A Careful Examination of Large Language Model Performance on Grade School Arithmetic
2405.00332
8
0
Abstract
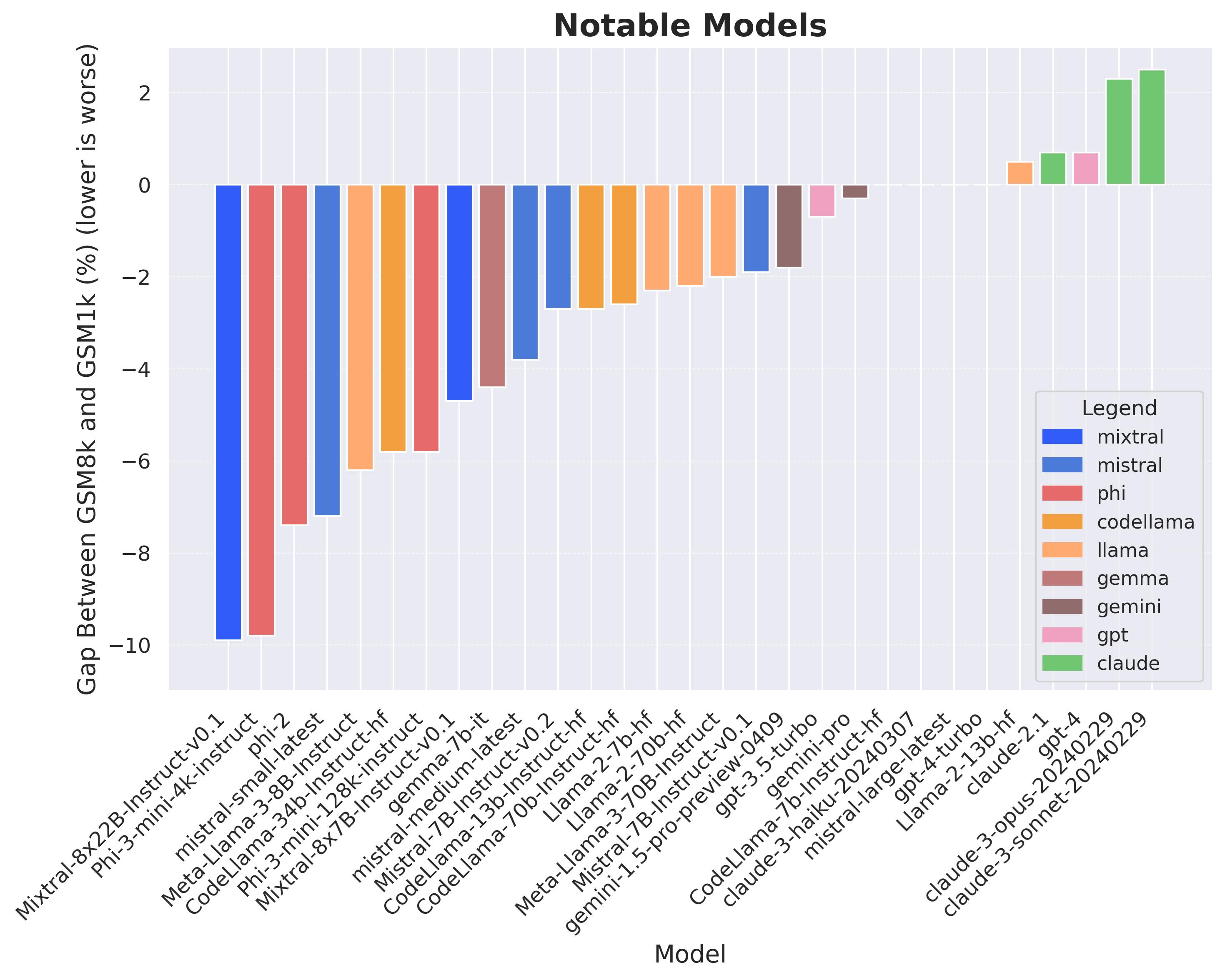
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
Get summaries of the top AI research delivered straight to your inbox:
Related Work
A Careful Examination of Large Language Model Performance on Grade School Arithmetic
This paper examines the performance of large language models (LLMs) on grade school-level arithmetic tasks. The authors investigate whether these advanced AI systems can reliably solve basic math problems that are typically mastered by young students.
The researchers note that while LLMs have shown impressive capabilities in natural language processing, their ability to reason about and solve mathematical problems has received less attention. They cite several <a href="https://aimodels.fyi/papers/arxiv/mathify-evaluating-large-language-models-mathematical-problem">recent studies</a> that have looked at LLM performance on more complex mathematical tasks, but suggest that a closer examination of fundamental arithmetic skills is warranted.
