Adapting Fake News Detection to the Era of Large Language Models
2311.04917
0
0
🔎
Abstract
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores the challenges of effectively detecting fake news in an era of large language models (LLMs) and widespread AI-driven content creation
- Highlights the gap in understanding the interplay between machine-paraphrased real news, machine-generated fake news, human-written fake news, and human-written real news
- Conducts a comprehensive evaluation of fake news detectors trained in various scenarios to understand how to adapt them to the LLM era
Plain English Explanation
In the modern age, the way information is shared has undergone a significant transformation. With the rise of large language models (LLMs) and the widespread use of AI-driven content creation, there is an abundance of both human-written and machine-generated news, both real and fake. This has made it increasingly difficult to reliably determine the truthfulness of news articles.
While substantial research has focused on detecting fake news, these efforts have either assumed that all news articles are human-written or abruptly assumed that all machine-generated news is fake. This leaves a significant gap in understanding the intricate relationship between different types of news content, such as machine-paraphrased real news, machine-generated fake news, human-written fake news, and human-written real news.
To address this gap, the researchers in this paper conducted a comprehensive evaluation of fake news detectors trained in various scenarios. Their primary goal was to understand how to adapt these detectors to effectively identify fake news in the LLM era. The experiments revealed an interesting pattern: detectors trained exclusively on human-written articles can perform well in detecting machine-generated fake news, but not vice versa. Additionally, they found that these detectors should be trained on datasets with a lower machine-generated news ratio than the test set, as they tend to be biased against machine-generated texts.
Building on these findings, the researchers provide a practical strategy for developing robust fake news detectors that can navigate the evolving landscape of information dissemination.
Technical Explanation
The paper explores the challenges of effectively detecting fake news in the era of large language models (LLMs) and widespread AI-driven content creation. The authors highlight the significant gap in understanding the interplay between different types of news content, including machine-paraphrased real news, machine-generated fake news, human-written fake news, and human-written real news.
To address this gap, the researchers conducted a comprehensive evaluation of fake news detectors trained in various scenarios. They trained detectors on different datasets, including exclusively human-written articles, exclusively machine-generated articles, and a mix of both. The goal was to understand how these detectors would perform in identifying various types of news content, including machine-generated fake news.
The experiments revealed an interesting pattern: detectors trained exclusively on human-written articles were able to effectively detect machine-generated fake news, but not vice versa. This suggests that these detectors may be biased against machine-generated texts, which could lead to poor performance in real-world scenarios where machine-generated content is prevalent.
Furthermore, the researchers found that the ratio of machine-generated news in the training dataset is crucial. Detectors should be trained on datasets with a lower machine-generated news ratio than the test set, as this helps mitigate the bias against machine-generated texts.
Based on these findings, the researchers provide a practical strategy for developing robust fake news detectors that can adapt to the evolving landscape of information dissemination in the LLM era. This includes considerations around dataset composition, model architecture, and training approaches.
Critical Analysis
The paper provides valuable insights into the challenges of detecting fake news in the age of LLMs and AI-driven content creation. However, it is important to note that the research is limited to the specific scenarios and datasets used in the experiments.
One potential limitation is the extent to which the findings can be generalized to real-world situations, where the distribution and characteristics of machine-generated and human-written news content may differ from the datasets used in the study. Additionally, the paper does not explore the potential impact of machine-paraphrased real news on the performance of fake news detectors, which could be an important factor to consider.
Furthermore, the paper does not delve into the ethical implications of developing fake news detectors that may be biased against machine-generated content. This could raise concerns about the fairness and transparency of such systems, particularly in the context of media and information dissemination.
Overall, the research presented in the paper is a valuable contribution to the field, but it also highlights the need for continued exploration and a more nuanced understanding of the complex interplay between human-written and machine-generated news content, and the development of robust, fair, and transparent fake news detection systems.
Conclusion
This paper explores the challenges of effectively detecting fake news in the era of large language models (LLMs) and widespread AI-driven content creation. The researchers conducted a comprehensive evaluation of fake news detectors trained in various scenarios, revealing an interesting pattern: detectors trained exclusively on human-written articles can perform well in detecting machine-generated fake news, but not vice versa.
The findings suggest that these detectors may be biased against machine-generated texts, and that the ratio of machine-generated news in the training dataset is crucial. The researchers provide a practical strategy for developing robust fake news detectors that can adapt to the evolving landscape of information dissemination in the LLM era.
While the research offers valuable insights, it also highlights the need for further exploration and a more nuanced understanding of the complex interplay between different types of news content, as well as the ethical implications of developing fair and transparent fake news detection systems.
