The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
2405.01299
0
0

Abstract
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
Create account to get full access
Overview
- This paper provides a comparative overview and empirical analysis of using large language models (LLMs) as annotators for various tasks.
- The researchers explore the effectiveness of LLMs in directly generating annotations, compared to traditional approaches that use LLMs to assist human annotators.
- The study evaluates the performance of LLMs across different annotation tasks and datasets, offering insights into the strengths and limitations of this approach.
Plain English Explanation
In this paper, the researchers investigate the use of large language models (LLMs) as direct annotators, rather than just as assistants to human annotators. Annotation is the process of adding labels or metadata to data, which is crucial for training machine learning models. The researchers wanted to see how well LLMs, such as GPT-3, could perform this task on their own, without human guidance.
The paper compares the performance of LLMs as direct annotators to the traditional approach of using LLMs to help human annotators. The researchers evaluated the LLMs across different annotation tasks and datasets to understand their strengths and limitations. This could have important implications for how we leverage LLMs to support research and annotate data.
Technical Explanation
The researchers conducted a series of experiments to assess the effectiveness of LLMs as direct annotators. They compared the performance of LLM-based annotation to traditional approaches that use LLMs to assist human annotators.
The study evaluated the LLMs across various annotation tasks, such as text classification, named entity recognition, and relation extraction. The researchers used different datasets to test the LLMs' capabilities, including standard benchmarks and real-world datasets.
The paper presents a detailed analysis of the LLMs' performance, including metrics such as precision, recall, and F1 score. The researchers also examined the factors that influenced the LLMs' effectiveness, such as the complexity of the annotation task, the quality of the training data, and the architecture of the LLM itself.
Critical Analysis
The paper acknowledges several limitations and areas for further research. For example, the researchers note that the performance of LLMs as direct annotators may be sensitive to the specific annotation task and dataset, and that more work is needed to understand the factors that determine their effectiveness.
Additionally, the paper raises concerns about the reliability and trustworthiness of LLM-based annotations, particularly in sensitive or high-stakes domains. The researchers suggest that a hybrid approach combining LLMs and human annotators may be necessary to ensure the quality and reliability of annotations.
Overall, this paper provides a valuable contribution to the ongoing discussion around the use of LLMs in research and data annotation tasks. While the results are promising, the researchers highlight the need for further investigation and caution in deploying LLMs as direct annotators in real-world applications.
Conclusion
This study presents a comprehensive evaluation of using LLMs as direct annotators, compared to traditional approaches that rely on LLMs to assist human annotators. The findings suggest that LLMs can be effective in certain annotation tasks, but their performance is influenced by various factors, and their reliability in sensitive domains may require a more cautious, hybrid approach.
The research highlights the potential of LLMs to streamline and optimize annotation processes, but also underscores the need for further investigation and careful consideration of the limitations and potential risks. As the field of machine-assisted research continues to evolve, this paper offers valuable insights into the effective and responsible use of LLMs as annotation tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
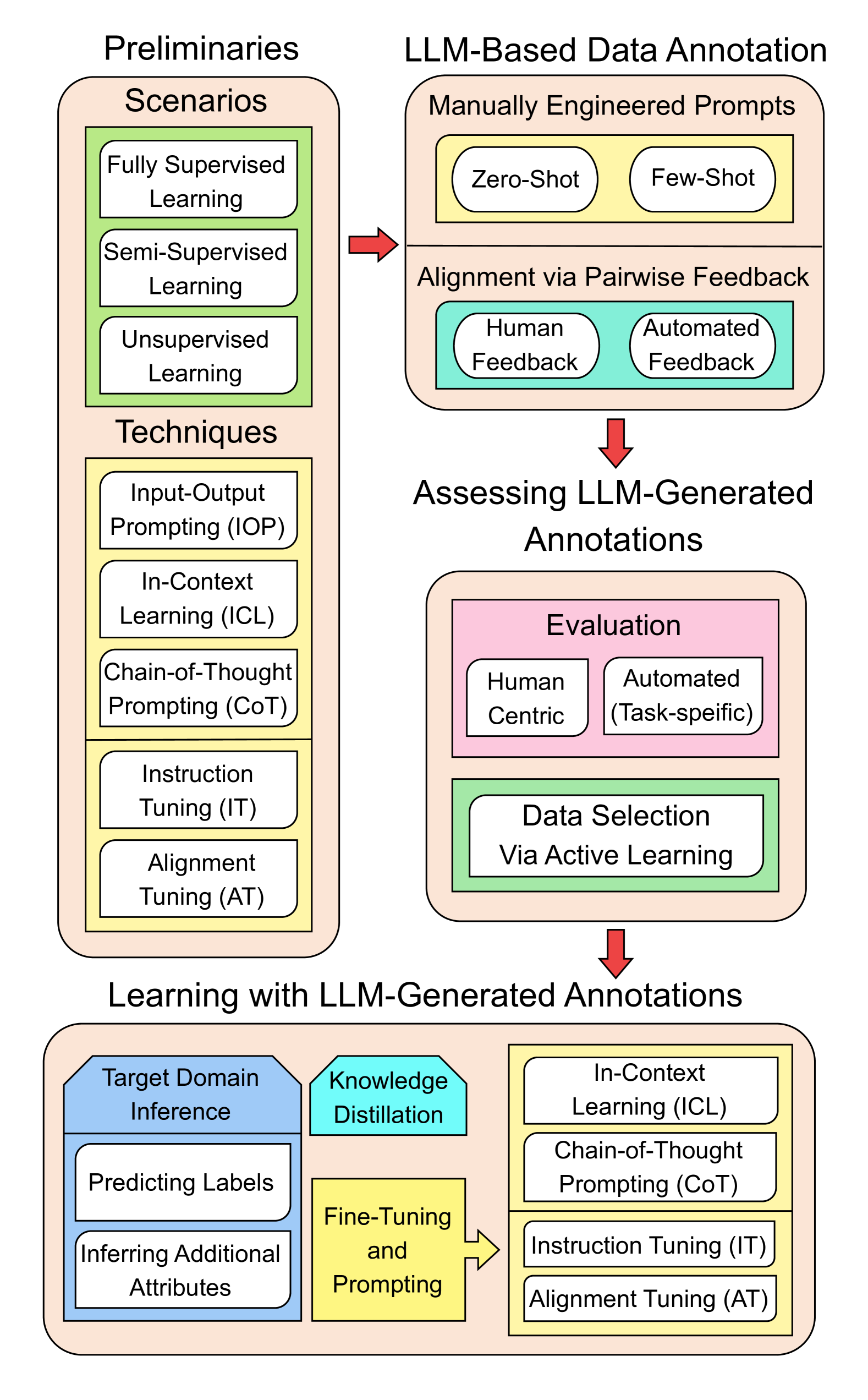
