A Survey on Transformer Compression
2402.05964
1
14
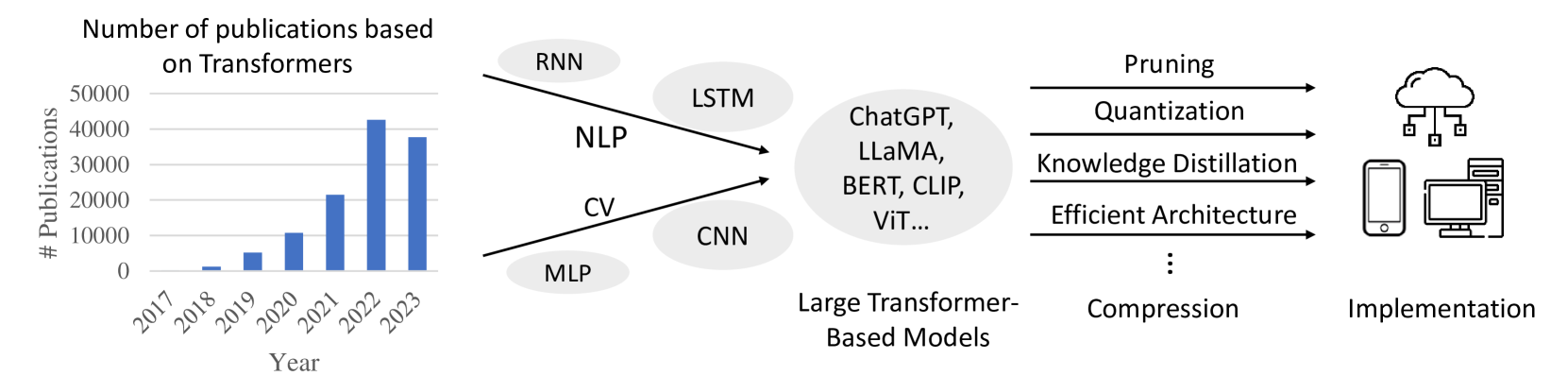
Abstract
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive survey on techniques for compressing large transformer models, which are widely used in computer vision and natural language processing tasks.
- The survey covers various model compression methods, including architecture-preserved compression, training over neurally compressed text, and efficient large language models through compact representations.
- The paper also discusses the challenges and trade-offs involved in compressing transformer models while preserving their performance and functionality.
Plain English Explanation
Transformer models are a type of artificial intelligence (AI) system that have become very powerful and widely used in applications like computer vision and natural language processing. However, these models can be very large and complex, which makes them computationally expensive to run and difficult to deploy on resource-constrained devices.
This paper surveys different techniques that researchers have developed to "compress" or reduce the size of transformer models without losing too much of their performance. Some of these techniques involve restructuring the model architecture to be more efficient, while others focus on training the model on compressed data representations or developing more compact ways of storing the model parameters.
The key idea behind all of these compression techniques is to find ways to make the transformer models smaller and more efficient, so that they can be used in a wider range of applications, including on smaller devices with limited computing power. The paper discusses the tradeoffs and challenges involved in balancing model size, speed, and accuracy, and provides an overview of the current state-of-the-art in transformer compression research.
Technical Explanation
The paper begins by introducing the concept of transformer models, which are a type of neural network architecture that have become widely used in computer vision and natural language processing tasks due to their ability to efficiently capture long-range dependencies in data. However, transformer models can be very large and computationally expensive, which limits their deployment in real-world applications.
The survey then covers several different approaches to compressing transformer models:
-
Architecture-preserved compression: These techniques focus on restructuring the transformer model architecture to be more efficient, such as by using graph-based attention mechanisms or introducing sparse and low-rank matrix factorizations. The goal is to reduce the number of parameters and computations required while preserving the model's performance.
-
Training over neurally compressed text: Another approach is to train the transformer model on data that has been pre-compressed using neural network-based techniques, such as generative adversarial networks (GANs) or auto-encoders. This can reduce the overall model size and memory footprint.
