Misinforming LLMs: vulnerabilities, challenges and opportunities

0
Sign in to get full access
Overview
- Explores the vulnerabilities of large language models (LLMs) to misinformation and the challenges in building trustworthy AI systems
- Examines the phenomenon of "hallucination" where LLMs generate plausible-sounding but factually incorrect information
- Discusses strategies for detecting and mitigating misinformation in LLM outputs
Plain English Explanation
Large language models (LLMs) like ChatGPT have become incredibly powerful at generating human-like text. However, this power also comes with a vulnerability - LLMs can sometimes produce information that sounds convincing but is actually false or misleading. This is known as "hallucination," where the model makes up facts or details that do not align with the real world.
The paper examines the challenges in building trustworthy AI systems that can reliably distinguish truth from fiction. It looks at strategies for detecting hallucination and mitigating the spread of misinformation generated by LLMs. This is an important issue as these models are being deployed for a growing number of real-world applications where accuracy and truthfulness are critical.
The research explores ways to make LLMs more robust and less susceptible to producing misinformation. This could involve techniques like better training data curation, prompting strategies, and model architectures designed to improve factual grounding. Ultimately, the goal is to harness the power of LLMs while ensuring the information they generate can be trusted.
Technical Explanation
The paper first provides an overview of the phenomenon of "hallucination" in large language models (LLMs). Hallucination refers to the ability of these models to generate plausible-sounding but factually incorrect information. This can occur when the training data contains biases or gaps, or when the model is asked to extrapolate beyond its training distribution.
The authors then discuss several strategies for detecting and mitigating hallucination in LLM outputs. This includes approaches like fact-checking, consistency checking, and probing the model's knowledge and reasoning. The paper also explores architectural modifications and training techniques that could make LLMs more resistant to hallucination.
Experiments are presented demonstrating the effectiveness of these methods in identifying and correcting hallucinated content. The results highlight the challenges in building fully trustworthy AI systems, as even state-of-the-art LLMs remain vulnerable to producing misinformation in certain contexts.
Critical Analysis
The paper provides a valuable exploration of an important issue facing the deployment of large language models in real-world applications. The authors rightly point out that while these models are remarkably capable, their ability to generate plausible-sounding but factually incorrect information poses significant risks.
One limitation of the research is that it primarily focuses on detection and mitigation strategies, without delving deeply into the underlying causes of hallucination. A more comprehensive understanding of the factors that lead LLMs to produce misinformation could inform even more effective countermeasures.
Additionally, the paper does not address the broader societal implications of LLM-generated misinformation. As these models become more widely used, there is a pressing need to consider the potential downstream consequences and develop holistic frameworks for ensuring the responsible deployment of such powerful technologies.
Overall, the research represents an important step in the ongoing effort to build trustworthy AI systems. Continued work in this area, combined with a broader focus on the ethical and societal considerations, will be crucial as large language models become increasingly ubiquitous.
Conclusion
This paper highlights the vulnerability of large language models to hallucination, the generation of plausible-sounding but factually incorrect information. It explores strategies for detecting and mitigating this issue, underscoring the challenges in building truly trustworthy AI systems.
The findings suggest that while LLMs are remarkably capable, their potential to produce misinformation poses significant risks that must be addressed. Ongoing research and development efforts focused on improving the factual grounding and reliability of these models will be crucial as they become more widely deployed in real-world applications.