The paper also discusses <a href="https://aimodels.fyi/papers/arxiv/can-large-language-models-put-2-2">prior work</a> that has investigated LLM capabilities in basic arithmetic, while <a href="https://aimodels.fyi/papers/arxiv/large-language-models-mathematical-reasoning-progresses-challenges">other research</a> has explored the challenges and limitations of using LLMs for mathematical reasoning. Additionally, the authors note <a href="https://aimodels.fyi/papers/arxiv/large-language-models-mathematicians">research examining</a> how LLMs compare to human mathematicians on various tasks.
Finally, the paper cites a <a href="https://aimodels.fyi/papers/arxiv/patch-psychometrics-assisted-benchmarking-large-language-models">recent benchmarking study</a> that used psychometric techniques to assess LLM performance across a range of cognitive domains, including mathematics.
Plain English Explanation
This research paper investigates how well large language models (LLMs) - advanced AI systems that can process and generate human-like text - perform on basic math problems typically taught in elementary school. While LLMs have shown impressive skills in natural language tasks, the authors wanted to specifically examine their abilities in fundamental arithmetic, such as addition, subtraction, multiplication, and division.
The researchers note that while some previous studies have looked at LLM performance on more complex mathematical problems, there hasn't been as much focus on these core, grade school-level math skills. They argue that understanding how LLMs handle basic arithmetic is an important step in evaluating their mathematical reasoning capabilities.
The paper discusses related research that has explored LLM abilities in areas like simple arithmetic calculations, as well as studies that have identified challenges and limitations in using these models for advanced mathematical tasks. The authors also mention work that has compared LLM performance to that of human mathematicians on various problems.
Overall, the goal of this study is to take a close, careful look at how well LLMs can solve the kind of straightforward math problems that young students are expected to master. The findings could provide valuable insights into the current state of AI's mathematical abilities and help guide future developments in this area.
Technical Explanation
The paper presents a comprehensive evaluation of large language model (LLM) performance on a range of grade school-level arithmetic tasks. The authors assembled a dataset of over 10,000 math problems covering addition, subtraction, multiplication, and division, with difficulties ranging from single-digit to multi-digit operations.
Several prominent LLMs, including GPT-3, Megatron-LM, and PaLM, were tested on this arithmetic benchmark. The models were given the math problems as text inputs and asked to provide the correct numerical answers. The researchers analyzed the models' overall accuracy, as well as their performance on different problem types and levels of complexity.
The results showed that while the LLMs were generally able to solve the simpler, single-digit arithmetic problems with high accuracy, their performance degraded significantly on more complex, multi-digit operations. The authors also observed interesting patterns, such as the models having more difficulty with division tasks compared to other basic arithmetic.
To better understand the models' reasoning processes, the researchers conducted qualitative analyses, examining the step-by-step solutions generated by the LLMs. This provided insights into the strategies and approaches the models used to tackle the math problems.
The paper also discusses potential factors that may contribute to the LLMs' arithmetic limitations, such as the models' training data and architectures. The authors suggest that further research is needed to enhance LLMs' mathematical reasoning capabilities and better align them with human-level performance on these fundamental skills.
Critical Analysis
The paper provides a valuable contribution to the ongoing research on the mathematical abilities of large language models (LLMs). By focusing on grade school-level arithmetic, the authors have identified important limitations in the current state of these advanced AI systems.
One key strength of the study is its systematic and comprehensive approach. The researchers assembled a diverse dataset of arithmetic problems, covering a range of difficulties and operation types. This allowed them to thoroughly assess the LLMs' performance and gain a nuanced understanding of their strengths and weaknesses.
The findings that LLMs struggle with more complex, multi-digit arithmetic operations are particularly noteworthy. While these models have demonstrated impressive capabilities in natural language processing, the paper highlights the need for significant advancements in their mathematical reasoning abilities to match human-level proficiency in fundamental skills.
However, the study also raises questions about the generalizability of the results. The authors acknowledge that the specific LLMs and dataset used may not fully represent the broader landscape of language models and arithmetic tasks. Further research involving a wider range of models and problem types could provide a more comprehensive picture.
Additionally, the paper does not delve deeply into the underlying reasons for the LLMs' limitations. While the authors suggest potential factors, such as training data and model architectures, a more detailed analysis of the models' internal reasoning processes could yield additional insights that could guide future improvements.
Overall, this paper serves as an important benchmark for assessing the current state of LLM mathematical abilities and highlights the need for continued advancements in this area. The findings challenge the narrative of LLMs as "general-purpose" AI systems and underscore the complexities involved in developing models that can truly excel at a wide range of cognitive tasks, including fundamental mathematics.
Conclusion
This research paper presents a detailed examination of the performance of large language models (LLMs) on grade school-level arithmetic tasks. The authors' systematic evaluation of several prominent LLMs, including GPT-3, Megatron-LM, and PaLM, on a diverse dataset of addition, subtraction, multiplication, and division problems, reveals significant limitations in the models' ability to handle more complex, multi-digit math operations.
