Can Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
2404.18071
0
0
📶
Abstract
Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Recent language models use subword mechanisms to handle words not seen during training
- Perplexity, an intrinsic metric, is commonly used to measure the generation capacity of these models
- Increasing subword granularity typically reduces perplexity, but the impact on model understanding is less studied
- This paper explores how different tokenization schemes affect the performance of language models on downstream tasks in Nepali
Plain English Explanation
Language models, the AI systems that can generate human-like text, often encounter words they haven't seen before during testing. To handle these out-of-vocabulary (OOV) words, they use subword mechanisms that break words down into smaller pieces. The ability of these models to generate text is usually measured by an intrinsic metric called perplexity, which gets lower as the model performs better.
Previous research has shown that increasing the granularity, or level of detail, of these subwords can reduce perplexity. However, there hasn't been much study on how subword choices affect the model's actual understanding of language, particularly for languages other than the major ones like English.
To explore this, the researchers in this paper used six different tokenization (subword splitting) schemes to train relatively small language models in the Nepali language. They then tested how well these models performed on various real-world language tasks, like summarizing text or answering questions.
The results showed that while a popular tokenization method used in models like GPT and RoBERTa (called byte-level BPE) can improve perplexity, it doesn't necessarily lead to the best performance on downstream tasks in Nepali. In fact, other algorithms like SentencePiece tended to work better. The researchers also focused on a different type of language model, called a sequential transformer, compared to the more common BERT-based models used in recent studies.
Technical Explanation
This paper investigates the impact of different subword tokenization schemes on the performance of language models, particularly on downstream tasks in the low-resource Nepali language.
The researchers trained relatively small sequential transformer-based language models using six diverse tokenization approaches: WordPiece, SentencePiece, Unigram, BPE, Byte-level BPE, and character-level. They then fine-tuned these pretrained models on a variety of Nepali NLP tasks, including text classification, question answering, and summarization.
While previous work has shown that increasing subword granularity can reduce perplexity, an intrinsic metric of language model performance, the authors found that this does not necessarily translate to better downstream task results. In fact, they demonstrate that the popular byte-level BPE algorithm used in models like GPT and RoBERTa is, on average, sub-optimal compared to alternatives like SentencePiece for fine-tuning on Nepali tasks.
This divergence between perplexity and task-specific performance highlights the importance of evaluating language models beyond just intrinsic measures. The authors' focus on a sequential transformer architecture, rather than the more commonly studied BERT-based models, also provides a complementary perspective on subword tokenization effects.
Critical Analysis
The researchers acknowledge several limitations in their work. First, they only explored a relatively small set of language models, trained on a limited amount of Nepali data. Expanding the scale and diversity of the models and datasets could provide a more comprehensive understanding of the tokenization effects.
Additionally, the paper does not delve into the underlying reasons why certain tokenization schemes outperform others for downstream tasks in Nepali. Further analysis of factors like the morphological complexity of the language, data distribution, and the specific task requirements could yield valuable insights.
While the authors demonstrate the suboptimal performance of byte-level BPE for Nepali, they do not investigate whether this finding generalizes to other low-resource languages. Systematic studies across a broader range of languages would be necessary to draw more definitive conclusions.
Finally, the paper does not address potential biases or limitations introduced by the choice of tokenization, which can be particularly relevant for applications involving sensitive domains like healthcare or social services.
Conclusion
This paper provides a valuable contribution to the understanding of how subword tokenization affects the performance of language models, particularly in the context of low-resource languages like Nepali. The finding that perplexity-optimal tokenization schemes do not necessarily lead to the best downstream task results highlights the importance of evaluating language models beyond just intrinsic metrics.
The authors' focus on sequential transformer architectures also offers a complementary perspective to the prevailing BERT-based models. While the study has some limitations, it underscores the need for more comprehensive research on the interplay between tokenization, model architecture, and task-specific performance, especially for underrepresented languages.
