Adaptive Text Watermark for Large Language Models
2401.13927
0
0
Abstract
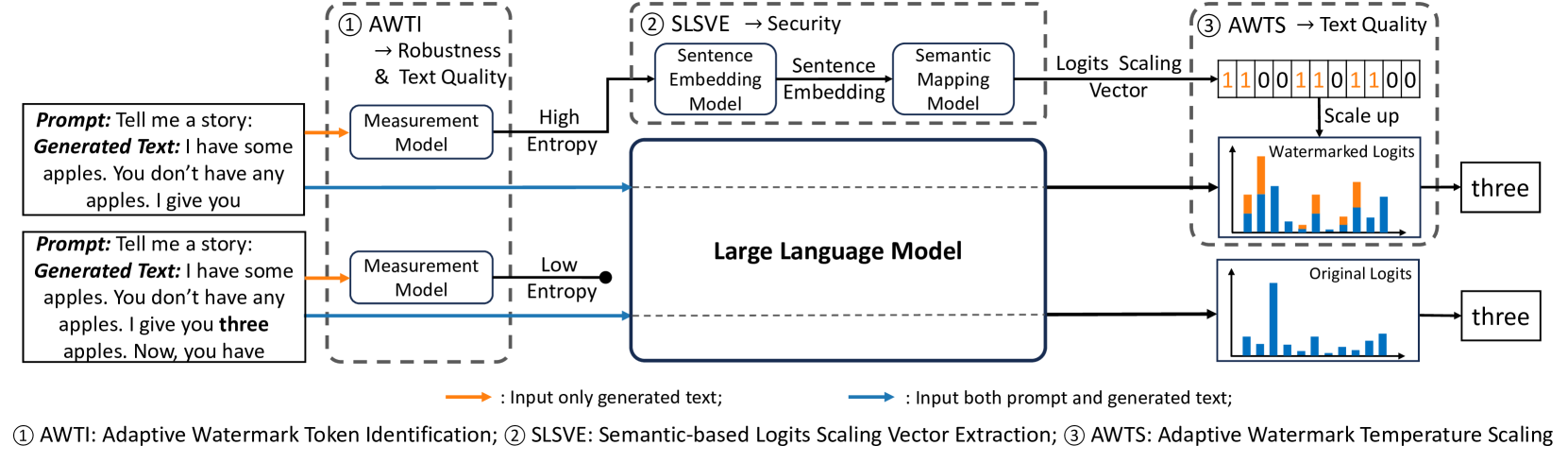
The advancement of Large Language Models (LLMs) has led to increasing concerns about the misuse of AI-generated text, and watermarking for LLM-generated text has emerged as a potential solution. However, it is challenging to generate high-quality watermarked text while maintaining strong security, robustness, and the ability to detect watermarks without prior knowledge of the prompt or model. This paper proposes an adaptive watermarking strategy to address this problem. To improve the text quality and maintain robustness, we adaptively add watermarking to token distributions with high entropy measured using an auxiliary model and keep the low entropy token distributions untouched. For the sake of security and to further minimize the watermark's impact on text quality, instead of using a fixed green/red list generated from a random secret key, which can be vulnerable to decryption and forgery, we adaptively scale up the output logits in proportion based on the semantic embedding of previously generated text using a well designed semantic mapping model. Our experiments involving various LLMs demonstrate that our approach achieves comparable robustness performance to existing watermark methods. Additionally, the text generated by our method has perplexity comparable to that of emph{un-watermarked} LLMs while maintaining security even under various attacks.
Create account to get full access
Overview
- The research paper proposes an "Adaptive Text Watermark for Large Language Models" to help identify the source of generated text and mitigate model extraction attacks.
- The key idea is to generate watermarks that are semantically coherent and adaptive to the input, making them harder to detect and remove.
- The authors develop techniques to embed these watermarks in the text output of large language models in a robust and reliable way.
Plain English Explanation
The paper discusses a way to "watermark" the text generated by large language models (LLMs) like GPT-3. [internal link: https://aimodels.fyi/papers/arxiv/semantic-invariant-robust-watermark-large-language-models] This means adding a hidden mark or signature that can be used to identify the source of the text.
The challenge is making these watermarks effective and hard to remove. The researchers developed a system that generates watermarks that adapt to the input text, fitting in seamlessly with the content and flow of the language. [internal link: https://aimodels.fyi/papers/arxiv/token-specific-watermarking-enhanced-detectability-semantic-coherence] This makes the watermarks much harder for attackers to detect and remove compared to simpler, static watermarks.
The goal is to help protect against "model extraction" attacks, where bad actors try to copy or reproduce the capabilities of LLMs without permission. [internal link: https://aimodels.fyi/papers/arxiv/reliability-watermarks-large-language-models] By watermarking the output, it becomes possible to trace the source and ownership of generated text, deterring such attacks.
Technical Explanation
The paper introduces an "Adaptive Text Watermark" system that generates semantically coherent watermarks that adapt to the input text. The key innovation is a watermark generation model that learns to produce watermarks that blend seamlessly into the given text, rather than using a fixed, universal watermark.
The authors train this watermark model using a combination of language modeling and adversarial techniques. The model learns to generate watermarks that are both grammatically and semantically compatible with the input, making them very difficult to detect and remove. [internal link: https://aimodels.fyi/papers/arxiv/learnable-linguistic-watermarks-tracing-model-extraction-attacks]
The authors evaluate their system on several language tasks and show that the adaptive watermarks achieve high detectability (the ability to identify the source) while maintaining strong semantic coherence (the watermark blends naturally into the text). They also demonstrate the watermarks' resilience to various removal attacks.
