CAPformer: Compression-Aware Pre-trained Transformer for Low-Light Image Enhancement

0

Sign in to get full access
Overview
- This paper introduces CAPformer, a pre-trained transformer model for low-light image enhancement that is also aware of image compression.
- The goal is to develop a model that can effectively enhance low-light images while considering the impact of compression, which is important for real-world applications.
- The paper explores techniques to make the model more robust to compression artifacts and demonstrates its performance on various benchmarks.
Plain English Explanation
Enhancing low-light images is an important task, as many photos taken in dim lighting can appear dull and lacking in detail. However, one challenge is that these enhanced images often need to be compressed before they can be shared or stored, which can further degrade the quality.
The researchers behind CAPformer aimed to address this issue by creating a pre-trained transformer model that is specifically designed to work well with compressed low-light images. Transformer models are a type of machine learning architecture that have shown impressive results in various image and language tasks.
The key idea behind CAPformer is to train the model to not only enhance low-light images, but also to be aware of the effects of compression. This means the model can produce enhanced images that hold up better even after they've been compressed, without losing too much quality.
The researchers tested CAPformer on a variety of low-light image benchmarks and found that it outperformed other state-of-the-art methods, especially when the images were compressed. This suggests CAPformer could be a valuable tool for real-world applications like improving the quality of photos taken in dim lighting on smartphones or other devices.
Technical Explanation
The CAPformer model is built upon the Transformer architecture, which has shown great success in various vision and language tasks. The key innovation is the incorporation of a "compression-aware" component that allows the model to better handle the effects of image compression.
Specifically, the CAPformer architecture includes a compression simulation module that mimics the compression process during training. This helps the model learn how to produce enhanced images that are more robust to compression artifacts. The researchers also explore different ways of integrating this compression-aware component, including directly modulating the transformer's attention mechanism.
In their experiments, the authors evaluate CAPformer on several low-light image enhancement benchmarks, including DICM, LOL, and LIME. They show that CAPformer outperforms other state-of-the-art methods, especially when the input images are compressed. The model also demonstrates improved perceptual quality and PSNR (peak signal-to-noise ratio) metrics compared to the baselines.
Critical Analysis
The authors of the CAPformer paper have made a compelling case for the importance of considering image compression in the context of low-light image enhancement. By explicitly incorporating a compression-aware component into the model, they have been able to improve the robustness and performance of the enhanced images, even after they have been compressed.
One potential limitation of the research is that it focuses primarily on simulated compression during training, rather than evaluating the model's performance on real-world compressed images. It would be interesting to see how CAPformer fares when applied to a wider range of compression algorithms and scenarios.
Additionally, the paper does not provide much insight into the potential computational or memory overhead of the compression-aware module. As with any additional model complexity, there may be trade-offs in terms of inference speed or resource requirements that would need to be considered for real-world deployment.
Overall, the CAPformer research represents an important step forward in addressing the practical challenges of low-light image enhancement in the context of modern image processing and sharing workflows. The authors' focus on compression-awareness is a valuable contribution to the field, and their results suggest exciting opportunities for further exploration and refinement of this approach.
Conclusion
The CAPformer paper presents a novel pre-trained transformer model for low-light image enhancement that is designed to be aware of and robust to image compression. By incorporating a compression simulation module into the model architecture, the researchers have been able to improve the quality and perceptual performance of enhanced images, even after they have been compressed.
This work highlights the importance of considering real-world constraints and challenges, such as compression, when developing advanced image processing algorithms. The CAPformer model's strong performance on benchmarks suggests it could be a valuable tool for a wide range of applications, from improving the quality of smartphone photos to enhancing images for online sharing and distribution.