As language models become increasingly ubiquitous, understanding these nuanced factors will be crucial in developing robust and equitable AI systems that can truly benefit a diverse range of users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, Gabriel Synnaeve
0
0
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
5/1/2024
⚙️
Toward a Theory of Tokenization in LLMs
Nived Rajaraman, Jiantao Jiao, Kannan Ramchandran
0
0
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
4/15/2024
💬
Unraveling the Dominance of Large Language Models Over Transformer Models for Bangla Natural Language Inference: A Comprehensive Study
Fatema Tuj Johora Faria, Mukaffi Bin Moin, Asif Iftekher Fahim, Pronay Debnath, Faisal Muhammad Shah
0
0
Natural Language Inference (NLI) is a cornerstone of Natural Language Processing (NLP), providing insights into the entailment relationships between text pairings. It is a critical component of Natural Language Understanding (NLU), demonstrating the ability to extract information from spoken or written interactions. NLI is mainly concerned with determining the entailment relationship between two statements, known as the premise and hypothesis. When the premise logically implies the hypothesis, the pair is labeled entailment. If the hypothesis contradicts the premise, the pair receives the contradiction label. When there is insufficient evidence to establish a connection, the pair is described as neutral. Despite the success of Large Language Models (LLMs) in various tasks, their effectiveness in NLI remains constrained by issues like low-resource domain accuracy, model overconfidence, and difficulty in capturing human judgment disagreements. This study addresses the underexplored area of evaluating LLMs in low-resourced languages such as Bengali. Through a comprehensive evaluation, we assess the performance of prominent LLMs and state-of-the-art (SOTA) models in Bengali NLP tasks, focusing on natural language inference. Utilizing the XNLI dataset, we conduct zero-shot and few-shot evaluations, comparing LLMs like GPT-3.5 Turbo and Gemini 1.5 Pro with models such as BanglaBERT, Bangla BERT Base, DistilBERT, mBERT, and sahajBERT. Our findings reveal that while LLMs can achieve comparable or superior performance to fine-tuned SOTA models in few-shot scenarios, further research is necessary to enhance our understanding of LLMs in languages with modest resources like Bengali. This study underscores the importance of continued efforts in exploring LLM capabilities across diverse linguistic contexts.
5/8/2024
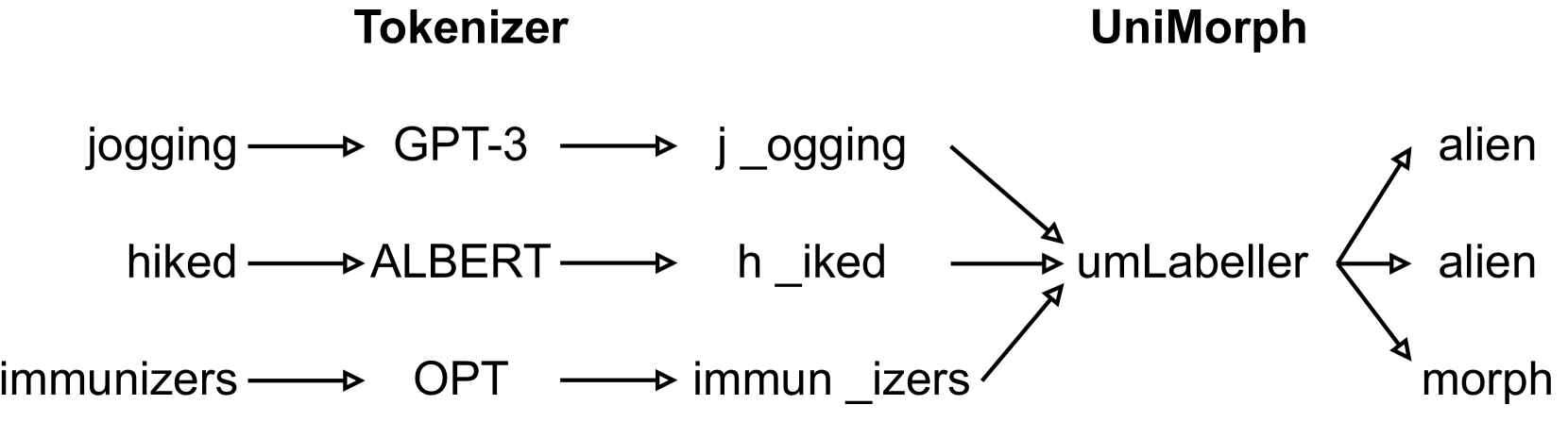
Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge
Khuyagbaatar Batsuren, Ekaterina Vylomova, Verna Dankers, Tsetsuukhei Delgerbaatar, Omri Uzan, Yuval Pinter, G'abor Bella
0
0
The popular subword tokenizers of current language models, such as Byte-Pair Encoding (BPE), are known not to respect morpheme boundaries, which affects the downstream performance of the models. While many improved tokenization algorithms have been proposed, their evaluation and cross-comparison is still an open problem. As a solution, we propose a combined intrinsic-extrinsic evaluation framework for subword tokenization. Intrinsic evaluation is based on our new UniMorph Labeller tool that classifies subword tokenization as either morphological or alien. Extrinsic evaluation, in turn, is performed via the Out-of-Vocabulary Generalization Challenge 1.0 benchmark, which consists of three newly specified downstream text classification tasks. Our empirical findings show that the accuracy of UniMorph Labeller is 98%, and that, in all language models studied (including ALBERT, BERT, RoBERTa, and DeBERTa), alien tokenization leads to poorer generalizations compared to morphological tokenization for semantic compositionality of word meanings.
4/23/2024