Critical Analysis
The paper presents a thoughtful and technically sound approach to watermarking LLM outputs. The core idea of adaptive, semantically coherent watermarks is a clever solution to the challenges of making watermarks both effective and unobtrusive.
That said, the authors acknowledge some limitations. The watermarking system is not perfect, and determined adversaries may still be able to detect and remove the watermarks in some cases. Additionally, the system has only been tested on a limited set of language tasks, and its performance may vary on more diverse or specialized text generation scenarios.
Further research could explore ways to make the watermarks even more robust, potentially incorporating more sophisticated language understanding and generation techniques. The authors could also investigate the broader implications and potential unintended consequences of watermarking technology, such as privacy concerns or the potential for misuse.
Overall, this paper presents a valuable contribution to the field of LLM security and accountability. The adaptive watermarking approach is a promising step towards enabling better traceability and responsible use of these powerful language models.
Conclusion
The "Adaptive Text Watermark for Large Language Models" paper introduces an innovative technique for embedding semantically coherent, adaptive watermarks in the text output of large language models. These watermarks are designed to be highly detectable by the model's owners while remaining difficult for attackers to identify and remove.
By providing a reliable way to trace the source of generated text, this work aims to help mitigate model extraction attacks and promote the responsible development and deployment of large language models. While the system has some limitations, the core ideas presented in this paper represent an important advancement in the field of LLM security and accountability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Watermark for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein
0
0
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of green tokens before a word is generated, and then softly promoting use of green tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
5/3/2024

A Semantic Invariant Robust Watermark for Large Language Models
Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, Lijie Wen
0
0
Watermark algorithms for large language models (LLMs) have achieved extremely high accuracy in detecting text generated by LLMs. Such algorithms typically involve adding extra watermark logits to the LLM's logits at each generation step. However, prior algorithms face a trade-off between attack robustness and security robustness. This is because the watermark logits for a token are determined by a certain number of preceding tokens; a small number leads to low security robustness, while a large number results in insufficient attack robustness. In this work, we propose a semantic invariant watermarking method for LLMs that provides both attack robustness and security robustness. The watermark logits in our work are determined by the semantics of all preceding tokens. Specifically, we utilize another embedding LLM to generate semantic embeddings for all preceding tokens, and then these semantic embeddings are transformed into the watermark logits through our trained watermark model. Subsequent analyses and experiments demonstrated the attack robustness of our method in semantically invariant settings: synonym substitution and text paraphrasing settings. Finally, we also show that our watermark possesses adequate security robustness. Our code and data are available at href{https://github.com/THU-BPM/Robust_Watermark}{https://github.com/THU-BPM/Robust_Watermark}. Additionally, our algorithm could also be accessed through MarkLLM citep{pan2024markllm} footnote{https://github.com/THU-BPM/MarkLLM}.
5/21/2024
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mingjia Huo, Sai Ashish Somayajula, Youwei Liang, Ruisi Zhang, Farinaz Koushanfar, Pengtao Xie
0
0
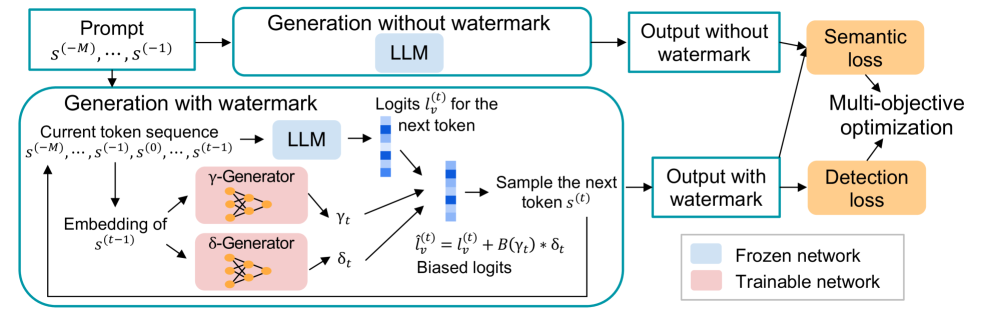
Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Achieving both the detectability of inserted watermarks and the semantic quality of generated texts is challenging. While current watermarking algorithms have made promising progress in this direction, there remains significant scope for improvement. To address these challenges, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
6/7/2024
📈
Learnable Linguistic Watermarks for Tracing Model Extraction Attacks on Large Language Models
Minhao Bai, Kaiyi Pang, Yongfeng Huang
0
0
In the rapidly evolving domain of artificial intelligence, safeguarding the intellectual property of Large Language Models (LLMs) is increasingly crucial. Current watermarking techniques against model extraction attacks, which rely on signal insertion in model logits or post-processing of generated text, remain largely heuristic. We propose a novel method for embedding learnable linguistic watermarks in LLMs, aimed at tracing and preventing model extraction attacks. Our approach subtly modifies the LLM's output distribution by introducing controlled noise into token frequency distributions, embedding an statistically identifiable controllable watermark.We leverage statistical hypothesis testing and information theory, particularly focusing on Kullback-Leibler Divergence, to differentiate between original and modified distributions effectively. Our watermarking method strikes a delicate well balance between robustness and output quality, maintaining low false positive/negative rates and preserving the LLM's original performance.
5/3/2024