Correcting misinformation on social media with a large language model
2403.11169
2
0
Abstract
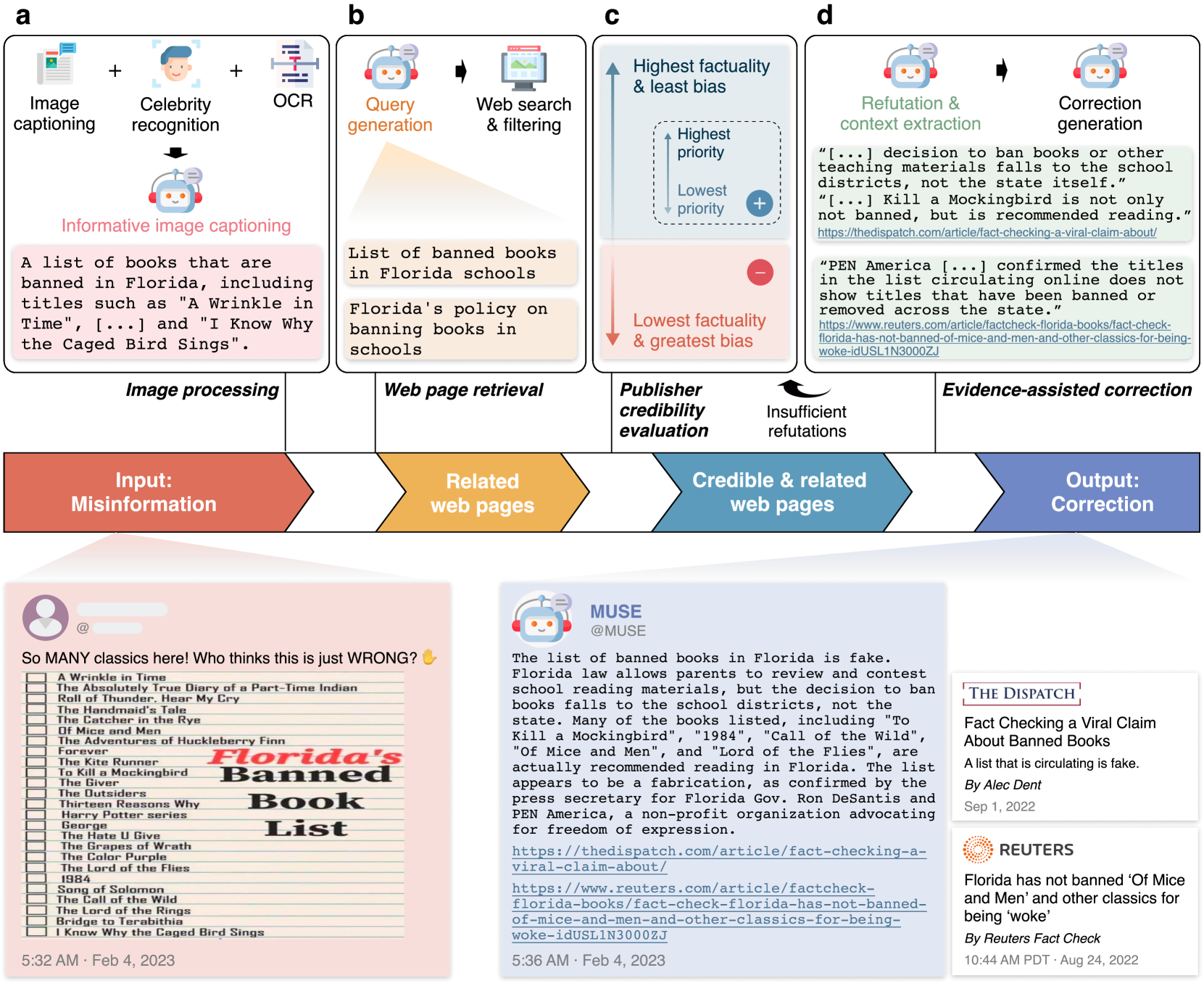
Real-world misinformation can be partially correct and even factual but misleading. It undermines public trust in science and democracy, particularly on social media, where it can spread rapidly. High-quality and timely correction of misinformation that identifies and explains its (in)accuracies has been shown to effectively reduce false beliefs. Despite the wide acceptance of manual correction, it is difficult to be timely and scalable, a concern as technologies like large language models (LLMs) make misinformation easier to produce. LLMs also have versatile capabilities that could accelerate misinformation correction-however, they struggle due to a lack of recent information, a tendency to produce false content, and limitations in addressing multimodal information. We propose MUSE, an LLM augmented with access to and credibility evaluation of up-to-date information. By retrieving evidence as refutations or contexts, MUSE identifies and explains (in)accuracies in a piece of content-not presupposed to be misinformation-with references. It also describes images and conducts multimodal searches to verify and correct multimodal content. Fact-checking experts evaluate responses to social media content that are not presupposed to be (non-)misinformation but broadly include incorrect, partially correct, and correct posts, that may or may not be misleading. We propose and evaluate 13 dimensions of misinformation correction quality, ranging from the accuracy of identifications and factuality of explanations to the relevance and credibility of references. The results demonstrate MUSE's ability to promptly write high-quality responses to potential misinformation on social media-overall, MUSE outperforms GPT-4 by 37% and even high-quality responses from laypeople by 29%. This work reveals LLMs' potential to help combat real-world misinformation effectively and efficiently.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of large language models (LLMs) to help combat the spread of misinformation on social media.
