Can Large Language Models (or Humans) Disentangle Text?

0

Sign in to get full access
Overview
- This paper investigates whether large language models (LLMs) or humans can effectively "distill" text, which means summarizing the key ideas from a longer passage into a concise form.
- The researchers explore the capabilities and limitations of both LLMs and humans in this task, and provide insights into the factors that influence text distillation performance.
Plain English Explanation
The paper examines the ability of large language models (AI systems that are trained on vast amounts of text data) and humans to take a longer piece of writing and condense it down to the core ideas. The researchers wanted to understand how well these two approaches - AI versus human - can summarize the main points of a text in a clear, concise way.
This is an important task because being able to distill key information from larger documents can save time and help people quickly grasp the essential details. The paper compares the strengths and weaknesses of using an AI system versus relying on human summarization skills. The findings provide insights into the factors that lead to more effective text distillation, whether done by machines or people.
Technical Explanation
The paper presents a study that compares the performance of large language models (LLMs) and humans in the task of text distillation. The researchers defined distillation as the process of extracting the key ideas and central narrative from a longer passage and conveying them concisely.
They evaluated LLM-based and human-generated distillations using a range of metrics, including [link to https://aimodels.fyi/papers/arxiv/effectiveness-llms-as-annotators-comparative-overview-empirical]semantic similarity, factual accuracy, and coherence. The experiments tested distillation across different text domains, lengths, and complexity levels to understand the factors that influence performance.
The results indicate that while LLMs can produce relatively coherent and semantically relevant distillations, they struggle to maintain the fidelity of key facts and details compared to human summaries. Factors like passage length, topic familiarity, and language complexity were found to significantly impact the quality of both LLM-based and human-generated distillations.
Critical Analysis
The paper provides a thoughtful analysis of the strengths and limitations of using LLMs versus humans for the task of text distillation. The researchers acknowledge that while LLMs show promise in summarization, they currently lack the deeper understanding and reasoning capabilities that humans leverage to preserve essential details and coherence.
However, the study could have benefited from a more in-depth exploration of the specific failure modes of LLMs, such as [link to https://aimodels.fyi/papers/arxiv/can-llm-generated-misinformation-be-detected]hallucination of factual claims or [link to https://aimodels.fyi/papers/arxiv/pitfalls-conversational-llms-news-debiasing]biased language selection. Further research is also needed to determine if LLM distillation performance can be improved through fine-tuning or other architectural enhancements.
Additionally, the paper does not delve into the potential privacy risks associated with [link to https://aimodels.fyi/papers/arxiv/understanding-privacy-risks-embeddings-induced-by-large]language model-based text processing, which is an important consideration for real-world applications.
Conclusion
This paper makes a valuable contribution to our understanding of the capabilities and limitations of large language models and humans in the task of text distillation. The findings suggest that while LLMs show promise in summarizing text, they currently fall short of human-level performance in preserving essential facts and details. The insights from this research can inform the development of more robust and reliable text summarization systems, whether powered by AI or human intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can Large Language Models (or Humans) Disentangle Text?
Nicolas Audinet de Pieuchon, Adel Daoud, Connor Thomas Jerzak, Moa Johansson, Richard Johansson
We investigate the potential of large language models (LLMs) to disentangle text variables--to remove the textual traces of an undesired forbidden variable in a task sometimes known as text distillation and closely related to the fairness in AI and causal inference literature. We employ a range of various LLM approaches in an attempt to disentangle text by identifying and removing information about a target variable while preserving other relevant signals. We show that in the strong test of removing sentiment, the statistical association between the processed text and sentiment is still detectable to machine learning classifiers post-LLM-disentanglement. Furthermore, we find that human annotators also struggle to disentangle sentiment while preserving other semantic content. This suggests there may be limited separability between concept variables in some text contexts, highlighting limitations of methods relying on text-level transformations and also raising questions about the robustness of disentanglement methods that achieve statistical independence in representation space.
Read more5/6/2024

0
Do Large Language Models Possess Sensitive to Sentiment?
Yang Liu, Xichou Zhu, Zhou Shen, Yi Liu, Min Li, Yujun Chen, Benzi John, Zhenzhen Ma, Tao Hu, Zhiyang Xu, Wei Luo, Junhui Wang
Large Language Models (LLMs) have recently displayed their extraordinary capabilities in language understanding. However, how to comprehensively assess the sentiment capabilities of LLMs continues to be a challenge. This paper investigates the ability of LLMs to detect and react to sentiment in text modal. As the integration of LLMs into diverse applications is on the rise, it becomes highly critical to comprehend their sensitivity to emotional tone, as it can influence the user experience and the efficacy of sentiment-driven tasks. We conduct a series of experiments to evaluate the performance of several prominent LLMs in identifying and responding appropriately to sentiments like positive, negative, and neutral emotions. The models' outputs are analyzed across various sentiment benchmarks, and their responses are compared with human evaluations. Our discoveries indicate that although LLMs show a basic sensitivity to sentiment, there are substantial variations in their accuracy and consistency, emphasizing the requirement for further enhancements in their training processes to better capture subtle emotional cues. Take an example in our findings, in some cases, the models might wrongly classify a strongly positive sentiment as neutral, or fail to recognize sarcasm or irony in the text. Such misclassifications highlight the complexity of sentiment analysis and the areas where the models need to be refined. Another aspect is that different LLMs might perform differently on the same set of data, depending on their architecture and training datasets. This variance calls for a more in-depth study of the factors that contribute to the performance differences and how they can be optimized.
Read more9/5/2024

