Can Large Language Models Aid in Annotating Speech Emotional Data? Uncovering New Frontiers
2307.06090
0
0

Abstract
Despite recent advancements in speech emotion recognition (SER) models, state-of-the-art deep learning (DL) approaches face the challenge of the limited availability of annotated data. Large language models (LLMs) have revolutionised our understanding of natural language, introducing emergent properties that broaden comprehension in language, speech, and vision. This paper examines the potential of LLMs to annotate abundant speech data, aiming to enhance the state-of-the-art in SER. We evaluate this capability across various settings using publicly available speech emotion classification datasets. Leveraging ChatGPT, we experimentally demonstrate the promising role of LLMs in speech emotion data annotation. Our evaluation encompasses single-shot and few-shots scenarios, revealing performance variability in SER. Notably, we achieve improved results through data augmentation, incorporating ChatGPT-annotated samples into existing datasets. Our work uncovers new frontiers in speech emotion classification, highlighting the increasing significance of LLMs in this field moving forward.
Create account to get full access
Overview
- This paper explores the potential of using large language models (LLMs) to aid in the annotation of speech emotion data, which is a crucial task in speech emotion recognition.
- The researchers investigate the effectiveness of LLMs as virtual annotators, comparing their performance to human annotators and examining their potential for data augmentation.
- The paper also discusses the ethical considerations and potential biases inherent in using LLMs for this task, as well as the broader implications of integrating LLMs into speech-centric multimodal systems.
Plain English Explanation
The paper examines whether large language models can be used to help annotate speech data with emotional information. Annotating speech data with emotional information is an important step in developing speech emotion recognition systems, which can be used in a variety of applications like virtual assistants and mental health monitoring.
The researchers compare the performance of LLMs as virtual annotators to human annotators, to see if the models can be as effective at this task. They also investigate whether LLMs can be used to generate additional annotated data, which could help train more robust speech emotion recognition models.
Additionally, the paper discusses the ethical considerations and potential biases that come with using LLMs for this task, as well as how these models could be integrated into speech-centric multimodal systems.
Overall, the paper explores new frontiers in using powerful language models to assist with the challenging task of annotating emotional speech data, which could have important implications for a variety of real-world applications.
Technical Explanation
The researchers evaluate the effectiveness of LLMs as virtual annotators for speech emotion data, comparing their performance to human annotators. They use a dataset of emotional speech recordings and have both LLMs and human annotators label the data with emotional categories.
The results show that the LLMs can achieve comparable performance to human annotators on this task, suggesting they could be a useful tool for automating the annotation process. The researchers also investigate using LLMs for data augmentation, generating synthetic annotated samples to expand the training data for speech emotion recognition models.
In addition, the paper discusses the ethical considerations and potential biases that arise when using LLMs for this application, such as the models potentially reflecting societal biases in their emotional judgments. The authors also explore how these LLM-based approaches could be integrated into speech-centric multimodal systems that combine speech, text, and other modalities.
Critical Analysis
The paper provides a compelling exploration of using LLMs to assist with the annotation of speech emotion data, but it also acknowledges several important caveats and limitations.
One key concern is the potential for biases and ethical issues to arise when relying on LLMs for this task, as the models may reflect societal biases in their emotional judgments. The researchers emphasize the need for careful monitoring and mitigation of these biases.
Additionally, the paper notes that the performance of the LLMs, while promising, is not yet on par with highly trained human annotators. Further research is needed to improve the models' accuracy and robustness for this specific application.
Another area for further exploration is the integration of LLMs into speech-centric multimodal systems, which could unlock new possibilities for emotion recognition and other speech-related tasks. However, the challenges of combining different modalities and data sources will need to be carefully addressed.
Conclusion
This paper presents a novel approach to using large language models to assist in the annotation of speech emotion data, a crucial step in developing robust speech emotion recognition systems. The researchers demonstrate the potential of LLMs to serve as effective virtual annotators, with performance comparable to human experts.
However, the study also highlights the need to address ethical considerations and potential biases inherent in using these powerful language models for this task. As the field of speech emotion recognition continues to evolve, the integration of LLMs into speech-centric multimodal systems could open up new frontiers, but will require careful design and ongoing evaluation to ensure reliable and responsible applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Modeling Emotions and Ethics with Large Language Models
Edward Y. Chang
0
0
This paper explores the integration of human-like emotions and ethical considerations into Large Language Models (LLMs). We first model eight fundamental human emotions, presented as opposing pairs, and employ collaborative LLMs to reinterpret and express these emotions across a spectrum of intensity. Our focus extends to embedding a latent ethical dimension within LLMs, guided by a novel self-supervised learning algorithm with human feedback (SSHF). This approach enables LLMs to perform self-evaluations and adjustments concerning ethical guidelines, enhancing their capability to generate content that is not only emotionally resonant but also ethically aligned. The methodologies and case studies presented herein illustrate the potential of LLMs to transcend mere text and image generation, venturing into the realms of empathetic interaction and principled decision-making, thereby setting a new precedent in the development of emotionally aware and ethically conscious AI systems.