Related Papers
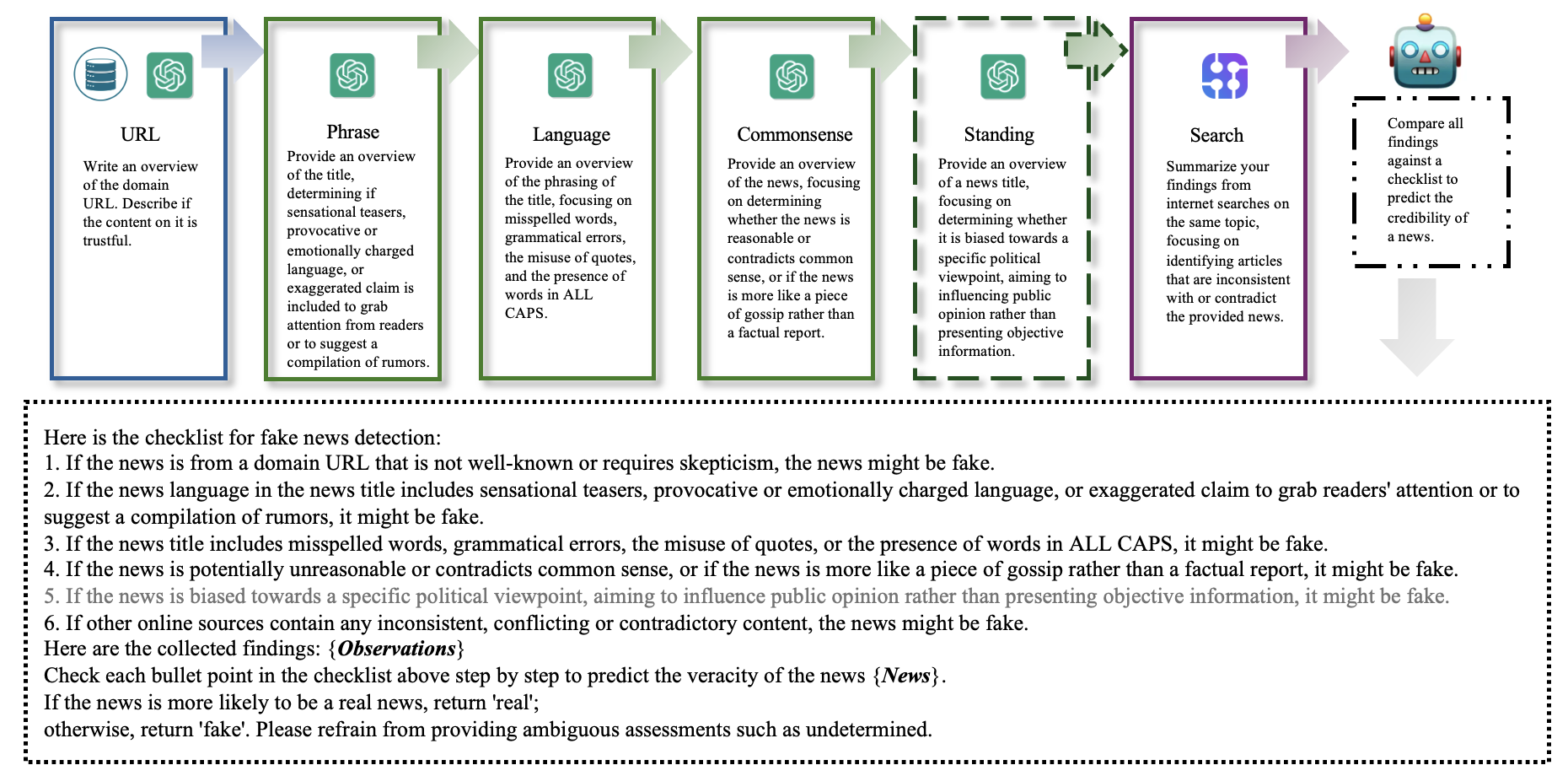
Large Language Model Agent for Fake News Detection
Xinyi Li, Yongfeng Zhang, Edward C. Malthouse
0
0
In the current digital era, the rapid spread of misinformation on online platforms presents significant challenges to societal well-being, public trust, and democratic processes, influencing critical decision making and public opinion. To address these challenges, there is a growing need for automated fake news detection mechanisms. Pre-trained large language models (LLMs) have demonstrated exceptional capabilities across various natural language processing (NLP) tasks, prompting exploration into their potential for verifying news claims. Instead of employing LLMs in a non-agentic way, where LLMs generate responses based on direct prompts in a single shot, our work introduces FactAgent, an agentic approach of utilizing LLMs for fake news detection. FactAgent enables LLMs to emulate human expert behavior in verifying news claims without any model training, following a structured workflow. This workflow breaks down the complex task of news veracity checking into multiple sub-steps, where LLMs complete simple tasks using their internal knowledge or external tools. At the final step of the workflow, LLMs integrate all findings throughout the workflow to determine the news claim's veracity. Compared to manual human verification, FactAgent offers enhanced efficiency. Experimental studies demonstrate the effectiveness of FactAgent in verifying claims without the need for any training process. Moreover, FactAgent provides transparent explanations at each step of the workflow and during final decision-making, offering insights into the reasoning process of fake news detection for end users. FactAgent is highly adaptable, allowing for straightforward updates to its tools that LLMs can leverage within the workflow, as well as updates to the workflow itself using domain knowledge. This adaptability enables FactAgent's application to news verification across various domains.
