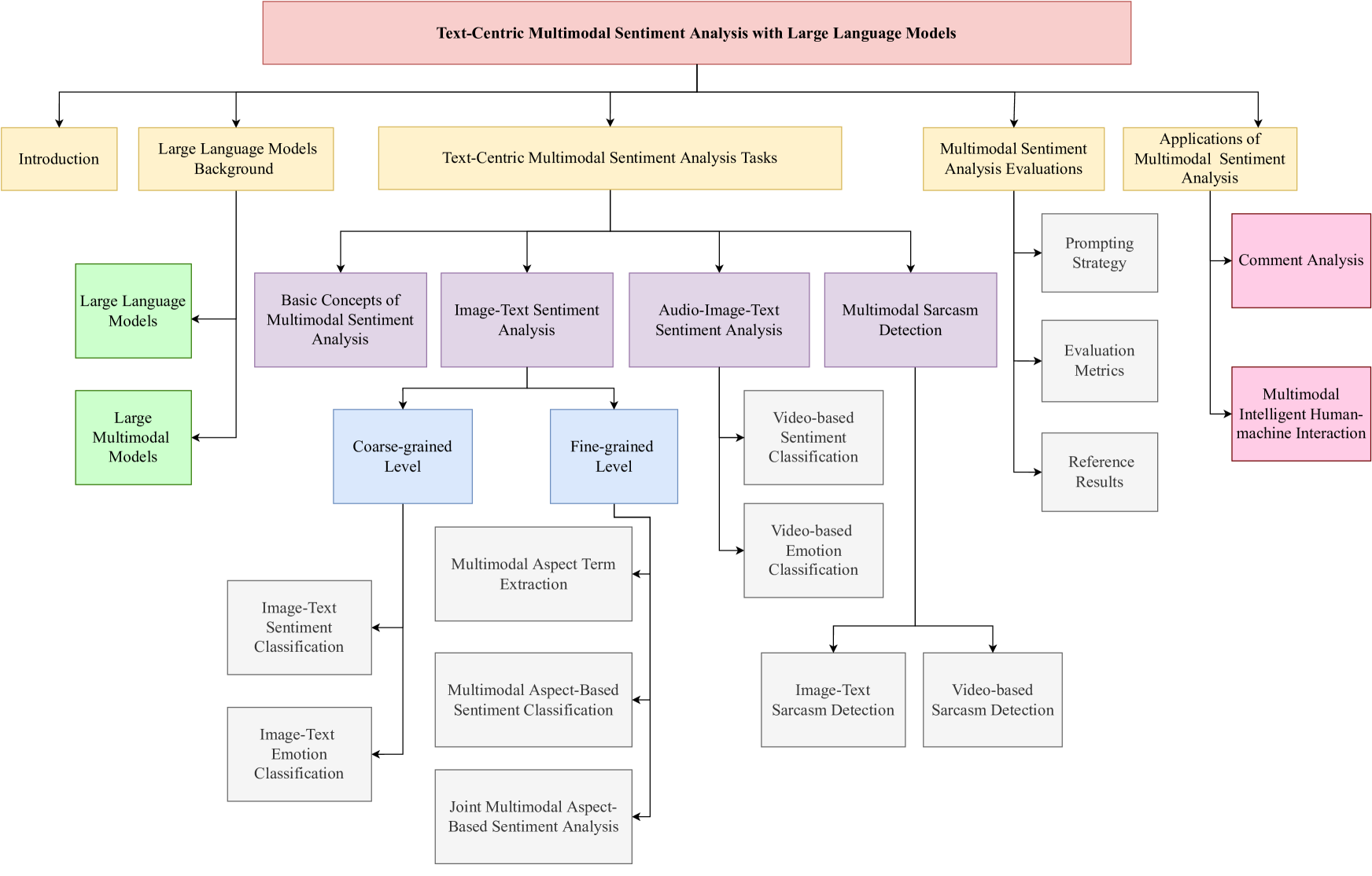
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
2406.08068
0
0
Abstract
Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
Create account to get full access
Large Language Models Background
Overview
- Large language models (LLMs) are powerful AI systems trained on vast amounts of text data to generate human-like language
- These models have shown impressive capabilities in tasks like natural language processing, text generation, and question answering
- LLMs have recently been combined with other modalities like vision and audio, leading to multimodal large language models (MM-LLMs) that can process and generate a wide range of multimedia content
Plain English Explanation
Large language models are AI systems that have been trained on huge amounts of text data, like books, websites, and conversations. This training allows them to understand and generate human-like language [link to https://aimodels.fyi/papers/arxiv/survey-multimodal-large-language-model-from-data]. They can do things like answer questions, summarize information, and even write stories. More recently, these language models have been combined with other types of data like images and audio, creating "multimodal" models that can process and generate a variety of multimedia content [link to https://aimodels.fyi/papers/arxiv/revolution-multimodal-large-language-models-survey]. This allows them to tackle more complex tasks that involve multiple forms of information.
