Can Watermarking Large Language Models Prevent Copyrighted Text Generation and Hide Training Data?

0

Sign in to get full access
Overview
- Researchers investigated if watermarking large language models could prevent the generation of copyrighted text and hide their training data.
- They explored techniques to embed watermarks in the models that are hard to remove but can be detected by the model's owners.
- The goal was to enable tracing the source of generated text back to the original model, deterring copyright infringement and model extraction attacks.
Plain English Explanation
Watermarking is a way to embed secret information into digital content, like adding a subtle logo or pattern that's hard for others to remove. In this research, the scientists looked at whether they could watermark large language models - powerful AI systems trained on massive amounts of text data to generate human-like language.
The key idea was to encode a watermark in the language model itself, making it difficult for anyone else to copy or extract the model without the watermark being detected. This could help prevent the model from being misused to generate copyrighted text, and also reveal the original source if such text is produced.
For example, imagine a company develops a language model that writes articles. By watermarking the model, they could detect if someone tried to copy it and use it to write articles that violate copyrights. The watermark would allow the company to trace the source of the copied text back to their original model.
The researchers explored different technical approaches to embedding these kinds of robust and hard-to-remove watermarks in large language models. Their goal was to create a system that balanced the needs of the model's owners to protect their intellectual property, and the users' ability to freely use the language model.
Technical Explanation
The paper presents several methods for watermarking large language models:
-
Task-Specific Watermarking: Embedding the watermark by fine-tuning the model on a custom task that encodes the watermark. This approach modifies the model's internal parameters to carry the watermark signal.
-
Prompt Watermarking: Encoding the watermark in special prompts that are used to generate text from the model. The prompts act as a key that unlocks the watermarked text.
-
Output Watermarking: Directly marking the generated text output from the model with a watermark that is hard to remove.
The researchers evaluate these techniques on language models like GPT-2 and GPT-3, testing the watermark's strength, imperceptibility, and robustness against various attacks meant to remove or overwrite the watermark.
Their results show that these watermarking approaches can be effective at tracing the source of generated text back to the original model, while having minimal impact on the model's normal language generation capabilities.
Critical Analysis
The paper provides a thorough exploration of watermarking techniques for large language models, addressing an important challenge around protecting intellectual property and deterring misuse.
However, the authors acknowledge some limitations:
- The watermarks may still be vulnerable to more sophisticated removal techniques that weren't tested.
- There could be privacy concerns around the ability to trace text back to the original model.
- The watermarking process can introduce some degradation in the model's language generation performance.
Additionally, one could question whether watermarking is the best long-term solution, or if other approaches like better content licensing and regulation may be needed as language models become more advanced and pervasive.
Overall, this research represents an important step in developing practical tools to help manage the risks and challenges posed by powerful language models. But further work is likely needed to fully address the complex sociotechnical issues involved.
Conclusion
This paper investigates techniques to watermark large language models, with the goal of enabling tracing the source of generated text and deterring copyright infringement or model extraction attacks.
The proposed watermarking methods show promise in embedding robust and hard-to-remove signals in the models, while having minimal impact on their normal language generation capabilities. This could be a valuable tool for model owners to protect their intellectual property.
However, the authors acknowledge limitations around the watermarks' vulnerability to more sophisticated attacks, as well as potential privacy concerns and performance trade-offs. Broader societal questions around the governance and responsible development of advanced language models also remain to be addressed.
Overall, this research represents an important step forward in managing the risks and challenges posed by powerful language models, but further work is likely needed to fully solve these complex issues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can Watermarking Large Language Models Prevent Copyrighted Text Generation and Hide Training Data?
Michael-Andrei Panaitescu-Liess, Zora Che, Bang An, Yuancheng Xu, Pankayaraj Pathmanathan, Souradip Chakraborty, Sicheng Zhu, Tom Goldstein, Furong Huang
Large Language Models (LLMs) have demonstrated impressive capabilities in generating diverse and contextually rich text. However, concerns regarding copyright infringement arise as LLMs may inadvertently produce copyrighted material. In this paper, we first investigate the effectiveness of watermarking LLMs as a deterrent against the generation of copyrighted texts. Through theoretical analysis and empirical evaluation, we demonstrate that incorporating watermarks into LLMs significantly reduces the likelihood of generating copyrighted content, thereby addressing a critical concern in the deployment of LLMs. Additionally, we explore the impact of watermarking on Membership Inference Attacks (MIAs), which aim to discern whether a sample was part of the pretraining dataset and may be used to detect copyright violations. Surprisingly, we find that watermarking adversely affects the success rate of MIAs, complicating the task of detecting copyrighted text in the pretraining dataset. Finally, we propose an adaptive technique to improve the success rate of a recent MIA under watermarking. Our findings underscore the importance of developing adaptive methods to study critical problems in LLMs with potential legal implications.
Read more7/25/2024