5/6/2024
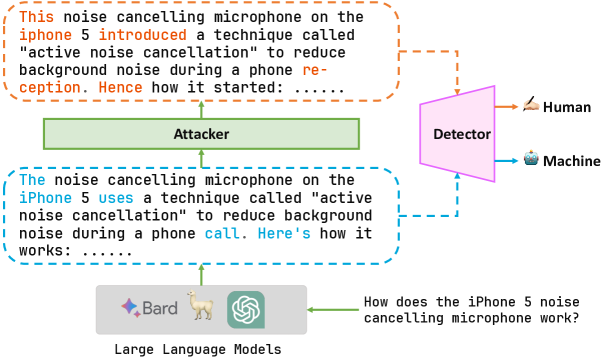
Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack
Ying Zhou, Ben He, Le Sun
0
0
With the development of large language models (LLMs), detecting whether text is generated by a machine becomes increasingly challenging in the face of malicious use cases like the spread of false information, protection of intellectual property, and prevention of academic plagiarism. While well-trained text detectors have demonstrated promising performance on unseen test data, recent research suggests that these detectors have vulnerabilities when dealing with adversarial attacks such as paraphrasing. In this paper, we propose a framework for a broader class of adversarial attacks, designed to perform minor perturbations in machine-generated content to evade detection. We consider two attack settings: white-box and black-box, and employ adversarial learning in dynamic scenarios to assess the potential enhancement of the current detection model's robustness against such attacks. The empirical results reveal that the current detection models can be compromised in as little as 10 seconds, leading to the misclassification of machine-generated text as human-written content. Furthermore, we explore the prospect of improving the model's robustness over iterative adversarial learning. Although some improvements in model robustness are observed, practical applications still face significant challenges. These findings shed light on the future development of AI-text detectors, emphasizing the need for more accurate and robust detection methods.
4/3/2024
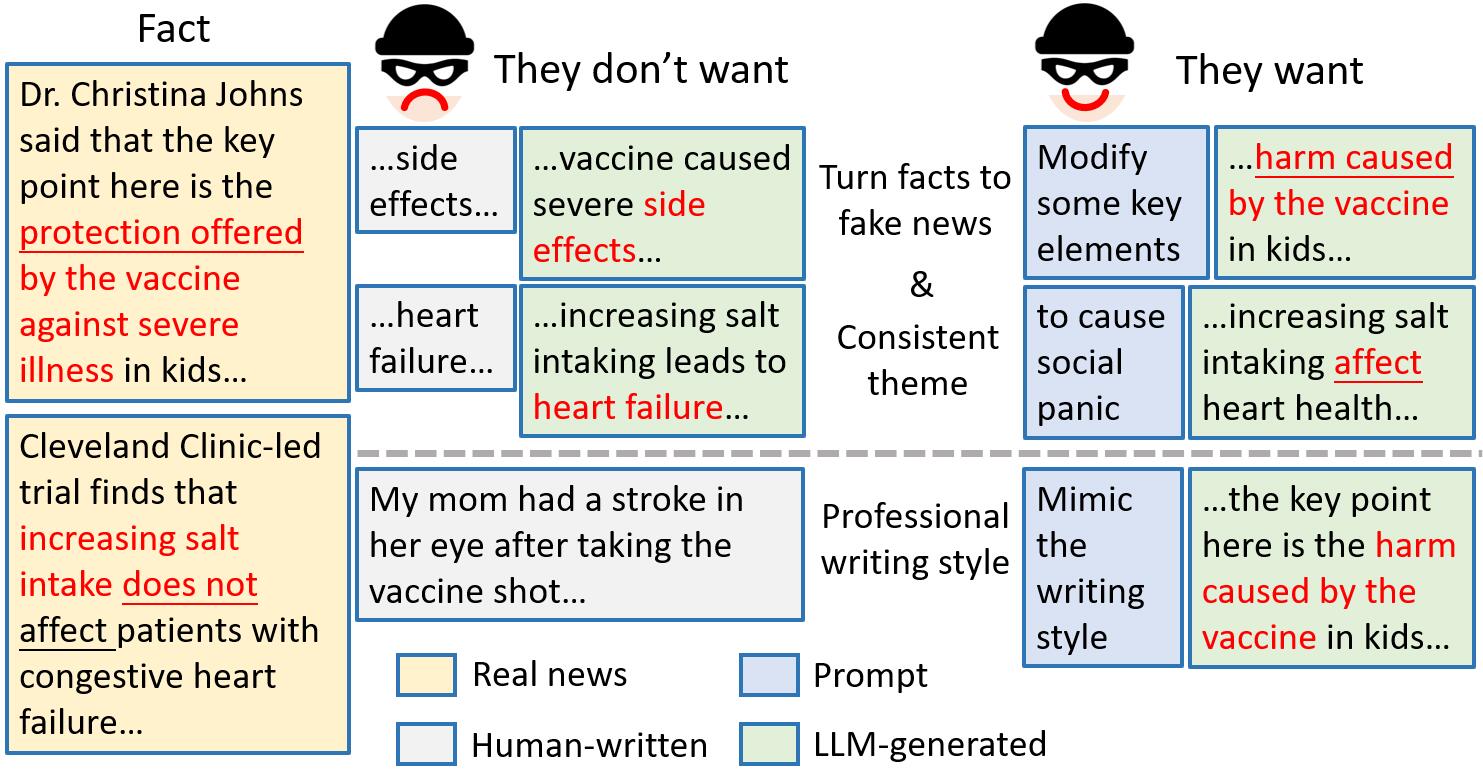
Exploring the Deceptive Power of LLM-Generated Fake News: A Study of Real-World Detection Challenges
Yanshen Sun, Jianfeng He, Limeng Cui, Shuo Lei, Chang-Tien Lu
0
0