0
Zero-Shot Machine-Generated Text Detection Using Mixture of Large Language Models
Matthieu Dubois, Franc{c}ois Yvon, Pablo Piantanida
The dissemination of Large Language Models (LLMs), trained at scale, and endowed with powerful text-generating abilities has vastly increased the threats posed by generative AI technologies by reducing the cost of producing harmful, toxic, faked or forged content. In response, various proposals have been made to automatically discriminate artificially generated from human-written texts, typically framing the problem as a classification problem. Most approaches evaluate an input document by a well-chosen detector LLM, assuming that low-perplexity scores reliably signal machine-made content. As using one single detector can induce brittleness of performance, we instead consider several and derive a new, theoretically grounded approach to combine their respective strengths. Our experiments, using a variety of generator LLMs, suggest that our method effectively increases the robustness of detection.
Read more9/14/2024
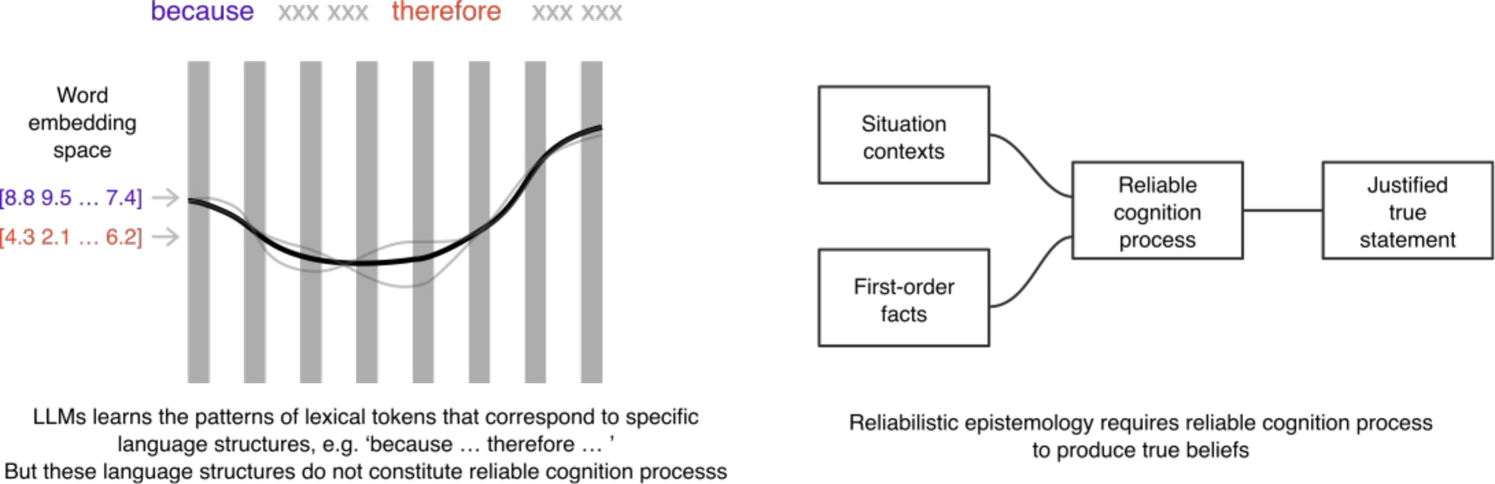
0
Misinforming LLMs: vulnerabilities, challenges and opportunities
Bo Zhou, Daniel Gei{ss}ler, Paul Lukowicz
Large Language Models (LLMs) have made significant advances in natural language processing, but their underlying mechanisms are often misunderstood. Despite exhibiting coherent answers and apparent reasoning behaviors, LLMs rely on statistical patterns in word embeddings rather than true cognitive processes. This leads to vulnerabilities such as hallucination and misinformation. The paper argues that current LLM architectures are inherently untrustworthy due to their reliance on correlations of sequential patterns of word embedding vectors. However, ongoing research into combining generative transformer-based models with fact bases and logic programming languages may lead to the development of trustworthy LLMs capable of generating statements based on given truth and explaining their self-reasoning process.
Read more8/6/2024