Can LLMs Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis

0
Sign in to get full access
Overview
- The paper explores whether large language models (LLMs) can generate human-like wayfinding instructions, which are step-by-step directions for navigating physical spaces.
- The researchers propose a platform-agnostic approach that combines an LLM with a vision-language model to extract and synthesize spatial knowledge for generating embodied instructions.
- The goal is to develop a system that can provide accessible, human-like navigation guidance across different environments and platforms.
Plain English Explanation
The researchers wanted to see if powerful language models, which are AI systems trained on massive amounts of text data, could generate clear, natural-sounding instructions for guiding people through physical spaces. Navigating unfamiliar environments can be challenging, especially for those with disabilities or limited mobility. The researchers believe an AI system that can provide human-like wayfinding instructions could make it easier for people to find their way around.
To do this, the researchers combined a language model with a vision-language model, which is an AI that can understand and process both text and images. The idea is that by using both language understanding and visual processing capabilities, the system can extract relevant spatial knowledge from its training data and then synthesize that into step-by-step navigation guidance that sounds like it was written by a person.
The researchers tested their approach in different virtual environments to see how well the instructions it generated matched the quality and style of instructions a human would provide. The goal is to develop a platform-agnostic system that can work across various navigation apps, assistive devices, and other technologies to make wayfinding more accessible and intuitive for everyone.
Technical Explanation
The paper presents a novel approach for generating human-like wayfinding instructions using large language models (LLMs) and vision-language models. The key components are:
-
Spatial Knowledge Extraction: The researchers use a pre-trained LLM (e.g. GPT-3) in combination with a vision-language model (BLIP) to extract relevant spatial and navigational knowledge from a large corpus of text and image data. This allows the system to build an understanding of concepts like landmarks, directions, and spatial relationships.
-
Instruction Synthesis: With the extracted spatial knowledge, the system can then generate step-by-step wayfinding instructions in natural language. This is done by fine-tuning the LLM on example human-written navigation instructions to learn the style and structure.
-
Platform Agnostic Design: The researchers designed their approach to be platform-agnostic, meaning the generated instructions can be adapted to various navigation interfaces and assistive technologies. This allows the system to provide accessible guidance across different environments and devices.
The researchers evaluated their approach in several simulated indoor and outdoor environments, comparing the generated instructions to human-written ones. The results showed their system was able to produce instructions rated as comparable in quality and naturalness to human-authored guidance.
Critical Analysis
The researchers acknowledge several limitations in their work. First, the system was only evaluated in simulated environments, so its performance in real-world settings remains to be tested. Additionally, the instructions were generated based on static images, while real-world navigation often involves dynamic, first-person perspectives.
Another potential issue is the reliance on pre-trained models, which can encode societal biases present in the original training data. This could result in instructions that are not fully inclusive or accessible. The paper does not deeply explore this concern.
Furthermore, the researchers note that their platform-agnostic approach still requires some manual effort to adapt the generated instructions for specific interfaces. Developing a truly seamless integration across navigation platforms remains an open challenge.
Despite these limitations, the core idea of combining language and vision models to synthesize human-like wayfinding instructions is promising. If further developed, this technology could significantly improve accessibility and independence for people navigating unfamiliar environments.
Conclusion
This paper presents an innovative approach to generating human-like wayfinding instructions using large language models and vision-language AI. By extracting spatial knowledge and leveraging natural language generation, the researchers have demonstrated the potential for AI-driven navigation guidance that is more accessible and intuitive compared to traditional systems.
