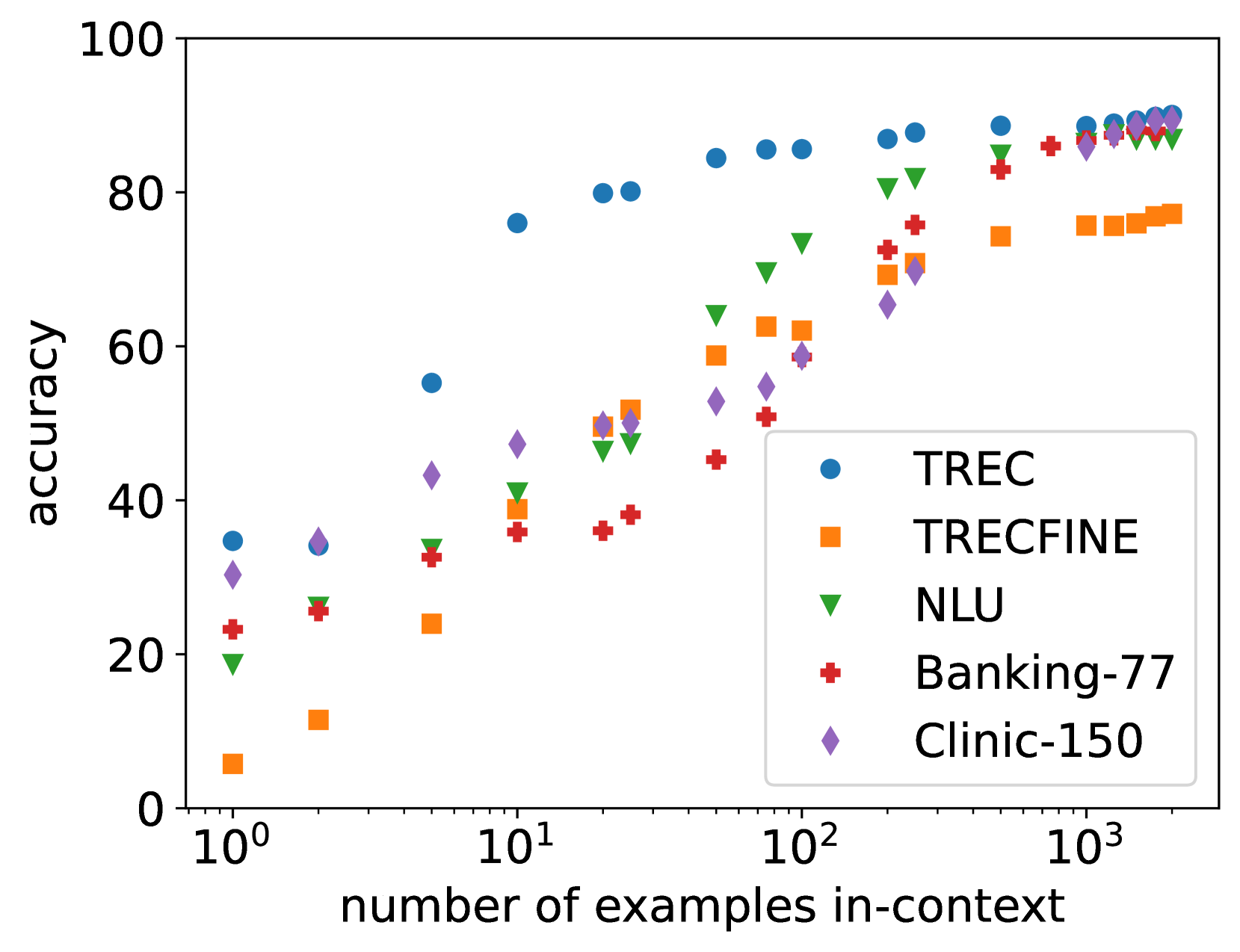
As model context lengths continue to increase, the number of demonstrations that can be provided in-context approaches the size of entire training datasets. We study the behavior of in-context learning (ICL) at this extreme scale on multiple datasets and models. We show that, for many datasets with large label spaces, performance continues to increase with hundreds or thousands of demonstrations. We contrast this with example retrieval and finetuning: example retrieval shows excellent performance at low context lengths but has diminished gains with more demonstrations; finetuning is more data hungry than ICL but can sometimes exceed long-context ICL performance with additional data. We use this ICL setting as a testbed to study several properties of both in-context learning and long-context models. We show that long-context ICL is less sensitive to random input shuffling than short-context ICL, that grouping of same-label examples can negatively impact performance, and that the performance boosts we see do not arise from cumulative gain from encoding many examples together. We conclude that although long-context ICL can be surprisingly effective, most of this gain comes from attending back to similar examples rather than task learning.