-
Efficient large language models through compact representations: In this approach, the focus is on finding more compact ways of representing the model parameters, such as through low-rank matrix factorization or product quantization. This can significantly reduce the storage requirements for large transformer models.
The paper also discusses the trade-offs and challenges involved in these compression techniques, such as balancing model size, speed, and accuracy, as well as the need for effective evaluation metrics and benchmarks to assess the performance of compressed models.
Critical Analysis
The paper provides a comprehensive and well-structured survey of the current state-of-the-art in transformer compression techniques. The authors do a good job of highlighting the key ideas and trade-offs involved in each approach, and the inclusion of relevant internal links to related research papers is helpful for readers who want to dive deeper into the technical details.
One potential limitation of the survey is that it primarily focuses on compression methods that preserve the overall architecture of the transformer model. While this is an important and active area of research, there may be other approaches, such as learning to compress prompt formats, that are not covered in depth. Additionally, the paper does not delve into the specific challenges and considerations involved in deploying compressed transformer models in real-world applications, such as on edge devices or in resource-constrained environments.
Overall, this survey is a valuable resource for researchers and practitioners working on transformer model compression, providing a solid foundation for understanding the current techniques and their trade-offs. However, readers may need to supplement the information in this paper with additional research to get a more complete picture of the field and its practical implications.
Conclusion
In conclusion, this paper provides a comprehensive survey of the various techniques being developed to compress large transformer models, which are crucial for enabling the widespread deployment of these powerful AI systems in real-world applications. The survey covers a range of compression approaches, including architecture-preserved compression, training over neurally compressed text, and efficient large language models through compact representations.
By summarizing the key ideas, trade-offs, and challenges involved in these compression techniques, the paper serves as a valuable resource for researchers and practitioners working in this space. As the field of transformer compression continues to evolve, this survey can help guide future research and development efforts, ultimately contributing to the broader goal of making large-scale AI models more accessible and practical for a wide range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Comprehensive Survey of Model Compression and Speed up for Vision Transformers
Feiyang Chen, Ziqian Luo, Lisang Zhou, Xueting Pan, Ying Jiang
0
0
Vision Transformers (ViT) have marked a paradigm shift in computer vision, outperforming state-of-the-art models across diverse tasks. However, their practical deployment is hampered by high computational and memory demands. This study addresses the challenge by evaluating four primary model compression techniques: quantization, low-rank approximation, knowledge distillation, and pruning. We methodically analyze and compare the efficacy of these techniques and their combinations in optimizing ViTs for resource-constrained environments. Our comprehensive experimental evaluation demonstrates that these methods facilitate a balanced compromise between model accuracy and computational efficiency, paving the way for wider application in edge computing devices.
4/17/2024
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
👀
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Tobias Christian Nauen, Sebastian Palacio, Andreas Dengel
0
0
Transformers come with a high computational cost, yet their effectiveness in addressing problems in language and vision has sparked extensive research aimed at enhancing their efficiency. However, diverse experimental conditions, spanning multiple input domains, prevent a fair comparison based solely on reported results, posing challenges for model selection. To address this gap in comparability, we design a comprehensive benchmark of more than 30 models for image classification, evaluating key efficiency aspects, including accuracy, speed, and memory usage. This benchmark provides a standardized baseline across the landscape of efficiency-oriented transformers and our framework of analysis, based on Pareto optimality, reveals surprising insights. Despite claims of other models being more efficient, ViT remains Pareto optimal across multiple metrics. We observe that hybrid attention-CNN models exhibit remarkable inference memory- and parameter-efficiency. Moreover, our benchmark shows that using a larger model in general is more efficient than using higher resolution images. Thanks to our holistic evaluation, we provide a centralized resource for practitioners and researchers, facilitating informed decisions when selecting transformers or measuring progress of the development of efficient transformers.
4/15/2024