While the current implementation has some limitations, the platform-agnostic design and promising evaluation results suggest this technology could have important real-world applications in making navigation easier and more inclusive for people with diverse needs and abilities. Further research is needed to refine the approach and validate its performance in real-world settings, but this work represents an important step towards more human-centric, AI-powered wayfinding solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can LLMs Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis
Vishnu Sashank Dorbala, Sanjoy Chowdhury, Dinesh Manocha
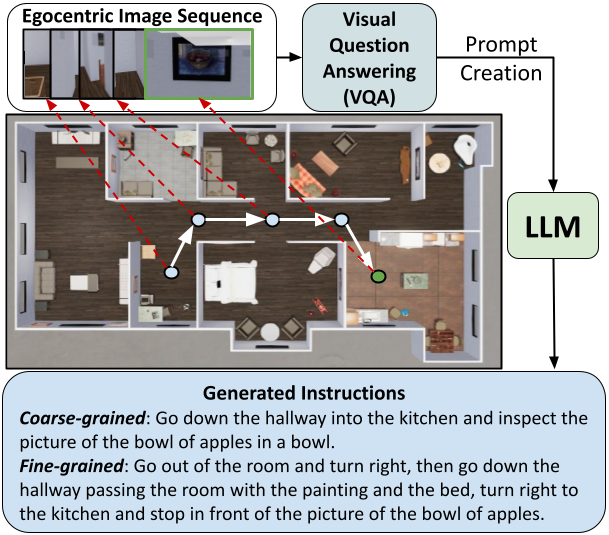
We present a novel approach to automatically synthesize wayfinding instructions for an embodied robot agent. In contrast to prior approaches that are heavily reliant on human-annotated datasets designed exclusively for specific simulation platforms, our algorithm uses in-context learning to condition an LLM to generate instructions using just a few references. Using an LLM-based Visual Question Answering strategy, we gather detailed information about the environment which is used by the LLM for instruction synthesis. We implement our approach on multiple simulation platforms including Matterport3D, AI Habitat and ThreeDWorld, thereby demonstrating its platform-agnostic nature. We subjectively evaluate our approach via a user study and observe that 83.3% of users find the synthesized instructions accurately capture the details of the environment and show characteristics similar to those of human-generated instructions. Further, we conduct zero-shot navigation with multiple approaches on the REVERIE dataset using the generated instructions, and observe very close correlation with the baseline on standard success metrics (< 1% change in SR), quantifying the viability of generated instructions in replacing human-annotated data. We finally discuss the applicability of our approach in enabling a generalizable evaluation of embodied navigation policies. To the best of our knowledge, ours is the first LLM-driven approach capable of generating human-like instructions in a platform-agnostic manner, without training.
Read more4/3/2024
0
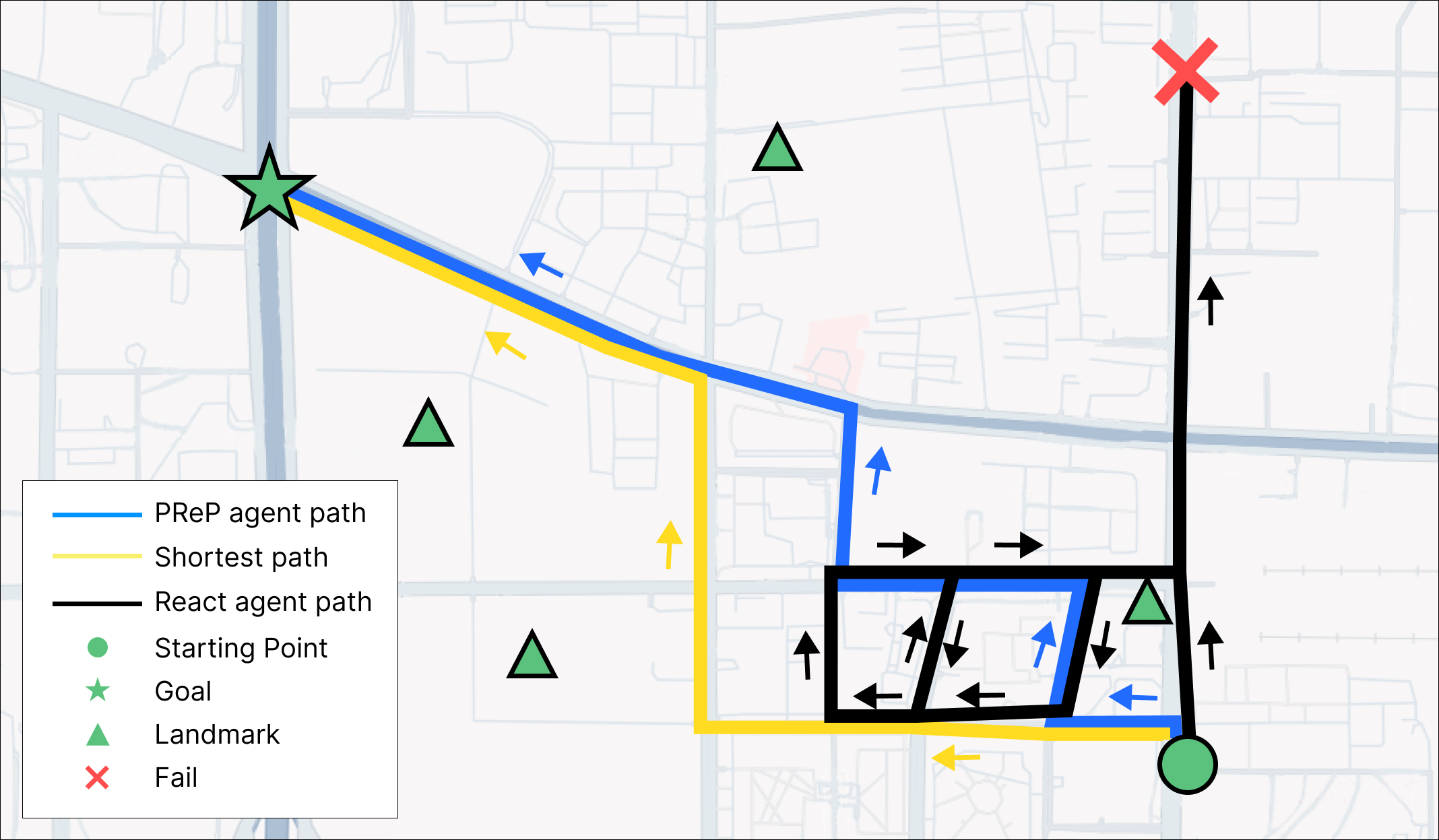
Perceive, Reflect, and Plan: Designing LLM Agent for Goal-Directed City Navigation without Instructions
Qingbin Zeng, Qinglong Yang, Shunan Dong, Heming Du, Liang Zheng, Fengli Xu, Yong Li
