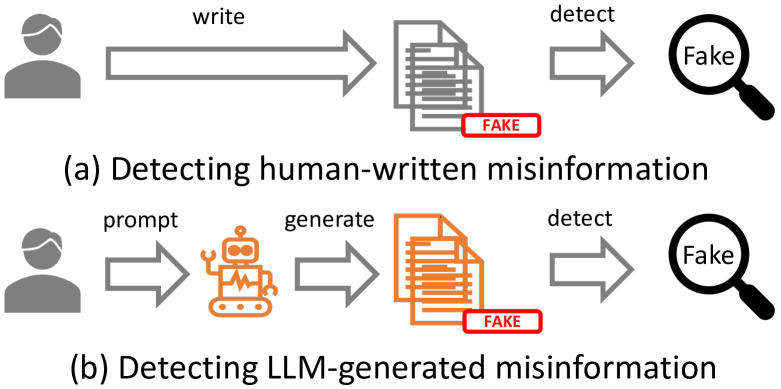
Can LLM-Generated Misinformation Be Detected?
2309.13788
0
0
Abstract
The advent of Large Language Models (LLMs) has made a transformative impact. However, the potential that LLMs such as ChatGPT can be exploited to generate misinformation has posed a serious concern to online safety and public trust. A fundamental research question is: will LLM-generated misinformation cause more harm than human-written misinformation? We propose to tackle this question from the perspective of detection difficulty. We first build a taxonomy of LLM-generated misinformation. Then we categorize and validate the potential real-world methods for generating misinformation with LLMs. Then, through extensive empirical investigation, we discover that LLM-generated misinformation can be harder to detect for humans and detectors compared to human-written misinformation with the same semantics, which suggests it can have more deceptive styles and potentially cause more harm. We also discuss the implications of our discovery on combating misinformation in the age of LLMs and the countermeasures.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
This research paper explores the challenge of detecting misinformation generated by large language models (LLMs) like ChatGPT. As these models become more advanced, there is growing concern about their potential to create false or misleading content that can be difficult to distinguish from genuine information. The paper aims to provide a taxonomy of different types of LLM-generated misinformation and discuss strategies for identifying and addressing this emerging threat.
Taxonomy of LLM-Generated Misinformation
Types:
- Factual errors: LLMs can generate content that includes incorrect facts or statements that are inconsistent with reality.
- Biased or one-sided perspectives: LLMs may produce content that presents a biased or limited view on a topic, potentially omitting important context or alternative viewpoints.
- Fake persona: LLMs can be used to create content that appears to be written by a real person or entity, when in fact it is generated by the model.
- Deepfakes: LLMs can be used to generate synthetic media, such as audio or video, that appears to depict real people saying or doing things they did not actually do.
Domains:
The paper discusses the potential for LLM-generated misinformation to appear in a variety of domains, including news articles, social media posts, and even academic or scientific papers. The authors emphasize the need for proactive measures to address this issue across these different contexts.
Plain English Explanation
Large language models (LLMs) like ChatGPT are incredibly powerful AI systems that can generate human-like text on a wide range of topics. While these models have many beneficial applications, they also have the potential to create false or misleading information that can be hard to detect.
The researchers in this paper provide a way to think about the different types of misinformation that LLMs can produce. For example, the models might generate content with factual errors, present biased or one-sided perspectives, create content that appears to be written by a real person (but isn't), or even produce synthetic media like fake videos or audio. These different types of misinformation can show up in news articles, social media, and even academic papers.
The key challenge is that LLM-generated misinformation can be very convincing and difficult to distinguish from genuine information. This is a serious concern, as the spread of false or misleading content can have significant negative impacts on individuals and society. The researchers emphasize the need for proactive measures to address this issue and find ways to reliably detect LLM-generated misinformation across various contexts.
Technical Explanation
The paper first outlines a taxonomy of different types of LLM-generated misinformation, including:
- Factual errors: LLMs can generate content that includes incorrect facts or statements that are inconsistent with reality.
- Biased or one-sided perspectives: LLMs may produce content that presents a biased or limited view on a topic, potentially omitting important context or alternative viewpoints.
- Fake persona: LLMs can be used to create content that appears to be written by a real person or entity, when in fact it is generated by the model.
- Deepfakes: LLMs can be used to generate synthetic media, such as audio or video, that appears to depict real people saying or doing things they did not actually do.
The paper then discusses the potential for these different types of LLM-generated misinformation to appear in a variety of domains, including news articles, social media posts, and academic or scientific papers. The authors emphasize the need for proactive measures to address this issue across these different contexts.