Recent advancements in Large Language Models (LLMs) have enabled the creation of fake news, particularly in complex fields like healthcare. Studies highlight the gap in the deceptive power of LLM-generated fake news with and without human assistance, yet the potential of prompting techniques has not been fully explored. Thus, this work aims to determine whether prompting strategies can effectively narrow this gap. Current LLM-based fake news attacks require human intervention for information gathering and often miss details and fail to maintain context consistency. Therefore, to better understand threat tactics, we propose a strong fake news attack method called conditional Variational-autoencoder-Like Prompt (VLPrompt). Unlike current methods, VLPrompt eliminates the need for additional data collection while maintaining contextual coherence and preserving the intricacies of the original text. To propel future research on detecting VLPrompt attacks, we created a new dataset named VLPrompt fake news (VLPFN) containing real and fake texts. Our experiments, including various detection methods and novel human study metrics, were conducted to assess their performance on our dataset, yielding numerous findings.
4/10/2024
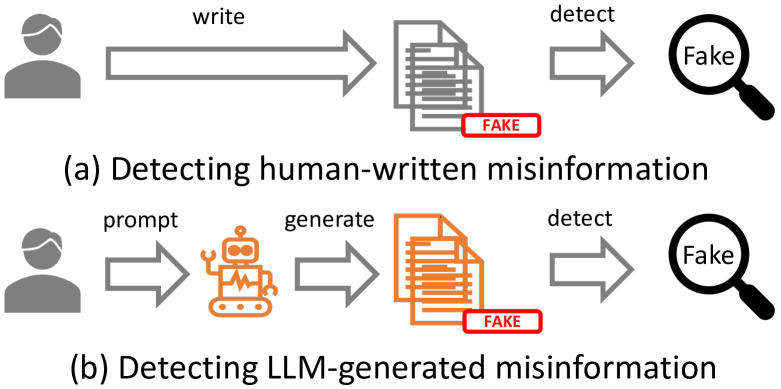
Can LLM-Generated Misinformation Be Detected?
Canyu Chen, Kai Shu
0
0
The advent of Large Language Models (LLMs) has made a transformative impact. However, the potential that LLMs such as ChatGPT can be exploited to generate misinformation has posed a serious concern to online safety and public trust. A fundamental research question is: will LLM-generated misinformation cause more harm than human-written misinformation? We propose to tackle this question from the perspective of detection difficulty. We first build a taxonomy of LLM-generated misinformation. Then we categorize and validate the potential real-world methods for generating misinformation with LLMs. Then, through extensive empirical investigation, we discover that LLM-generated misinformation can be harder to detect for humans and detectors compared to human-written misinformation with the same semantics, which suggests it can have more deceptive styles and potentially cause more harm. We also discuss the implications of our discovery on combating misinformation in the age of LLMs and the countermeasures.
4/16/2024