This paper considers a scenario in city navigation: an AI agent is provided with language descriptions of the goal location with respect to some well-known landmarks; By only observing the scene around, including recognizing landmarks and road network connections, the agent has to make decisions to navigate to the goal location without instructions. This problem is very challenging, because it requires agent to establish self-position and acquire spatial representation of complex urban environment, where landmarks are often invisible. In the absence of navigation instructions, such abilities are vital for the agent to make high-quality decisions in long-range city navigation. With the emergent reasoning ability of large language models (LLMs), a tempting baseline is to prompt LLMs to react on each observation and make decisions accordingly. However, this baseline has very poor performance that the agent often repeatedly visits same locations and make short-sighted, inconsistent decisions. To address these issues, this paper introduces a novel agentic workflow featured by its abilities to perceive, reflect and plan. Specifically, we find LLaVA-7B can be fine-tuned to perceive the direction and distance of landmarks with sufficient accuracy for city navigation. Moreover, reflection is achieved through a memory mechanism, where past experiences are stored and can be retrieved with current perception for effective decision argumentation. Planning uses reflection results to produce long-term plans, which can avoid short-sighted decisions in long-range navigation. We show the designed workflow significantly improves navigation ability of the LLM agent compared with the state-of-the-art baselines.
Read more9/6/2024

0
NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, Qi Wu
Capitalizing on the remarkable advancements in Large Language Models (LLMs), there is a burgeoning initiative to harness LLMs for instruction following robotic navigation. Such a trend underscores the potential of LLMs to generalize navigational reasoning and diverse language understanding. However, a significant discrepancy in agent performance is observed when integrating LLMs in the Vision-and-Language navigation (VLN) tasks compared to previous downstream specialist models. Furthermore, the inherent capacity of language to interpret and facilitate communication in agent interactions is often underutilized in these integrations. In this work, we strive to bridge the divide between VLN-specialized models and LLM-based navigation paradigms, while maintaining the interpretative prowess of LLMs in generating linguistic navigational reasoning. By aligning visual content in a frozen LLM, we encompass visual observation comprehension for LLMs and exploit a way to incorporate LLMs and navigation policy networks for effective action predictions and navigational reasoning. We demonstrate the data efficiency of the proposed methods and eliminate the gap between LM-based agents and state-of-the-art VLN specialists.