Ultimately, the work presented in this paper represents an important step towards realizing the full potential of large language models while ensuring the information they generate can be trusted. Continued advancements in this field, combined with a broader consideration of the ethical and societal implications, will be essential for the responsible development of AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Misinforming LLMs: vulnerabilities, challenges and opportunities
Bo Zhou, Daniel Gei{ss}ler, Paul Lukowicz
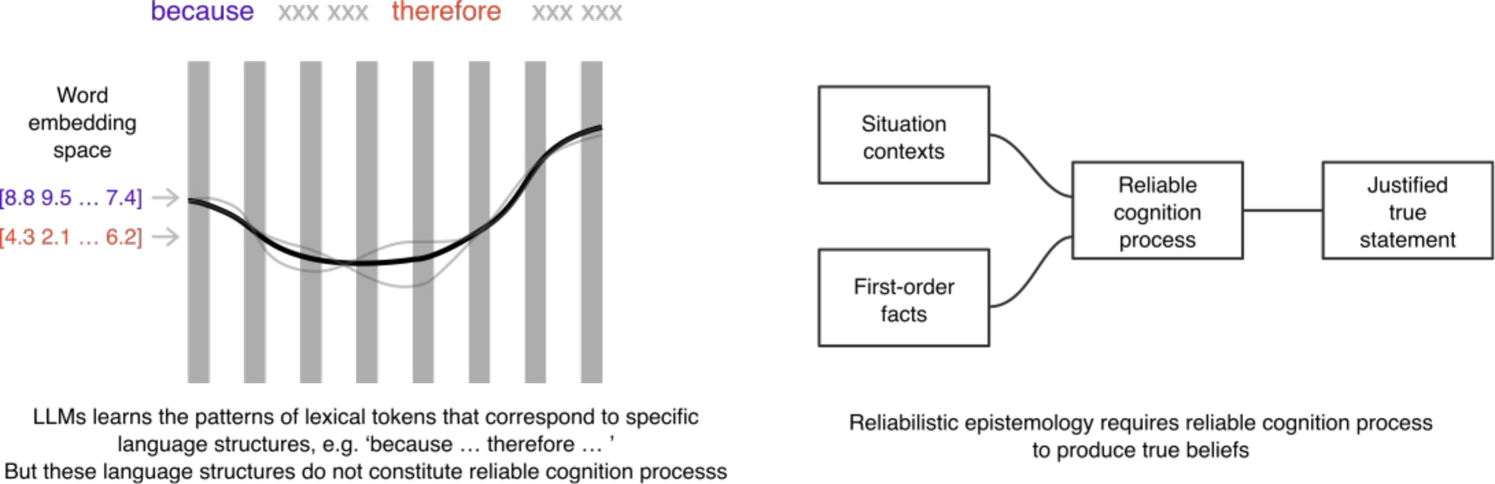
Large Language Models (LLMs) have made significant advances in natural language processing, but their underlying mechanisms are often misunderstood. Despite exhibiting coherent answers and apparent reasoning behaviors, LLMs rely on statistical patterns in word embeddings rather than true cognitive processes. This leads to vulnerabilities such as hallucination and misinformation. The paper argues that current LLM architectures are inherently untrustworthy due to their reliance on correlations of sequential patterns of word embedding vectors. However, ongoing research into combining generative transformer-based models with fact bases and logic programming languages may lead to the development of trustworthy LLMs capable of generating statements based on given truth and explaining their self-reasoning process.
Read more8/6/2024

0
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Sara Abdali, Jia He, CJ Barberan, Richard Anarfi
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including Model Editing which aims at modifying LLMs behavior, and Chroma Teaming which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Read more7/31/2024
💬
0
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
Read more4/3/2024
0
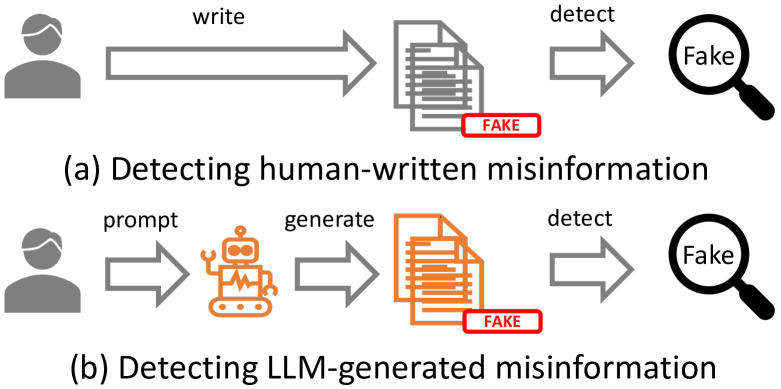
Can LLM-Generated Misinformation Be Detected?
Canyu Chen, Kai Shu
The advent of Large Language Models (LLMs) has made a transformative impact. However, the potential that LLMs such as ChatGPT can be exploited to generate misinformation has posed a serious concern to online safety and public trust. A fundamental research question is: will LLM-generated misinformation cause more harm than human-written misinformation? We propose to tackle this question from the perspective of detection difficulty. We first build a taxonomy of LLM-generated misinformation. Then we categorize and validate the potential real-world methods for generating misinformation with LLMs. Then, through extensive empirical investigation, we discover that LLM-generated misinformation can be harder to detect for humans and detectors compared to human-written misinformation with the same semantics, which suggests it can have more deceptive styles and potentially cause more harm. We also discuss the implications of our discovery on combating misinformation in the age of LLMs and the countermeasures.
Read more4/16/2024