0
Watermarking Techniques for Large Language Models: A Survey
Yuqing Liang, Jiancheng Xiao, Wensheng Gan, Philip S. Yu
With the rapid advancement and extensive application of artificial intelligence technology, large language models (LLMs) are extensively used to enhance production, creativity, learning, and work efficiency across various domains. However, the abuse of LLMs also poses potential harm to human society, such as intellectual property rights issues, academic misconduct, false content, and hallucinations. Relevant research has proposed the use of LLM watermarking to achieve IP protection for LLMs and traceability of multimedia data output by LLMs. To our knowledge, this is the first thorough review that investigates and analyzes LLM watermarking technology in detail. This review begins by recounting the history of traditional watermarking technology, then analyzes the current state of LLM watermarking research, and thoroughly examines the inheritance and relevance of these techniques. By analyzing their inheritance and relevance, this review can provide research with ideas for applying traditional digital watermarking techniques to LLM watermarking, to promote the cross-integration and innovation of watermarking technology. In addition, this review examines the pros and cons of LLM watermarking. Considering the current multimodal development trend of LLMs, it provides a detailed analysis of emerging multimodal LLM watermarking, such as visual and audio data, to offer more reference ideas for relevant research. This review delves into the challenges and future prospects of current watermarking technologies, offering valuable insights for future LLM watermarking research and applications.
Read more9/4/2024

0
A Survey of Text Watermarking in the Era of Large Language Models
Aiwei Liu, Leyi Pan, Yijian Lu, Jingjing Li, Xuming Hu, Xi Zhang, Lijie Wen, Irwin King, Hui Xiong, Philip S. Yu
Text watermarking algorithms are crucial for protecting the copyright of textual content. Historically, their capabilities and application scenarios were limited. However, recent advancements in large language models (LLMs) have revolutionized these techniques. LLMs not only enhance text watermarking algorithms with their advanced abilities but also create a need for employing these algorithms to protect their own copyrights or prevent potential misuse. This paper conducts a comprehensive survey of the current state of text watermarking technology, covering four main aspects: (1) an overview and comparison of different text watermarking techniques; (2) evaluation methods for text watermarking algorithms, including their detectability, impact on text or LLM quality, robustness under target or untargeted attacks; (3) potential application scenarios for text watermarking technology; (4) current challenges and future directions for text watermarking. This survey aims to provide researchers with a thorough understanding of text watermarking technology in the era of LLM, thereby promoting its further advancement.
Read more8/2/2024
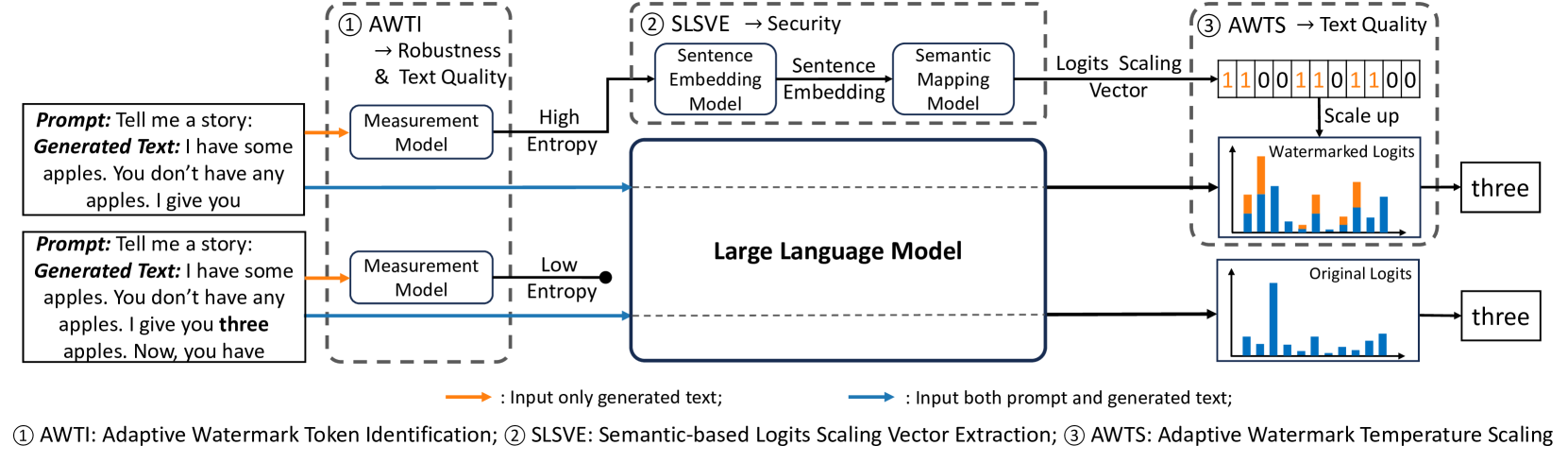
0
Adaptive Text Watermark for Large Language Models
Yepeng Liu, Yuheng Bu
The advancement of Large Language Models (LLMs) has led to increasing concerns about the misuse of AI-generated text, and watermarking for LLM-generated text has emerged as a potential solution. However, it is challenging to generate high-quality watermarked text while maintaining strong security, robustness, and the ability to detect watermarks without prior knowledge of the prompt or model. This paper proposes an adaptive watermarking strategy to address this problem. To improve the text quality and maintain robustness, we adaptively add watermarking to token distributions with high entropy measured using an auxiliary model and keep the low entropy token distributions untouched. For the sake of security and to further minimize the watermark's impact on text quality, instead of using a fixed green/red list generated from a random secret key, which can be vulnerable to decryption and forgery, we adaptively scale up the output logits in proportion based on the semantic embedding of previously generated text using a well designed semantic mapping model. Our experiments involving various LLMs demonstrate that our approach achieves comparable robustness performance to existing watermark methods. Additionally, the text generated by our method has perplexity comparable to that of emph{un-watermarked} LLMs while maintaining security even under various attacks.
Read more6/11/2024