Read more9/23/2024
0
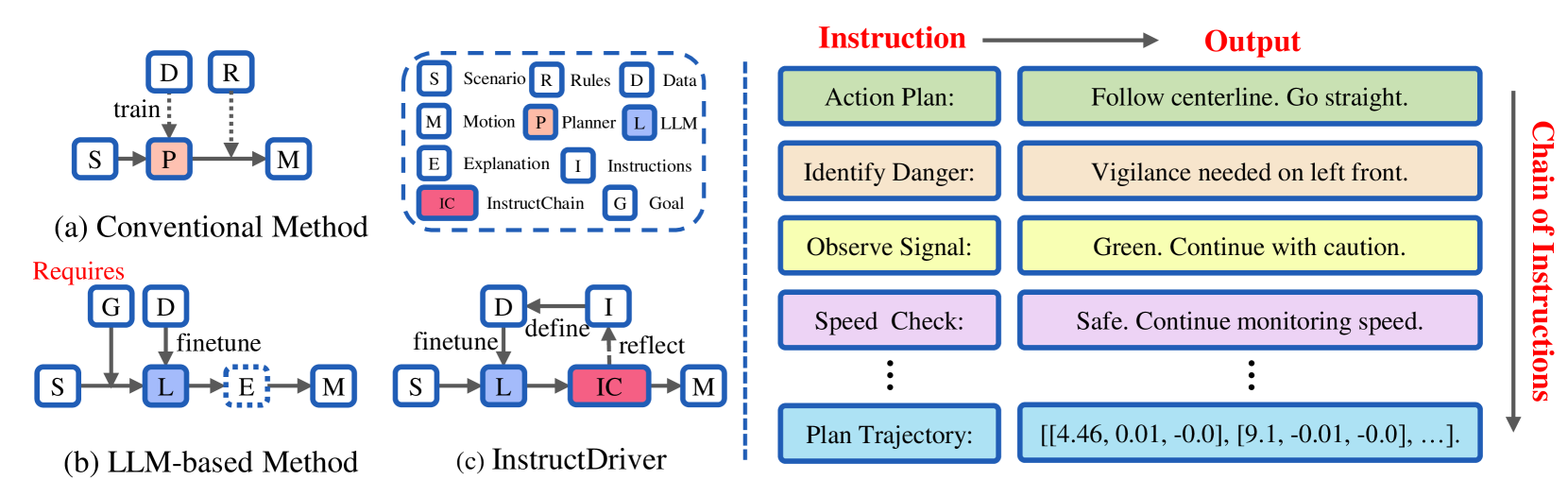
Instruct Large Language Models to Drive like Humans
Ruijun Zhang, Xianda Guo, Wenzhao Zheng, Chenming Zhang, Kurt Keutzer, Long Chen
Motion planning in complex scenarios is the core challenge in autonomous driving. Conventional methods apply predefined rules or learn from driving data to plan the future trajectory. Recent methods seek the knowledge preserved in large language models (LLMs) and apply them in the driving scenarios. Despite the promising results, it is still unclear whether the LLM learns the underlying human logic to drive. In this paper, we propose an InstructDriver method to transform LLM into a motion planner with explicit instruction tuning to align its behavior with humans. We derive driving instruction data based on human logic (e.g., do not cause collisions) and traffic rules (e.g., proceed only when green lights). We then employ an interpretable InstructChain module to further reason the final planning reflecting the instructions. Our InstructDriver allows the injection of human rules and learning from driving data, enabling both interpretability and data scalability. Different from existing methods that experimented on closed-loop or simulated settings, we adopt the real-world closed-loop motion planning nuPlan benchmark for better evaluation. InstructDriver demonstrates the effectiveness of the LLM planner in a real-world closed-loop setting. Our code is publicly available at https://github.com/bonbon-rj/InstructDriver.
Read more6/12/2024