Create account to get full access
Overview
- This paper explores the challenges of in-context learning, where large language models (LLMs) are expected to learn new tasks or skills from just a few examples provided in the input context.
- The researchers investigate how well LLMs can perform in-context learning tasks with long input contexts, which is an important capability for various real-world applications.
- The paper presents a series of experiments and analyses to understand the limitations of current LLMs in this area and suggest potential directions for future research.
Plain English Explanation
In-context learning is a powerful concept that allows large language models (LLMs) to quickly learn new skills or tasks by observing just a few examples in the input. This is an exciting capability that could enable LLMs to adapt to a wide range of real-world applications without the need for extensive retraining.
However, the paper explores the challenges of in-context learning with long input contexts. The researchers find that current LLMs struggle to effectively leverage long input contexts to learn new tasks. This is an important limitation, as many real-world scenarios involve processing and understanding large amounts of contextual information.
The paper delves into the reasons behind this challenge, examining factors like the ability of LLMs to decompose and discriminate label spaces, the generalization and robustness of in-context learning, and the potential of using hints or additional information to enhance in-context learning. The researchers provide valuable insights into the inner workings of LLMs and suggest directions for future research to address these limitations.
Overall, this paper highlights the need for continued advancements in language model architectures and training approaches to make in-context learning truly effective in real-world, long-context scenarios. Understanding these challenges is crucial for developing more capable and adaptable AI systems.
Technical Explanation
The paper, "In-Context Learning with Long-Context Models: An In-Depth Exploration," investigates the performance of large language models (LLMs) in in-context learning tasks with long input contexts.
In the experimental setup, the researchers evaluated several state-of-the-art LLMs, including GPT-3, on a variety of in-context learning tasks, such as text generation, question answering, and sentiment analysis. The key aspect of their approach was to systematically increase the length of the input context provided to the models, ranging from short prompts to extended multi-paragraph contexts.
Through their experiments, the researchers found that LLMs generally struggle to effectively leverage long input contexts for in-context learning. As the context length increased, the models' performance often plateaued or even declined, indicating limitations in their ability to comprehend and apply the relevant information from the extended context.
To further investigate these limitations, the paper delves into several related aspects:
-
Decomposing label spaces and discriminating different output formats: The researchers examined how well LLMs can understand and differentiate the various possible output formats (e.g., text, numerical, categorical) required for different in-context learning tasks.
-
Generalization and robustness of in-context learning: The paper investigates the ability of LLMs to generalize their in-context learning to new, unseen examples and how robust this transfer of knowledge is.
-
Leveraging additional hints or information to enhance in-context learning: The researchers explore whether providing LLMs with additional contextual cues or instructions can help them better harness the information in long input contexts.
The findings from these analyses provide valuable insights into the inner workings and limitations of current LLMs when it comes to in-context learning with long-form input. The paper highlights the need for further advancements in language model architectures, training approaches, and contextual reasoning capabilities to overcome these challenges and enable more effective and adaptable AI systems.
Critical Analysis
The paper presents a comprehensive and well-designed exploration of the in-context learning capabilities of large language models, particularly in the context of long input sequences. The researchers have carefully constructed a series of experiments and analyses to uncover the limitations of current LLMs in this area.
One key strength of the paper is its multifaceted approach, which examines not just the overall performance of LLMs in in-context learning tasks, but also delves deeper into specific aspects that contribute to their limitations. The investigations into label space decomposition, generalization, and the potential of using additional contextual hints provide valuable insights into the underlying mechanisms and challenges.
That said, the paper also acknowledges several caveats and limitations of the research. For instance, the experiments were conducted on a limited set of tasks and datasets, and the findings may not fully generalize to all possible in-context learning scenarios. Additionally, the paper does not explore the potential impact of model scale, architecture, or training approaches on the observed limitations, which could be an interesting area for further research.
Moreover, while the paper suggests potential directions for future work, such as enhancing contextual reasoning capabilities, it does not provide a comprehensive roadmap or specific recommendations for how to address the identified challenges. Readers may be left wondering about the practical steps and research priorities that could lead to meaningful advancements in this area.
Overall, the paper makes a significant contribution to our understanding of the current limitations of in-context learning with large language models. The detailed experiments and thoughtful analyses provide a solid foundation for further research and the development of more capable and adaptable AI systems. However, the paper could be strengthened by a more extensive discussion of potential solutions and a clearer vision for future progress in this important field of study.
