Many-Shot In-Context Learning
2404.11018
62
0
Abstract
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Create account to get full access
Overview
- This paper explores "many-shot in-context learning," a novel approach to scaling up the performance of language models on a wide range of tasks.
- The authors propose a framework that combines large pre-trained foundation models with efficient fine-tuning techniques, enabling models to quickly adapt to new tasks using only a few examples.
- The paper compares this approach to existing few-shot and zero-shot learning methods, and demonstrates its effectiveness on a diverse set of NLP and multimodal tasks.
Plain English Explanation
The paper discusses a new way to train large language models, called "many-shot in-context learning." The key idea is to start with a very capable, pre-trained foundation model and then quickly adapt it to new tasks using only a few example inputs.
Traditionally, training language models from scratch on a new task can be very resource-intensive and time-consuming. The many-shot in-context learning approach aims to make this process much more efficient.
The researchers show that by combining a powerful, general-purpose foundation model with smart fine-tuning techniques, the model can quickly adapt to new tasks using just a handful of example inputs. This is in contrast to more common "few-shot" or "zero-shot" learning approaches, which require even less training data but may not perform as well.
Overall, this work advances the state-of-the-art in context learning and few-shot adaptation, potentially enabling language models to be more widely deployed in real-world applications that require quick adaptation to new tasks and data.
Technical Explanation
The core contribution of this paper is a framework for "many-shot in-context learning" that allows language models to efficiently adapt to new tasks using a small number of examples.
The authors start with a large, pre-trained "foundation model" - a powerful general-purpose model that has been trained on a massive amount of text data. They then propose several techniques to fine-tune this foundation model on new tasks:
- In-context learning: The model is presented with a few (e.g. 16) example inputs and outputs for the new task, which it uses to quickly adapt its behavior.
- Prompt engineering: The researchers carefully design the prompts used to present the task examples to the model, in order to maximize the efficiency of the in-context learning process.
- Multitask fine-tuning: The model is fine-tuned on multiple tasks simultaneously, allowing it to learn general patterns that transfer well to new tasks.
The paper evaluates this framework on a diverse set of NLP and multimodal tasks, and shows that it significantly outperforms traditional few-shot and zero-shot learning approaches. For example, on the GLUE benchmark, the many-shot in-context model achieves over 80% accuracy using just 16 examples per task - a level of performance that would typically require orders of magnitude more training data.
Critical Analysis
The paper makes a strong case for the effectiveness of many-shot in-context learning, but also acknowledges several important caveats and limitations:
- Task Generalization: While the model performs well on the evaluated tasks, the authors note that its ability to generalize to completely novel tasks is still an open question that requires further investigation.
- Prompt Engineering: The success of the approach is heavily dependent on the quality of the prompts used to present the task examples. Developing systematic prompt engineering techniques remains an active area of research.
- Computational Efficiency: Fine-tuning a large foundation model, even with just a few examples, can still be computationally expensive. Improving the efficiency of this process is an important direction for future work.
- Multimodal Capabilities: The paper focuses primarily on language tasks, but discusses extending the framework to multimodal context learning. Further research is needed to fully validate the approach's multimodal capabilities.
Overall, this paper represents an important step forward in developing efficient and scalable methods for adapting large language models to new tasks and domains. However, there are still many open challenges to be addressed in order to realize the full potential of this approach.
Conclusion
The "many-shot in-context learning" framework proposed in this paper offers a promising new direction for scaling up the performance of large language models. By combining powerful pre-trained foundation models with efficient fine-tuning techniques, the approach demonstrates the ability to quickly adapt to new tasks using only a small number of examples.
This work advances the state-of-the-art in few-shot and zero-shot learning, potentially enabling language models to be more widely deployed in real-world applications that require rapid adaptation to new data and tasks. However, the authors also identify several important limitations and areas for future research, such as improving task generalization, prompt engineering, computational efficiency, and multimodal capabilities.