As the field of low-light image enhancement continues to evolve, the insights and techniques explored in this paper are likely to inspire further research and development in this area, ultimately leading to more practical and impactful solutions for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CAPformer: Compression-Aware Pre-trained Transformer for Low-Light Image Enhancement
Wei Wang, Zhi Jin
Low-Light Image Enhancement (LLIE) has advanced with the surge in phone photography demand, yet many existing methods neglect compression, a crucial concern for resource-constrained phone photography. Most LLIE methods overlook this, hindering their effectiveness. In this study, we investigate the effects of JPEG compression on low-light images and reveal substantial information loss caused by JPEG due to widespread low pixel values in dark areas. Hence, we propose the Compression-Aware Pre-trained Transformer (CAPformer), employing a novel pre-training strategy to learn lossless information from uncompressed low-light images. Additionally, the proposed Brightness-Guided Self-Attention (BGSA) mechanism enhances rational information gathering. Experiments demonstrate the superiority of our approach in mitigating compression effects on LLIE, showcasing its potential for improving LLIE in resource-constrained scenarios.
Read more7/11/2024
0
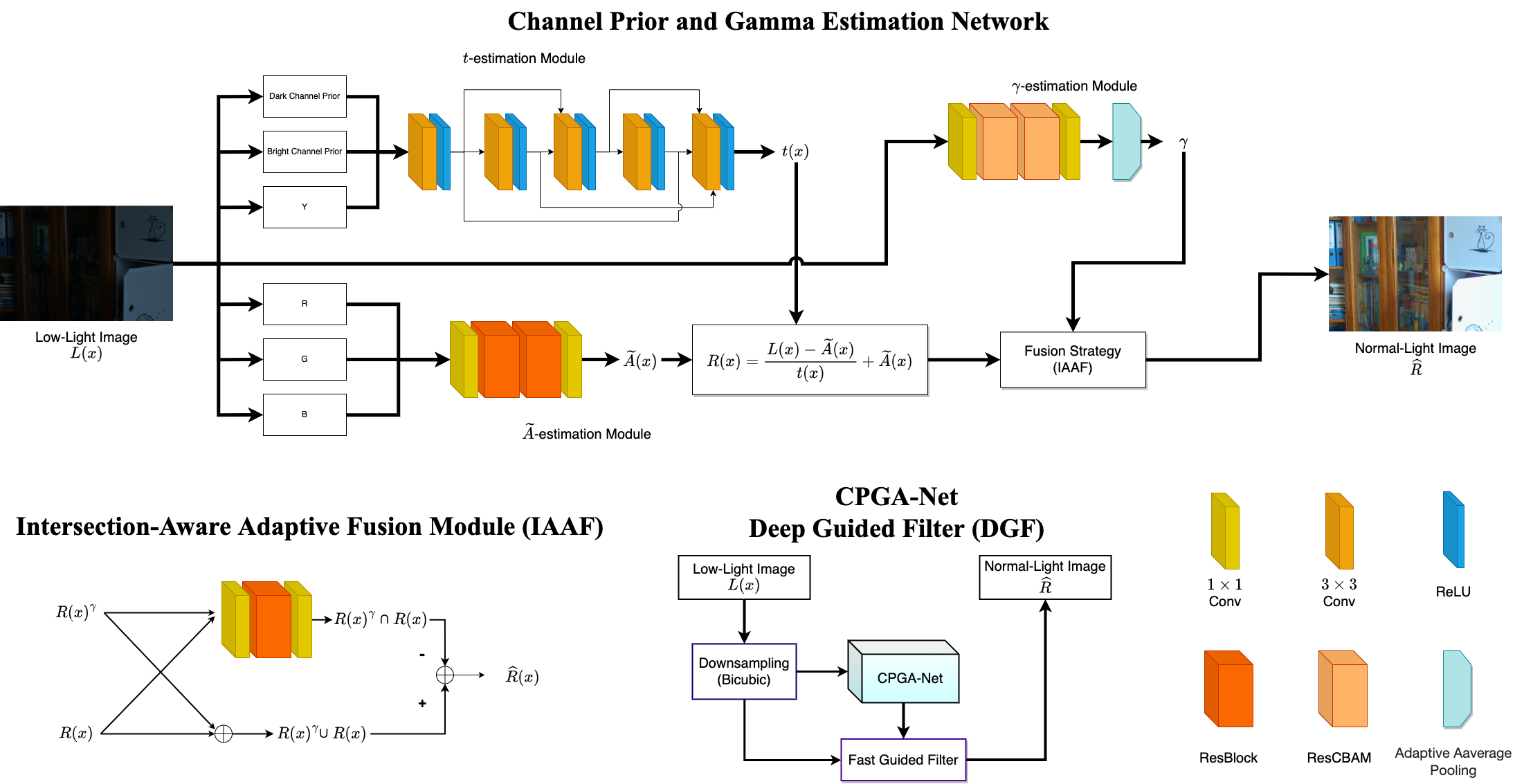
A Lightweight Low-Light Image Enhancement Network via Channel Prior and Gamma Correction
Shyang-En Weng, Shaou-Gang Miaou, Ricky Christanto
Human vision relies heavily on available ambient light to perceive objects. Low-light scenes pose two distinct challenges: information loss due to insufficient illumination and undesirable brightness shifts. Low-light image enhancement (LLIE) refers to image enhancement technology tailored to handle this scenario. We introduce CPGA-Net, an innovative LLIE network that combines dark/bright channel priors and gamma correction via deep learning and integrates features inspired by the Atmospheric Scattering Model and the Retinex Theory. This approach combines the use of traditional and deep learning methodologies, designed within a simple yet efficient architectural framework that focuses on essential feature extraction. The resulting CPGA-Net is a lightweight network with only 0.025 million parameters and 0.030 seconds for inference time, yet it achieves superior performance over existing LLIE methods on both objective and subjective evaluation criteria. Furthermore, we utilized knowledge distillation with explainable factors and proposed an efficient version that achieves 0.018 million parameters and 0.006 seconds for inference time. The proposed approaches inject new solution ideas into LLIE, providing practical applications in challenging low-light scenarios.