Critical Analysis
The paper provides a valuable framework for understanding the various ways in which LLM-generated misinformation can manifest, which is an important first step in developing effective detection and mitigation strategies. However, the paper does not delve into the specific technical challenges involved in reliably identifying LLM-generated content, nor does it propose concrete solutions or evaluation methods.
Additionally, the paper does not address the potential ethical and societal implications of LLM-generated misinformation, such as the impact on public discourse, political decision-making, or individual well-being. Further research and discussion in these areas would be valuable to provide a more holistic understanding of the problem and its potential consequences.
Conclusion
This research paper highlights the pressing challenge of detecting misinformation generated by large language models like ChatGPT. By outlining a taxonomy of different types of LLM-generated misinformation and discussing their potential to appear in various domains, the authors lay the groundwork for developing more effective detection and mitigation strategies. As these models continue to advance, the need for robust solutions to address the spread of false or misleading content becomes increasingly urgent, both for the integrity of information ecosystems and the well-being of individuals and society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Exploring the Potential of the Large Language Models (LLMs) in Identifying Misleading News Headlines
Md Main Uddin Rony, Md Mahfuzul Haque, Mohammad Ali, Ahmed Shatil Alam, Naeemul Hassan
0
0
In the digital age, the prevalence of misleading news headlines poses a significant challenge to information integrity, necessitating robust detection mechanisms. This study explores the efficacy of Large Language Models (LLMs) in identifying misleading versus non-misleading news headlines. Utilizing a dataset of 60 articles, sourced from both reputable and questionable outlets across health, science & tech, and business domains, we employ three LLMs- ChatGPT-3.5, ChatGPT-4, and Gemini-for classification. Our analysis reveals significant variance in model performance, with ChatGPT-4 demonstrating superior accuracy, especially in cases with unanimous annotator agreement on misleading headlines. The study emphasizes the importance of human-centered evaluation in developing LLMs that can navigate the complexities of misinformation detection, aligning technical proficiency with nuanced human judgment. Our findings contribute to the discourse on AI ethics, emphasizing the need for models that are not only technically advanced but also ethically aligned and sensitive to the subtleties of human interpretation.
5/7/2024
🔎
Adapting Fake News Detection to the Era of Large Language Models
Jinyan Su, Claire Cardie, Preslav Nakov
0
0
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
4/16/2024
🎲
A Survey on LLM-Generated Text Detection: Necessity, Methods, and Future Directions
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Derek F. Wong, Lidia S. Chao
0
0
The powerful ability to understand, follow, and generate complex language emerging from large language models (LLMs) makes LLM-generated text flood many areas of our daily lives at an incredible speed and is widely accepted by humans. As LLMs continue to expand, there is an imperative need to develop detectors that can detect LLM-generated text. This is crucial to mitigate potential misuse of LLMs and safeguard realms like artistic expression and social networks from harmful influence of LLM-generated content. The LLM-generated text detection aims to discern if a piece of text was produced by an LLM, which is essentially a binary classification task. The detector techniques have witnessed notable advancements recently, propelled by innovations in watermarking techniques, statistics-based detectors, neural-base detectors, and human-assisted methods. In this survey, we collate recent research breakthroughs in this area and underscore the pressing need to bolster detector research. We also delve into prevalent datasets, elucidating their limitations and developmental requirements. Furthermore, we analyze various LLM-generated text detection paradigms, shedding light on challenges like out-of-distribution problems, potential attacks, real-world data issues and the lack of effective evaluation framework. Conclusively, we highlight interesting directions for future research in LLM-generated text detection to advance the implementation of responsible artificial intelligence (AI). Our aim with this survey is to provide a clear and comprehensive introduction for newcomers while also offering seasoned researchers a valuable update in the field of LLM-generated text detection. The useful resources are publicly available at: https://github.com/NLP2CT/LLM-generated-Text-Detection.