Technical Explanation
Large language models (LLMs) are a class of AI models that have been trained on vast amounts of natural language data, such as books, websites, and conversations. This training allows them to develop a deep understanding of language, enabling them to perform a wide range of natural language processing tasks with impressive performance [link to https://aimodels.fyi/papers/arxiv/review-multi-modal-large-language-vision-models].
Recently, researchers have begun to combine LLMs with other modalities, such as vision and audio, creating multimodal large language models (MM-LLMs) [link to https://aimodels.fyi/papers/arxiv/m2sa-multimodal-multilingual-model-sentiment-analysis-tweets]. These models can process and generate content that involves multiple forms of information, opening up new possibilities for more complex and holistic understanding and generation of multimedia data. For example, an MM-LLM could be used to analyze the sentiment expressed in a social media post that includes both text and an image [link to https://aimodels.fyi/papers/arxiv/can-large-language-models-aid-annotating-speech].
Critical Analysis
While the advancements in large language models and their multimodal extensions are impressive, there are some potential concerns and limitations to consider. One key issue is the potential for these models to perpetuate or amplify societal biases present in the training data, which could lead to unfair or discriminatory outputs [link to https://aimodels.fyi/papers/arxiv/survey-multimodal-large-language-model-from-data].
Additionally, the computational and energy requirements for training and running these large, complex models can be significant, raising concerns about their environmental impact and accessibility, especially for resource-constrained applications [link to https://aimodels.fyi/papers/arxiv/revolution-multimodal-large-language-models-survey].
Further research is needed to address these challenges and ensure that the benefits of these powerful models are realized in a responsible and equitable manner.
Conclusion
Large language models and their multimodal extensions represent a major advancement in natural language processing and multimedia understanding. By leveraging vast amounts of text, image, audio, and other data, these models can tackle increasingly complex tasks that involve multiple forms of information.
However, as these technologies continue to evolve, it will be crucial to address potential issues around bias, computational resource requirements, and other concerns to ensure that the benefits of these powerful models are distributed fairly and responsibly [link to https://aimodels.fyi/papers/arxiv/review-multi-modal-large-language-vision-models]. Ongoing research and thoughtful development will be key to realizing the full potential of large language models and their multimodal counterparts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Gaurish Thakkar, Sherzod Hakimov, Marko Tadi'c
0
0
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
6/13/2024

A Survey of Multimodal Large Language Model from A Data-centric Perspective
Tianyi Bai, Hao Liang, Binwang Wan, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, Conghui He, Binhang Yuan, Wentao Zhang
0
0
Human beings perceive the world through diverse senses such as sight, smell, hearing, and touch. Similarly, multimodal large language models (MLLMs) enhance the capabilities of traditional large language models by integrating and processing data from multiple modalities including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for datasets and review benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
5/28/2024

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024