Conclusion
This paper presents a comprehensive exploration of the challenges faced by large language models (LLMs) when tasked with in-context learning, particularly in the context of long input sequences. The researchers conducted a series of experiments and analyses to uncover the limitations of current LLMs in leveraging extensive contextual information for quickly learning new skills or tasks.
The key findings highlight that while in-context learning is a powerful concept, LLMs struggle to effectively utilize long input contexts to perform well on a variety of tasks, including text generation, question answering, and sentiment analysis. The paper delves deeper into specific factors contributing to these limitations, such as the ability to decompose label spaces, the generalization and robustness of in-context learning, and the potential of using additional contextual hints to enhance performance.
The insights gained from this research underscore the need for continued advancements in language model architectures, training approaches, and contextual reasoning capabilities. Addressing these challenges is crucial for developing more capable and adaptable AI systems that can truly leverage the power of in-context learning in real-world applications.
By shedding light on the current limitations and suggesting potential directions for future research, this paper lays the groundwork for the next generation of language models that can seamlessly integrate and apply contextual information to quickly learn and adapt to diverse tasks and scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
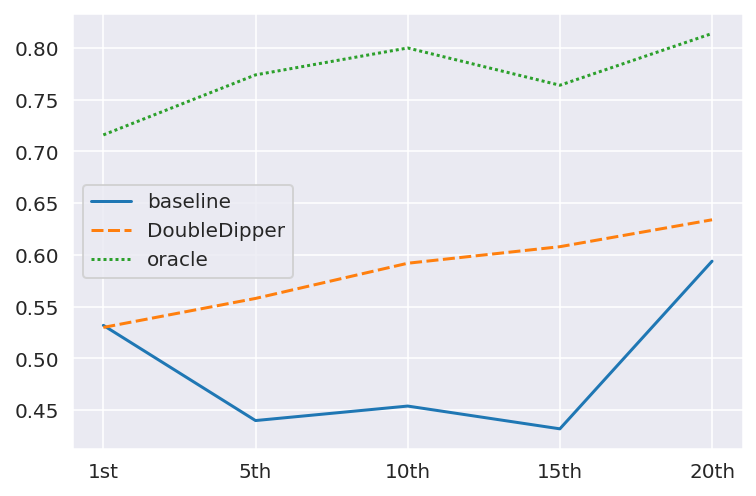
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Arie Cattan, Alon Jacovi, Alex Fabrikant, Jonathan Herzig, Roee Aharoni, Hannah Rashkin, Dror Marcus, Avinatan Hassidim, Yossi Matias, Idan Szpektor, Avi Caciularu
0
0
Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements (+23% on average across models) on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
6/26/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
How Far Can In-Context Alignment Go? Exploring the State of In-Context Alignment
Heyan Huang, Yinghao Li, Huashan Sun, Yu Bai, Yang Gao
0
0
Recent studies have demonstrated that In-Context Learning (ICL), through the use of specific demonstrations, can align Large Language Models (LLMs) with human preferences known as In-Context Alignment (ICA), indicating that models can comprehend human instructions without requiring parameter adjustments. However, the exploration of the mechanism and applicability of ICA remains limited. In this paper, we begin by dividing the context text used in ICA into three categories: format, system prompt, and example. Through ablation experiments, we investigate the effectiveness of each part in enabling ICA to function effectively. We then examine how variants in these parts impact the model's alignment performance. Our findings indicate that the example part is crucial for enhancing the model's alignment capabilities, with changes in examples significantly affecting alignment performance. We also conduct a comprehensive evaluation of ICA's zero-shot capabilities in various alignment tasks. The results indicate that compared to parameter fine-tuning methods, ICA demonstrates superior performance in knowledge-based tasks and tool-use tasks. However, it still exhibits certain limitations in areas such as multi-turn dialogues and instruction following.
6/18/2024

Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
0
0
Large Language Models (LLMs) have made significant strides in handling long sequences. Some models like Gemini could even to be capable of dealing with millions of tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their true abilities in more challenging, real-world scenarios. We introduce a benchmark (LongICLBench) for long in-context learning in extreme-label classification using six datasets with 28 to 174 classes and input lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate on 15 long-context LLMs and find that they perform well on less challenging classification tasks with smaller label space and shorter demonstrations. However, they struggle with more challenging task like Discovery with 174 labels, suggesting a gap in their ability to process long, context-rich sequences. Further analysis reveals a bias towards labels presented later in the sequence and a need for improved reasoning over multiple pieces of information. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
6/13/2024