Read more7/12/2024

0
CodeEnhance: A Codebook-Driven Approach for Low-Light Image Enhancement
Xu Wu, XianXu Hou, Zhihui Lai, Jie Zhou, Ya-nan Zhang, Witold Pedrycz, Linlin Shen
Low-light image enhancement (LLIE) aims to improve low-illumination images. However, existing methods face two challenges: (1) uncertainty in restoration from diverse brightness degradations; (2) loss of texture and color information caused by noise suppression and light enhancement. In this paper, we propose a novel enhancement approach, CodeEnhance, by leveraging quantized priors and image refinement to address these challenges. In particular, we reframe LLIE as learning an image-to-code mapping from low-light images to discrete codebook, which has been learned from high-quality images. To enhance this process, a Semantic Embedding Module (SEM) is introduced to integrate semantic information with low-level features, and a Codebook Shift (CS) mechanism, designed to adapt the pre-learned codebook to better suit the distinct characteristics of our low-light dataset. Additionally, we present an Interactive Feature Transformation (IFT) module to refine texture and color information during image reconstruction, allowing for interactive enhancement based on user preferences. Extensive experiments on both real-world and synthetic benchmarks demonstrate that the incorporation of prior knowledge and controllable information transfer significantly enhances LLIE performance in terms of quality and fidelity. The proposed CodeEnhance exhibits superior robustness to various degradations, including uneven illumination, noise, and color distortion.
Read more5/1/2024

0
LiDAR Depth Map Guided Image Compression Model
Alessandro Gnutti, Stefano Della Fiore, Mattia Savardi, Yi-Hsin Chen, Riccardo Leonardi, Wen-Hsiao Peng
The incorporation of LiDAR technology into some high-end smartphones has unlocked numerous possibilities across various applications, including photography, image restoration, augmented reality, and more. In this paper, we introduce a novel direction that harnesses LiDAR depth maps to enhance the compression of the corresponding RGB camera images. To the best of our knowledge, this represents the initial exploration in this particular research direction. Specifically, we propose a Transformer-based learned image compression system capable of achieving variable-rate compression using a single model while utilizing the LiDAR depth map as supplementary information for both the encoding and decoding processes. Experimental results demonstrate that integrating LiDAR yields an average PSNR gain of 0.83 dB and an average bitrate reduction of 16% as compared to its absence.
Read more6/28/2024