4/22/2024
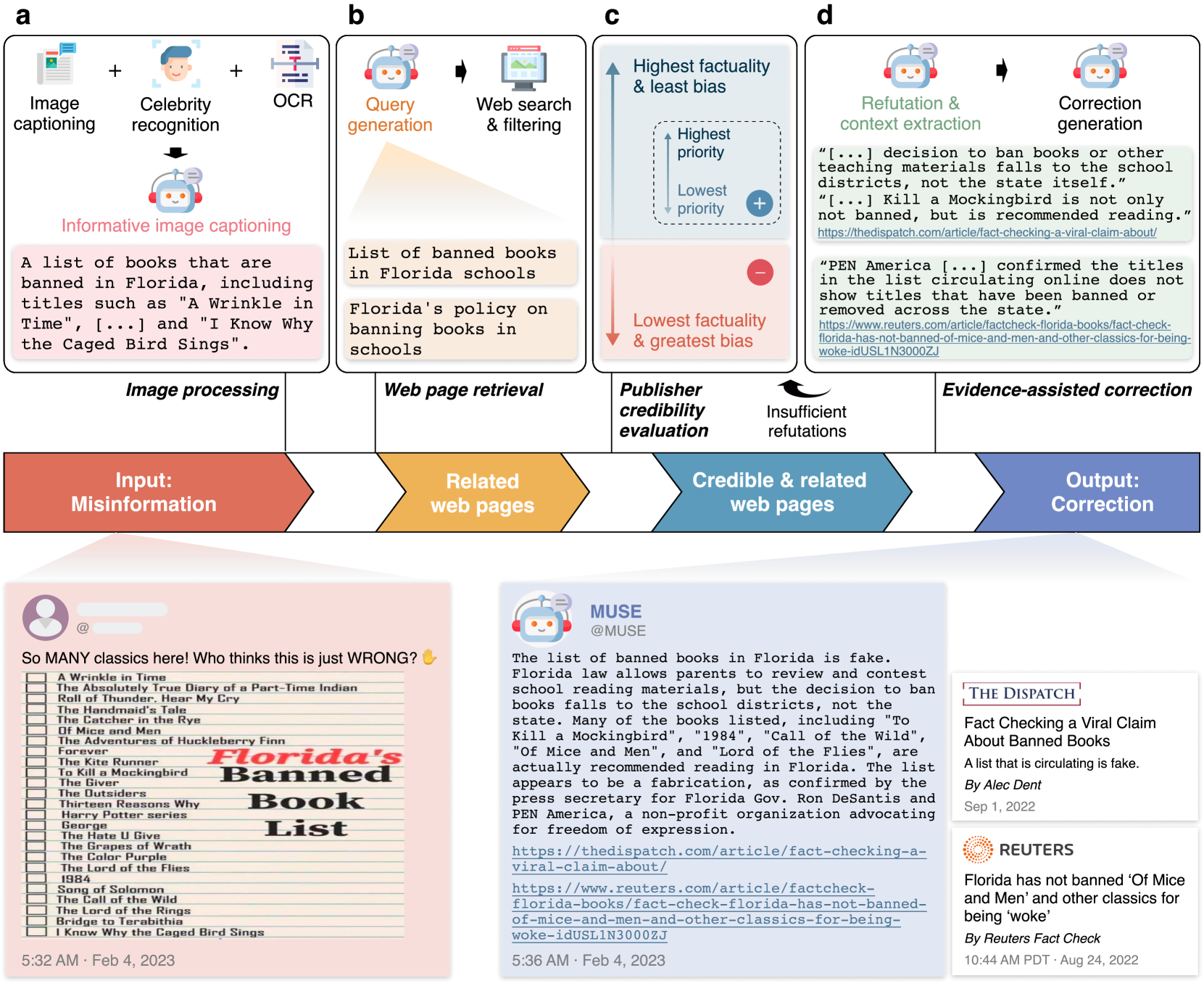
Correcting misinformation on social media with a large language model
Xinyi Zhou, Ashish Sharma, Amy X. Zhang, Tim Althoff
0
0
Real-world misinformation can be partially correct and even factual but misleading. It undermines public trust in science and democracy, particularly on social media, where it can spread rapidly. High-quality and timely correction of misinformation that identifies and explains its (in)accuracies has been shown to effectively reduce false beliefs. Despite the wide acceptance of manual correction, it is difficult to be timely and scalable, a concern as technologies like large language models (LLMs) make misinformation easier to produce. LLMs also have versatile capabilities that could accelerate misinformation correction-however, they struggle due to a lack of recent information, a tendency to produce false content, and limitations in addressing multimodal information. We propose MUSE, an LLM augmented with access to and credibility evaluation of up-to-date information. By retrieving evidence as refutations or contexts, MUSE identifies and explains (in)accuracies in a piece of content-not presupposed to be misinformation-with references. It also describes images and conducts multimodal searches to verify and correct multimodal content. Fact-checking experts evaluate responses to social media content that are not presupposed to be (non-)misinformation but broadly include incorrect, partially correct, and correct posts, that may or may not be misleading. We propose and evaluate 13 dimensions of misinformation correction quality, ranging from the accuracy of identifications and factuality of explanations to the relevance and credibility of references. The results demonstrate MUSE's ability to promptly write high-quality responses to potential misinformation on social media-overall, MUSE outperforms GPT-4 by 37% and even high-quality responses from laypeople by 29%. This work reveals LLMs' potential to help combat real-world misinformation effectively and efficiently.
5/2/2024