Toward a Theory of Tokenization in LLMs
2404.08335
0
0
⚙️
Abstract
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper investigates the role of tokenization in language modeling using transformers.
- It finds that without tokenization, transformers fail to learn the right distribution and instead predict characters according to a unigram model when trained on certain Markov processes.
- With tokenization, transformers can model the probabilities of sequences from these Markov sources near-optimally.
- The analysis provides a justification for the use of tokenization in practice by studying transformer behavior on Markovian data.
Plain English Explanation
The paper examines the importance of tokenization in language modeling using transformer models. Tokenization is the process of breaking text into smaller units, like words or subwords, that a model can understand.
The researchers found that without tokenization, transformer models struggle to learn the underlying patterns in certain types of data, known as Markov processes. Instead, the models just predict the next character based on how often it appears in the overall text, rather than understanding the sequence.
However, with tokenization, the transformer models were able to accurately model the probabilities of the sequences from these Markov sources. This suggests that tokenization is a crucial step that allows transformer models to effectively learn the structure of language.
The paper provides an analysis to explain why tokenization is important for transformers to perform well on language modeling tasks. Even simple token-level models learned by transformers can model the probability of sequences from Markov sources very well, as long as the appropriate tokenization is used.
Technical Explanation
The paper investigates the role of tokenization in the performance of transformer language models. The researchers trained transformers on data drawn from certain $k^{th}$-order Markov processes, where the probability of each character depends on the previous $k$ characters.
They found that without tokenization, the transformers failed to learn the right distribution and instead predicted characters according to a simple unigram model, regardless of the Markov order $k$. However, with the addition of tokenization, the transformers were able to model the probabilities of sequences from these Markov sources near-optimally, achieving low cross-entropy loss.
Building on this observation, the paper provides a theoretical analysis of the end-to-end cross-entropy loss achieved by transformers with and without tokenization. It shows that even the simplest unigram models (over tokens) learned by transformers with appropriate tokenization can model the probability of sequences from $k^{th}$-order Markov sources near-optimally.
This analysis helps explain the practical importance of tokenization for transformer-based language models. The beneficial effects of tokenization on model performance are further supported by the finding that learned representations of characters and subwords can be mutually informative for language modeling.
Critical Analysis
The paper provides a thorough theoretical justification for the use of tokenization in transformer-based language models. However, it is important to note that the analysis is limited to simple Markov processes, which may not fully capture the complexity of natural language.
Additionally, the paper does not address the potential challenges of tokenization in data-scarce settings or the effects of near-duplicate subwords on language modeling performance. Further research is needed to understand the broader implications of tokenization for transformer models in more realistic scenarios.
It would also be interesting to see how the insights from this paper could be leveraged to enhance the inference efficiency of large language models, which is an important practical consideration for their deployment.
Conclusion
This paper offers a compelling theoretical explanation for the importance of tokenization in transformer-based language modeling. By studying the behavior of transformers on simple Markov processes, the researchers demonstrate that tokenization is a necessary step for these models to learn the underlying structure of language effectively.
The findings have important implications for the design and development of high-performing language models, as they provide a deeper understanding of the role of tokenization in model performance. This knowledge can inform future research and guide practitioners in building more robust and efficient language modeling systems.
Related Papers
💬
Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
Yuxi Li, Yi Liu, Gelei Deng, Ying Zhang, Wenjia Song, Ling Shi, Kailong Wang, Yuekang Li, Yang Liu, Haoyu Wang
0
0
With the expanding application of Large Language Models (LLMs) in various domains, it becomes imperative to comprehensively investigate their unforeseen behaviors and consequent outcomes. In this study, we introduce and systematically explore the phenomenon of glitch tokens, which are anomalous tokens produced by established tokenizers and could potentially compromise the models' quality of response. Specifically, we experiment on seven top popular LLMs utilizing three distinct tokenizers and involving a totally of 182,517 tokens. We present categorizations of the identified glitch tokens and symptoms exhibited by LLMs when interacting with glitch tokens. Based on our observation that glitch tokens tend to cluster in the embedding space, we propose GlitchHunter, a novel iterative clustering-based technique, for efficient glitch token detection. The evaluation shows that our approach notably outperforms three baseline methods on eight open-source LLMs. To the best of our knowledge, we present the first comprehensive study on glitch tokens. Our new detection further provides valuable insights into mitigating tokenization-related errors in LLMs.