While the LLMs demonstrated relatively high accuracy on simpler, single-digit arithmetic, their performance deteriorated as the problem difficulty increased. This suggests that despite their impressive natural language processing capabilities, current LLMs still struggle to match human-level proficiency in fundamental mathematical reasoning.
The findings of this study challenge the notion of LLMs as "general-purpose" AI systems and highlight the need for continued research and development to enhance their mathematical abilities. Understanding the factors that contribute to these limitations, such as training data and model architectures, could inform strategies for improving LLMs' mathematical reasoning skills.
Overall, this paper provides a valuable benchmark for assessing the state of the art in large language model performance on basic arithmetic tasks. The insights gained from this research can help guide future advancements in AI systems, with the ultimate goal of developing models that can seamlessly integrate natural language understanding with robust mathematical capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
Owen Henkel, Adam Boxer, Libby Hills, Bill Roberts
0
0
This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
5/7/2024
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
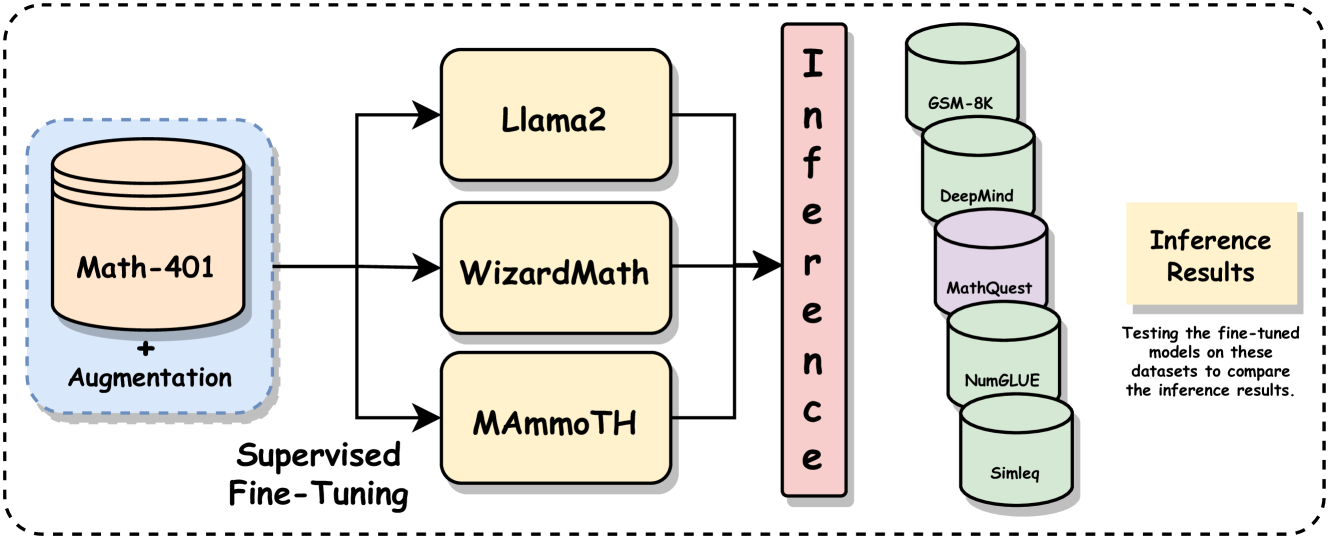
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024

MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, Weiyang Liu
0
0
Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problem due to the complex reasoning procedures. To bridge this gap, we propose MetaMath, a fine-tuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives without extra knowledge, which results in a new dataset called MetaMathQA. Then we fine-tune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning demonstrate that MetaMath outperforms a suite of open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.4% on GSM8K and 19.4% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release all the MetaMathQA dataset, the MetaMath models with different model sizes and the training code for public use.
5/6/2024
💬
Can Large Language Models put 2 and 2 together? Probing for Entailed Arithmetical Relationships
D. Panas, S. Seth, V. Belle
0
0
Two major areas of interest in the era of Large Language Models regard questions of what do LLMs know, and if and how they may be able to reason (or rather, approximately reason). Since to date these lines of work progressed largely in parallel (with notable exceptions), we are interested in investigating the intersection: probing for reasoning about the implicitly-held knowledge. Suspecting the performance to be lacking in this area, we use a very simple set-up of comparisons between cardinalities associated with elements of various subjects (e.g. the number of legs a bird has versus the number of wheels on a tricycle). We empirically demonstrate that although LLMs make steady progress in knowledge acquisition and (pseudo)reasoning with each new GPT release, their capabilities are limited to statistical inference only. It is difficult to argue that pure statistical learning can cope with the combinatorial explosion inherent in many commonsense reasoning tasks, especially once arithmetical notions are involved. Further, we argue that bigger is not always better and chasing purely statistical improvements is flawed at the core, since it only exacerbates the dangerous conflation of the production of correct answers with genuine reasoning ability.
5/1/2024