- The researchers investigate how LLMs can be leveraged to automatically detect and correct false claims, as well as provide contextual information to users.
- The work builds on recent advancements in interpretable detection of out-of-context misinformation and teaching LLMs to interpret information.
Plain English Explanation
Social media platforms have become breeding grounds for the rapid spread of misinformation, with false claims and misleading narratives often going viral. This can have serious consequences, leading to confusion, distrust, and even real-world harm.
To address this issue, the researchers in this paper explored how powerful language models, known as large language models (LLMs), could be harnessed to automatically identify and correct misinformation on social media. LLMs are AI systems that have been trained on vast amounts of text data, giving them a deep understanding of language and the ability to generate human-like responses.
The key idea is to leverage the capabilities of LLMs to quickly analyze social media posts, detect the presence of false claims or misleading information, and then provide users with accurate, contextual information to counter the misinformation. This could help prevent the spread of misinformation and ensure that people have access to reliable, fact-based information.
The researchers built on recent advancements in the field, such as interpretable detection of out-of-context misinformation and teaching LLMs to interpret information. By combining these techniques, the team aimed to create a system that could effectively identify and correct misinformation in a transparent and understandable way.
Technical Explanation
The researchers proposed a system that leverages large language models (LLMs) to automatically detect and correct misinformation on social media. The key components of their approach include:
-
Misinformation Detection: The system uses an LLM to analyze the content of social media posts, searching for the presence of false claims or misleading information. This is done through a combination of natural language processing techniques and knowledge-based reasoning.
-
Contextual Information Retrieval: When misinformation is detected, the system retrieves relevant, factual information from reliable sources to provide context and counter the false claims. This is accomplished by querying the LLM with the detected misinformation and retrieving the most appropriate response.
-
Presentation to Users: The corrected information is then presented to users in an intuitive and user-friendly way, such as through inline annotations or pop-up notifications. The goal is to ensure that users have access to accurate, verified information without disrupting their browsing experience.
The researchers conducted experiments to evaluate the effectiveness of their approach in identifying and correcting misinformation on social media. They found that the LLM-based system was able to accurately detect a wide range of false claims and provide relevant, factual information to counter them.
Critical Analysis
The researchers have presented a promising approach to leveraging large language models to combat the spread of misinformation on social media. However, there are a few potential limitations and areas for further research that should be considered:
-
Scalability and Deployment Challenges: While the system demonstrated strong performance in the controlled experiments, scaling it to handle the vast amount of content on social media platforms may present significant technical and computational challenges. The researchers would need to address issues such as real-time processing, maintaining up-to-date knowledge bases, and ensuring seamless integration with social media platforms.
-
Bias and Reliability Concerns: Like any AI system, the LLM-based approach may be prone to biases or errors, particularly when dealing with complex, contextual information. The researchers would need to carefully evaluate the reliability and trustworthiness of the system's outputs, especially when correcting claims made by medical professionals.
-
User Acceptance and Privacy Implications: The successful implementation of such a system would depend on user acceptance and trust. Concerns around privacy, data usage, and potential censorship may arise, and the researchers would need to address these issues thoughtfully.
-
Evolving Misinformation Tactics: As misinformation creators become more sophisticated, they may adapt their tactics to evade detection or manipulation. The researchers would need to continuously monitor and update their system to keep pace with these evolving threats.