Ultimately, this paper contributes a novel and impactful technique that brings us one step closer to building truly versatile and adaptive language models that can thrive in dynamic, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
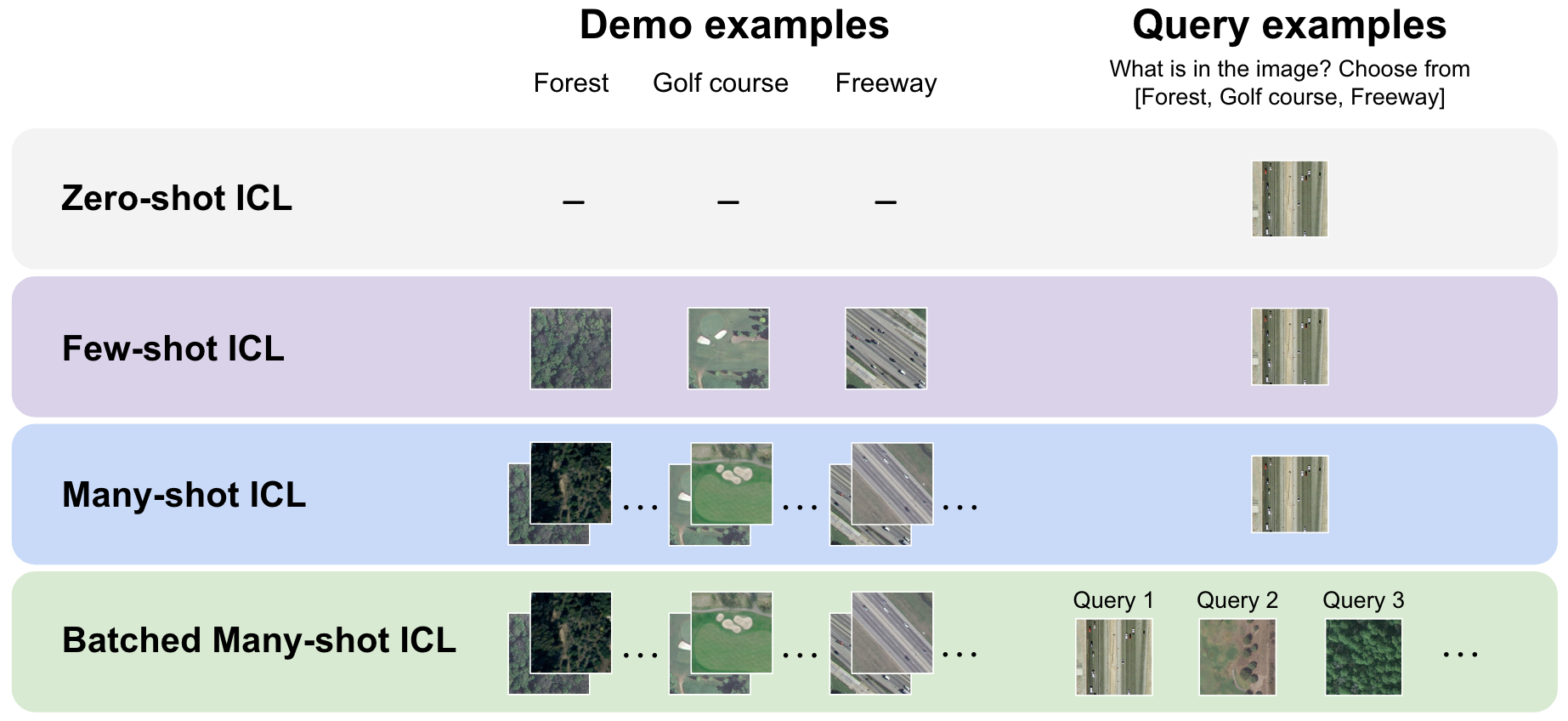
Many-Shot In-Context Learning in Multimodal Foundation Models
Yixing Jiang, Jeremy Irvin, Ji Hun Wang, Muhammad Ahmed Chaudhry, Jonathan H. Chen, Andrew Y. Ng
0
0
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many-shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL .
5/17/2024
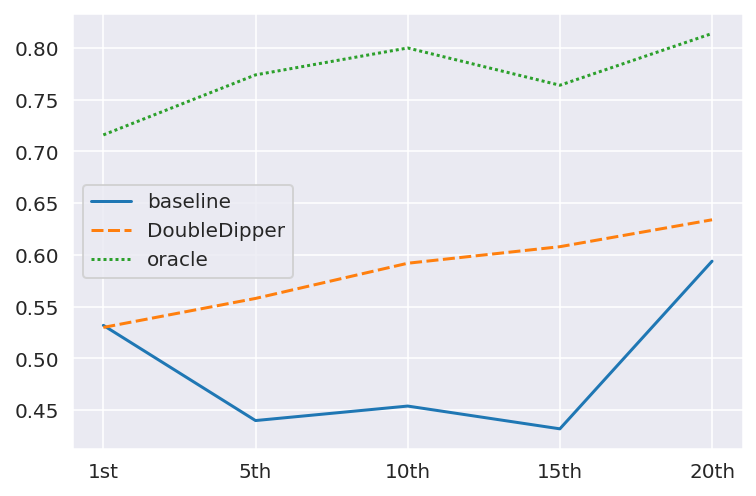
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Arie Cattan, Alon Jacovi, Alex Fabrikant, Jonathan Herzig, Roee Aharoni, Hannah Rashkin, Dror Marcus, Avinatan Hassidim, Yossi Matias, Idan Szpektor, Avi Caciularu
0
0
Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements (+23% on average across models) on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
6/26/2024
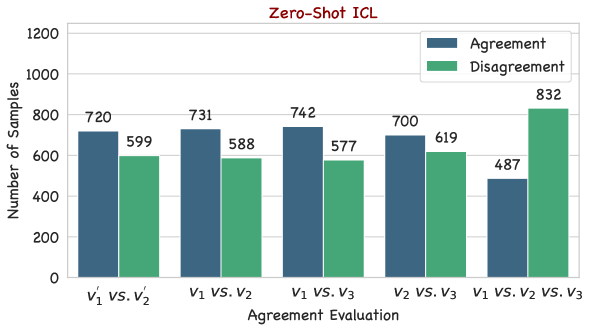
Can Many-Shot In-Context Learning Help Long-Context LLM Judges? See More, Judge Better!
Mingyang Song, Mao Zheng, Xuan Luo
0
0
Leveraging Large Language Models (LLMs) as judges for evaluating the performance of LLMs has recently garnered attention. Nonetheless, this type of approach concurrently introduces potential biases from LLMs, raising concerns about the reliability of the evaluation results. To mitigate this issue, we propose and study two versions of many-shot in-context prompts, Reinforced and Unsupervised ICL, for helping GPT-4o-as-a-Judge in single answer grading. The former uses in-context examples with model-generated rationales, and the latter without. Based on the designed prompts, we investigate the impact of scaling the number of in-context examples on the agreement and quality of the evaluation. Furthermore, we first reveal the symbol bias in GPT-4o-as-a-Judge for pairwise comparison and then propose a simple yet effective approach to mitigate it. Experimental results show that advanced long-context LLMs, such as GPT-4o, perform better in the many-shot regime than in the zero-shot regime. Meanwhile, the experimental results further verify the effectiveness of the symbol bias mitigation approach.
6/26/2024
💬
LLMs Are Few-Shot In-Context Low-Resource Language Learners
Samuel Cahyawijaya, Holy Lovenia, Pascale Fung
0
0
In-context learning (ICL) empowers large language models (LLMs) to perform diverse tasks in underrepresented languages using only short in-context information, offering a crucial avenue for narrowing the gap between high-resource and low-resource languages. Nonetheless, there is only a handful of works explored ICL for low-resource languages with most of them focusing on relatively high-resource languages, such as French and Spanish. In this work, we extensively study ICL and its cross-lingual variation (X-ICL) on 25 low-resource and 7 relatively higher-resource languages. Our study not only assesses the effectiveness of ICL with LLMs in low-resource languages but also identifies the shortcomings of in-context label alignment, and introduces a more effective alternative: query alignment. Moreover, we provide valuable insights into various facets of ICL for low-resource languages. Our study concludes the significance of few-shot in-context information on enhancing the low-resource understanding quality of LLMs through semantically relevant information by closing the language gap in the target language and aligning the semantics between the targeted low-resource and the high-resource language that the model is proficient in. Our work highlights the importance of advancing ICL research, particularly for low-resource languages. Our code is publicly released at https://github.com/SamuelCahyawijaya/in-context-alignment
6/26/2024