Large Language Models for Data Annotation: A Survey
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, Huan Liu
0
0
Data annotation generally refers to the labeling or generating of raw data with relevant information, which could be used for improving the efficacy of machine learning models. The process, however, is labor-intensive and costly. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to automate the complicated process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, we uniquely focus on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Annotation Generation, LLM-Generated Annotations Assessment, and LLM-Generated Annotations Utilization. Furthermore, this survey includes an in-depth taxonomy of data types that LLMs can annotate, a comprehensive review of learning strategies for models utilizing LLM-generated annotations, and a detailed discussion of the primary challenges and limitations associated with using LLMs for data annotation. Serving as a key guide, this survey aims to assist researchers and practitioners in exploring the potential of the latest LLMs for data annotation, thereby fostering future advancements in this critical field.
6/26/2024
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024
Advancing Annotation of Stance in Social Media Posts: A Comparative Analysis of Large Language Models and Crowd Sourcing
Mao Li, Frederick Conrad
0
0
In the rapidly evolving landscape of Natural Language Processing (NLP), the use of Large Language Models (LLMs) for automated text annotation in social media posts has garnered significant interest. Despite the impressive innovations in developing LLMs like ChatGPT, their efficacy, and accuracy as annotation tools are not well understood. In this paper, we analyze the performance of eight open-source and proprietary LLMs for annotating the stance expressed in social media posts, benchmarking their performance against human annotators' (i.e., crowd-sourced) judgments. Additionally, we investigate the conditions under which LLMs are likely to disagree with human judgment. A significant finding of our study is that the explicitness of text expressing a stance plays a critical role in how faithfully LLMs' stance judgments match humans'. We argue that LLMs perform well when human annotators do, and when LLMs fail, it often corresponds to situations in which human annotators struggle to reach an agreement. We conclude with recommendations for a comprehensive approach that combines the precision of human expertise with the scalability of LLM predictions. This study highlights the importance of improving the accuracy and comprehensiveness of automated stance detection, aiming to advance these technologies for more efficient and unbiased analysis of social media.
6/12/2024
💬
Are Large Language Models Reliable Argument Quality Annotators?
Nailia Mirzakhmedova, Marcel Gohsen, Chia Hao Chang, Benno Stein
0
0
Evaluating the quality of arguments is a crucial aspect of any system leveraging argument mining. However, it is a challenge to obtain reliable and consistent annotations regarding argument quality, as this usually requires domain-specific expertise of the annotators. Even among experts, the assessment of argument quality is often inconsistent due to the inherent subjectivity of this task. In this paper, we study the potential of using state-of-the-art large language models (LLMs) as proxies for argument quality annotators. To assess the capability of LLMs in this regard, we analyze the agreement between model, human expert, and human novice annotators based on an established taxonomy of argument quality dimensions. Our findings highlight that LLMs can produce consistent annotations, with a moderately high agreement with human experts across most of the quality dimensions. Moreover, we show that using LLMs as additional annotators can significantly improve the agreement between annotators. These results suggest that LLMs can serve as a valuable tool for automated argument quality assessment, thus streamlining and accelerating the evaluation of large argument datasets.
4/16/2024