Despite these potential challenges, the researchers' approach represents a important step towards leveraging the capabilities of large language models to combat the spread of misinformation. Continued research and collaboration with social media platforms, policymakers, and the broader community will be crucial in turning this promising concept into a reliable, effective, and widely-adopted solution.
Conclusion
This paper explores a novel approach to using large language models (LLMs) to detect and correct misinformation on social media. By leveraging the powerful natural language processing capabilities of LLMs, the researchers have developed a system that can automatically identify false claims and provide users with accurate, contextual information to counter them.
The proposed solution has the potential to significantly impact the fight against the rapid spread of misinformation, which has become a major challenge in the digital age. By empowering users with reliable, fact-based information, this technology could help restore trust, reduce confusion, and prevent the real-world consequences of the spread of false narratives.
While the research has shown promising results, there are still important challenges to address, such as scalability, reliability, and user acceptance. Continued innovation and collaboration between researchers, tech companies, policymakers, and the broader community will be crucial in turning this concept into a widely-adopted and effective solution for combating misinformation on social media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multimodal Large Language Models to Support Real-World Fact-Checking
Jiahui Geng, Yova Kementchedjhieva, Preslav Nakov, Iryna Gurevych
0
0
Multimodal large language models (MLLMs) carry the potential to support humans in processing vast amounts of information. While MLLMs are already being used as a fact-checking tool, their abilities and limitations in this regard are understudied. Here is aim to bridge this gap. In particular, we propose a framework for systematically assessing the capacity of current multimodal models to facilitate real-world fact-checking. Our methodology is evidence-free, leveraging only these models' intrinsic knowledge and reasoning capabilities. By designing prompts that extract models' predictions, explanations, and confidence levels, we delve into research questions concerning model accuracy, robustness, and reasons for failure. We empirically find that (1) GPT-4V exhibits superior performance in identifying malicious and misleading multimodal claims, with the ability to explain the unreasonable aspects and underlying motives, and (2) existing open-source models exhibit strong biases and are highly sensitive to the prompt. Our study offers insights into combating false multimodal information and building secure, trustworthy multimodal models. To the best of our knowledge, we are the first to evaluate MLLMs for real-world fact-checking.
4/29/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024
Can LLM-Generated Misinformation Be Detected?
Canyu Chen, Kai Shu
0
0
The advent of Large Language Models (LLMs) has made a transformative impact. However, the potential that LLMs such as ChatGPT can be exploited to generate misinformation has posed a serious concern to online safety and public trust. A fundamental research question is: will LLM-generated misinformation cause more harm than human-written misinformation? We propose to tackle this question from the perspective of detection difficulty. We first build a taxonomy of LLM-generated misinformation. Then we categorize and validate the potential real-world methods for generating misinformation with LLMs. Then, through extensive empirical investigation, we discover that LLM-generated misinformation can be harder to detect for humans and detectors compared to human-written misinformation with the same semantics, which suggests it can have more deceptive styles and potentially cause more harm. We also discuss the implications of our discovery on combating misinformation in the age of LLMs and the countermeasures.
4/16/2024
💬
Rumour Evaluation with Very Large Language Models
Dahlia Shehata, Robin Cohen, Charles Clarke
0
0
Conversational prompt-engineering-based large language models (LLMs) have enabled targeted control over the output creation, enhancing versatility, adaptability and adhoc retrieval. From another perspective, digital misinformation has reached alarming levels. The anonymity, availability and reach of social media offer fertile ground for rumours to propagate. This work proposes to leverage the advancement of prompting-dependent LLMs to combat misinformation by extending the research efforts of the RumourEval task on its Twitter dataset. To the end, we employ two prompting-based LLM variants (GPT-3.5-turbo and GPT-4) to extend the two RumourEval subtasks: (1) veracity prediction, and (2) stance classification. For veracity prediction, three classifications schemes are experimented per GPT variant. Each scheme is tested in zero-, one- and few-shot settings. Our best results outperform the precedent ones by a substantial margin. For stance classification, prompting-based-approaches show comparable performance to prior results, with no improvement over finetuning methods. Rumour stance subtask is also extended beyond the original setting to allow multiclass classification. All of the generated predictions for both subtasks are equipped with confidence scores determining their trustworthiness degree according to the LLM, and post-hoc justifications for explainability and interpretability purposes. Our primary aim is AI for social good.
4/29/2024