4/22/2024
💬
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, Gabriel Synnaeve
0
0
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
5/1/2024
Tokenization Matters: Navigating Data-Scarce Tokenization for Gender Inclusive Language Technologies
Anaelia Ovalle, Ninareh Mehrabi, Palash Goyal, Jwala Dhamala, Kai-Wei Chang, Richard Zemel, Aram Galstyan, Yuval Pinter, Rahul Gupta
0
0
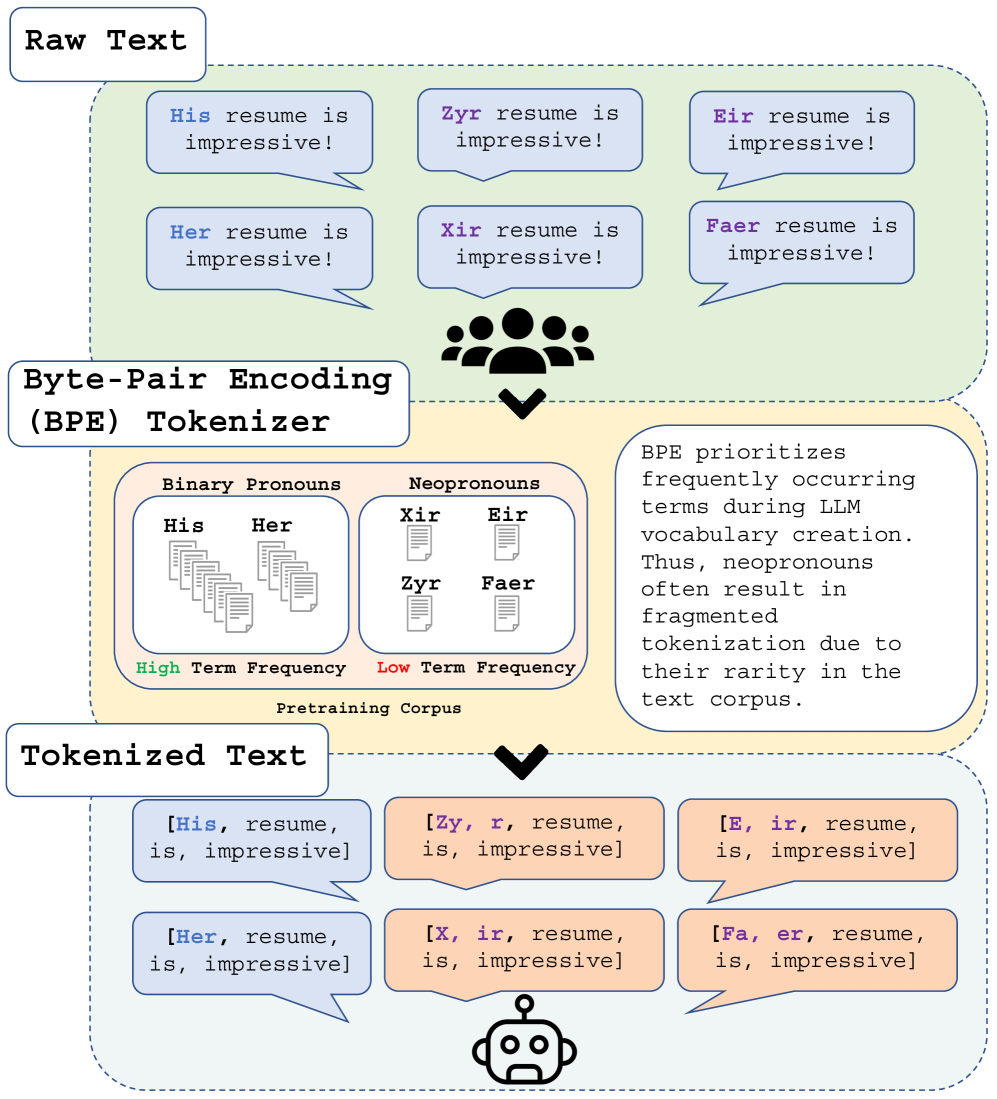
Gender-inclusive NLP research has documented the harmful limitations of gender binary-centric large language models (LLM), such as the inability to correctly use gender-diverse English neopronouns (e.g., xe, zir, fae). While data scarcity is a known culprit, the precise mechanisms through which scarcity affects this behavior remain underexplored. We discover LLM misgendering is significantly influenced by Byte-Pair Encoding (BPE) tokenization, the tokenizer powering many popular LLMs. Unlike binary pronouns, BPE overfragments neopronouns, a direct consequence of data scarcity during tokenizer training. This disparate tokenization mirrors tokenizer limitations observed in multilingual and low-resource NLP, unlocking new misgendering mitigation strategies. We propose two techniques: (1) pronoun tokenization parity, a method to enforce consistent tokenization across gendered pronouns, and (2) utilizing pre-existing LLM pronoun knowledge to improve neopronoun proficiency. Our proposed methods outperform finetuning with standard BPE, improving neopronoun accuracy from 14.1% to 58.4%. Our paper is the first to link LLM misgendering to tokenization and deficient neopronoun grammar, indicating that LLMs unable to correctly treat neopronouns as pronouns are more prone to misgender.
4/9/2024
Multi-word Tokenization for Sequence Compression
Leonidas Gee, Leonardo Rigutini, Marco Ernandes, Andrea Zugarini
0
0
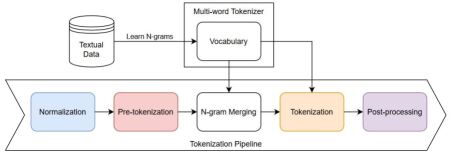
Large Language Models have proven highly successful at modelling a variety of tasks. However, this comes at a steep computational cost that hinders wider industrial uptake. In this paper, we present MWT: a Multi-Word Tokenizer that goes beyond word boundaries by representing frequent multi-word expressions as single tokens. MWTs produce a more compact and efficient tokenization that yields two benefits: (1) Increase in performance due to a greater coverage of input data given a fixed sequence length budget; (2) Faster and lighter inference due to the ability to reduce the sequence length with negligible drops in performance. Our results show that MWT is more robust across shorter sequence lengths, thus allowing for major speedups via early sequence truncation.
4/8/2024