4/23/2024

The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
0
0
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
5/3/2024
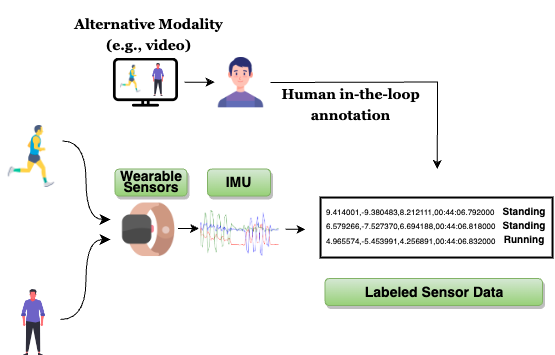
Evaluating Large Language Models as Virtual Annotators for Time-series Physical Sensing Data
Aritra Hota, Soumyajit Chatterjee, Sandip Chakraborty
0
0
Traditional human-in-the-loop-based annotation for time-series data like inertial data often requires access to alternate modalities like video or audio from the environment. These alternate sources provide the necessary information to the human annotator, as the raw numeric data is often too obfuscated even for an expert. However, this traditional approach has many concerns surrounding overall cost, efficiency, storage of additional modalities, time, scalability, and privacy. Interestingly, recent large language models (LLMs) are also trained with vast amounts of publicly available alphanumeric data, which allows them to comprehend and perform well on tasks beyond natural language processing. Naturally, this opens up a potential avenue to explore LLMs as virtual annotators where the LLMs will be directly provided the raw sensor data for annotation instead of relying on any alternate modality. Naturally, this could mitigate the problems of the traditional human-in-the-loop approach. Motivated by this observation, we perform a detailed study in this paper to assess whether the state-of-the-art (SOTA) LLMs can be used as virtual annotators for labeling time-series physical sensing data. To perform this in a principled manner, we segregate the study into two major phases. In the first phase, we investigate the challenges an LLM like GPT-4 faces in comprehending raw sensor data. Considering the observations from phase 1, in the next phase, we investigate the possibility of encoding the raw sensor data using SOTA SSL approaches and utilizing the projected time-series data to get annotations from the LLM. Detailed evaluation with four benchmark HAR datasets shows that SSL-based encoding and metric-based guidance allow the LLM to make more reasonable decisions and provide accurate annotations without requiring computationally expensive fine-tuning or sophisticated prompt engineering.
4/16/2024
💬
EmoLLMs: A Series of Emotional Large Language Models and Annotation Tools for Comprehensive Affective Analysis
Zhiwei Liu, Kailai Yang, Tianlin Zhang, Qianqian Xie, Sophia Ananiadou
0
0
Sentiment analysis and emotion detection are important research topics in natural language processing (NLP) and benefit many downstream tasks. With the widespread application of LLMs, researchers have started exploring the application of LLMs based on instruction-tuning in the field of sentiment analysis. However, these models only focus on single aspects of affective classification tasks (e.g. sentimental polarity or categorical emotions), and overlook the regression tasks (e.g. sentiment strength or emotion intensity), which leads to poor performance in downstream tasks. The main reason is the lack of comprehensive affective instruction tuning datasets and evaluation benchmarks, which cover various affective classification and regression tasks. Moreover, although emotional information is useful for downstream tasks, existing downstream datasets lack high-quality and comprehensive affective annotations. In this paper, we propose EmoLLMs, the first series of open-sourced instruction-following LLMs for comprehensive affective analysis based on fine-tuning various LLMs with instruction data, the first multi-task affective analysis instruction dataset (AAID) with 234K data samples based on various classification and regression tasks to support LLM instruction tuning, and a comprehensive affective evaluation benchmark (AEB) with 14 tasks from various sources and domains to test the generalization ability of LLMs. We propose a series of EmoLLMs by fine-tuning LLMs with AAID to solve various affective instruction tasks. We compare our model with a variety of LLMs on AEB, where our models outperform all other open-sourced LLMs, and surpass ChatGPT and GPT-4 in most tasks, which shows that the series of EmoLLMs achieve the ChatGPT-level and GPT-4-level generalization capabilities on affective analysis tasks, and demonstrates our models can be used as affective annotation tools.
6/19/2024